![]()
Introduction
This book contains our training material, divided up into individual slide decks. Each deck is a lesson. Those lessons combine to form a module, which is taught during a series of sessions within a training. See the glossary for more details.
This is the book version of our material. You can also see the lessons in slide form at https://rust-training.ferrous-systems.com/latest/slides.
We have a standard grouping of lessons into modules, but this can be customised according to customer needs. The modules have dependencies - that is, pre-requisite knowledge required to get the most out of a particular module. The dependencies are shown in the following graphic.
Most of our modules are available now (shown in green), but some are still in development and will be available in the future (shown in grey). We also have stand-alone courses (shown in blue).
Ferrous Systems’ Rust Training Modules
Our training courses have the following dependencies, in terms of content we can assume at least some knowledge of:
- Why Rust?: A (stand-alone) half-day tour of Rust for decision-makers, technical leads and managers.
- Why Ferrocene?: A (stand-alone) 60 minute introduction to Ferrocene.
- Rust Fundamentals: Covers the basics - types, writing functions, using iterators.
- Applied Rust: Using Rust with Windows, macOS or Linux.
- Advanced Rust: Deep-dives into specific topics.
- No-Std Rust: Rust without the Standard Library.
- Bare-Metal Rust: Rust on a microcontroller.
- Async Rust: Futures, Polling, Tokio, and all that jazz.
- Rust and WebAssembly: Using Rust to build WASM binaries, run in a sandbox or in an HTML page
- Ferrocene: Working with our qualified toolchain.
- Using Embassy: Async-Rust on a microcontroller.
Glossary
These are some of the terms we will be using throughout our training.
| Term | Definition |
|---|---|
| Training half-day | 4 hour block of training |
| Training day | 8 hour block of training (only for non-remote trainings) |
| Lesson | One set of slides on a particular topic |
| Session | A block of content between breaks |
| Exercises | Mini Rust projects to be completed during the training |
| Module | Block of consecutive sessions on a fixed set of subject(s), can have different lengths |
| Training | Consists of different modules over a series of days or half-days |
| Wash-up | Last 15 minutes of a training day or half-day for recap, open questions, outlook for next day |
| Opening | First 15 minutes of a training day or half-day, with an ice-breaker and recaps, day’s plan |
| Quizzes | Mini-tests of the training material |
| Ice Breakers | Brief warm-up activities to get the training started, usually short Questions |
| Training Material | These training materials |
Overview
fn main() {
let random_number = generate_random_number();
let mut my_choice = 10;
my_choice += random_number;
println!("{my_choice}");
}
fn generate_random_number() -> i32 {
4 // chosen by dice roll, guaranteed to be random
}What is Rust?
Rust is an empathic systems programming language that is determined to not let you shoot yourself in the foot.
A Little Bit of History
- Rust began around 2006
- An experimental project by Graydon Hoare
- Adopted by Mozilla
- Presented to the general public as version 0.4 in 2012
- Looked a bit Go-like back then
Focus
- Rust lost many features leading up to 1.0:
- Garbage collector
- evented runtime
- complex error handling
~Tsyntax
- Orientation towards a usable systems programming language
Development
- Always together with a larger project (e.g. Servo)
- Early adoption of regular releases, deprecations and an RFC process
Release Method
- Nightly releases
- experimental features are only present on nightly releases
- Every 6 weeks, the current nightly is promoted to beta
- After 6 weeks of testing, beta becomes stable
- Guaranteed backwards-compatibility
- Makes small iterations easier
Note:
- Cargo’s “stabilization” section https://doc.crates.io/contrib/process/unstable.html#stabilization
- Crater tool
- Editions
Goals
- Explicit over implicit
- Predictable runtime behaviour
- Supporting stable software development for programming at large
- Pragmatism and easy integration
- Approachable project
Many examples in this course are very small, which is why we will also spend time discussing the impact of many features on large projects.
The Three Words
- Safety
- Performance
- Productivity
Safety
- Rust is memory-safe and thread-safe
- Buffer overflows, use-after-free, double free: all impossible
- Unless you tell the compiler you know what you’re doing
- De-allocation is automated
- Great for files, mutexes, sockets, etc
Performance
- These properties are guaranteed at compile time and have no runtime cost!
- Optimizing compiler based on LLVM
- Features with runtime cost are explicit and hard to activate “by accident”
- Zero-cost abstractions
- Use threads with confidence
Productivity
- User-focused tooling
- Comes with a build-system, dependency manager, formatter, etc
- Compiler gives helpful error messages
- FFI support to interface with existing systems
Where do Rustaceans come from?
From diverse backgrounds:
- Dynamic languages (JS, Rubyists and Pythonistas)
- Functional languages like Haskell and Scala
- C/C++
- Safety critical systems
Installation
Rustup
Rustup installs and manages Rust compiler toolchains
https://rust-lang.org/tools/install
It is not the Rust compiler!
Important commands
# Installation of a toolchain (here: the stable release channel)
rustup install stable
# Selection of a default toolchain
rustup default stable
# Display documentation in browser
rustup doc [--std]
# Override the default toolchain in your directory
rustup override set stable
# List supported targets
rustup target list
# Add and install a target to the toolchain (here: to cross-compile for an ARMv6-M target)
rustup target add thumbv6m-none-eabi
For up-to-date information, please see Rust Component History
Contents of the toolchain
Hello, world! with Cargo
$ cargo new hello-world
$ cd hello-world
$ cat src/main.rs
fn main() {
println!("Hello, world!");
}
$ cargo build
Compiling hello-world v0.1.0 (file:///Users/skade/Code/rust/scratchpad/hello-world)
Finished debug [unoptimized + debuginfo] target(s) in 0.35 secs
$ cargo run
Finished debug [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello-world`
Hello, world!
A Little Look Around
- What is in Cargo.toml?
- What is in Cargo.lock?
For details, check the Cargo Manifest docs.
IDEs
- rust-analyzer: https://rust-analyzer.github.io
- Implements the Language Server Protocol
- Emacs, (neo)vim, Sublime, VS Code, Kate, etc…
- Now the official VS Code extension for Rust!
- Open Source, funded by donations
- JetBrains Rust IDE: RustRover
- JetBrains Rust plugin for their other IDEs (CLion, Idea, etc.): https://www.jetbrains.com/rust/
Basic Types
The Basics
fn main() {
let x = 10;
let y = process(x);
println!("{x} {y}");
}
fn process(param1: i32) -> i32 {
param1 + 1
}Integers
Rust comes with all standard int types, with and without sign
i8,u8i16,u16i32,u32i64,u64i128,u128
Kinds of variable
#![allow(unused)]
fn main() {
static X: i32 = 42;
const Y: i32 = 42;
fn some_function() {
let x = 42;
let x: i32 = 42;
let mut x = 42;
let mut x: i32 = 42;
}
}
For constants and statics, the type always needs to be specified.
Note:
The expression used to initialise a static or const must be evaluatable at compile time. This includes calling const fn functions. A let binding doesn’t have this restriction.
The static occupies some memory at run-time and get a symbol in the symbol table. The const does not, and is only used to initialise other values (or e.g. as an argument to a function) - it acts a bit like a C pre-processor macro.
Syntactic clarity in specifying numbers
#![allow(unused)]
fn main() {
let x = 123_456; // underscore as separator
let x = 0x12; // prefix 0x to indicate hex value
let x = 0o23; // prefix 0o to indicate octal value
let x = 0b0001; // prefix 0b to indicate binary value
let x = b'a'; // A single u8
}Architecture-dependent Numbers
Rust comes with two architecture-dependent number types:
isize,usize
Casts
Casts between number are possible, also shortening casts:
fn main() {
let foo = 3_i64;
let bar = foo as i32;
}If the size isn’t given, or cannot be inferred, ints default to i32.
Overflows
Overflows trigger a trap in Debug mode, but not in release mode. This behaviour can be configured.
Floats
Rust also comes with floats of all standard sizes: f32, f64
fn main() {
let float: f64 = 1.0;
}Boolean
bool in Rust is represented by either of two values: true or
false
Character
char is a Unicode Scalar Value being represented as a “single character”
- A literal in single quotes:
'r'or'\u{0072}' - Exactly four (4) bytes in size
- More than just ASCII: glyphs, emoji, accented characters, etc.
Note:
- Unicode Scalar Values can be represented by:
- one 32-bit code unit (UTF-32)
- one or two 16-bit code units (UTF-16), or
- up to four 8-bit bytes (UTF-8)
Character Literals
fn main() {
// U+0072 LATIN SMALL LETTER R
let c1 = 'r';
// U+03BC GREEK SMALL LETTER MU
let c2 = 'μ';
// U+0154 LATIN CAPITAL LETTER R WITH ACUTE
let c3 = '\u{0154}';
// U+1F60E SMILING FACE WITH SUNGLASSES
let c4 = '😎';
}Character Literals
fn main() {
// U+1F468 U+200D U+1F469 U+200D U+1F467 U+200D U+1F467
let seven_chars_emoji = '👨👩👧👧'; // Error: char must be one codepoint long
}Note:
As we can see, glyphs can be comprised of more than one Unicode Scalar Value. That needs to be stored as a string (String or &str), not a char.
Arrays
- Arrays have multiple elements of the same type.
- They are of fixed size (it’s part of the type).
fn main() {
let arr: [i32; 4] = [1, 2, 3, 4];
let arr2 = [1, 2, 3, 4];
let arr3 = ['😎'; 8];
}Slices
- Slices are like arrays, but with a run-time specified size.
- Slices carry a pointer to some other array, and a length.
- Slices cannot be resized but can be subsliced.
fn main() {
let slice: &[i32] = &[1, 2, 3, 4];
let sub: &[i32] = &slice[0..1];
}Note:
- Use
.get()method on the slice to avoid panics instead of accessing via index. - The range syntax include the first value but excludes the last value. Use
0..=1to include both ends.
String Slices
- Strings Slices (
&str) are a special kind of&[u8] - They are guaranteed to be a valid UTF-8 encoded Unicode string
- It is undefined behaviour to create one that isn’t valid UTF-8
- Slicing must be done on character boundaries
fn main() {
let hello_world: &str = "Hello 😀";
println!("Start = {}", &hello_world[0..5]);
// println!("End = {}", &hello_world[7..]);
}Note:
- Use
std::str::from_utf8to make an&strfrom a&[u8] - Let trainees know that Strings are covered over many slides in the training and that an
Advanced Stringsslides exist for completeness’ sake
Control Flow
Control Flow primitives
ifexpressionsloopandwhileloopsmatchexpressionsforloopsbreakandcontinuereturnand?
Using if as a statement
- Tests if a boolean expression is
true - Parentheses around the conditional are not necessary
- Blocks need brackets, no shorthand
fn main() {
if 1 == 2 {
println!("integers are broken");
} else if 'a' == 'b' {
println!("characters are broken");
} else {
println!("that's what I thought");
}
}Using if as an expression
- Every block is an expression
- Note the final
;to terminate theletstatement.
fn main() {
let x = if 1 == 2 {
100
} else if 'a' == 'b' {
200
} else {
300
};
}Using if as the final expression
Now the if expression is the result of the function:
#![allow(unused)]
fn main() {
fn some_function() -> i32 {
if 1 == 2 {
100
} else if 'a' == 'b' {
200
} else {
300
}
}
}Looping with loop
loop is used for (potentially) infinite loops
fn main() {
let mut i = 0;
loop {
i += 1;
if i > 100 { break; }
}
}Looping with loop
loop blocks are also expressions…
fn main() {
let mut i = 0;
let loop_result = loop {
i += 1;
if i > 10 { break 6; }
println!("i = {}", i);
};
println!("loop_result = {}", loop_result);
}while
whileis used for conditional loops.- Loops while the boolean expression is
true
fn main() {
let mut i = 0;
while i < 10 {
i += 1;
println!("i = {}", i);
}
}Control Flow with match
- The
matchkeyword does pattern matching - You can use it a bit like an
if/else if/elseexpression - The first arm to match, wins
_means match anything
fn main() {
let a = 4;
match a % 3 {
0 => { println!("divisible by 3") }
_ => { println!("not divisible by 3") }
}
}for loops
foris used for iteration- Here
0..10creates aRange, which you can iterate
fn main() {
for num in 0..10 {
println!("{}", num);
}
}for loops
Lots of things are iterable
fn main() {
for ch in "Hello".chars() {
println!("{}", ch);
}
}for under the hood
- What Rust actually does is more like…
- (More on this in the section on Iterators)
fn main() {
let mut iter = "Hello".chars().into_iter();
loop {
match iter.next() {
Some(ch) => println!("{}", ch),
None => break,
}
}
}Break labels
If you have nested loops, you can label them to indicate which one you want to break out of.
fn main() {
'cols: for x in 0..5 {
'rows: for y in 0..5 {
println!("x = {}, y = {}", x, y);
if x + y >= 6 {
break 'cols;
}
}
}
}Continue
Means go around the loop again, rather than break out of the loop
fn main() {
'cols: for x in 0..5 {
'rows: for y in 0..5 {
println!("x = {}, y = {}", x, y);
if x + y >= 4 {
continue 'cols;
}
}
}
}return
returncan be used for early returns- The result of the last expression of a function is always returned
#![allow(unused)]
fn main() {
fn get_number(x: bool) -> i32 {
if x {
return 42;
}
-1
}
}?
- Used for more ergonomic error handling.
- Return the error if the result of an operation is an error, otherwise continue.
fn main() -> std::io::Result<()> {
let file = std::fs::File::open("file.txt")?;
// If file was opened successfully, do something with it.
// (...)
Ok(())
}Compound Types
Structs
A struct groups and names data of different types.
Definition
#![allow(unused)]
fn main() {
struct Point {
x: i32,
y: i32,
}
}Note:
The fields may not be laid out in memory in the order they are written (unless you ask the compiler to ensure that they are).
Construction
- there is no partial initialization
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 1, y: 2 };
}Construction
- but you can copy from an existing variable of the same type
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 1, y: 2 };
let q = Point { x: 4, ..p };
}Field Access
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 1, y: 2 };
println!("{}", p.x);
println!("{}", p.y);
}Tuples
- Holds values of different types together.
- Like an anonymous
struct, with fields numbered 0, 1, etc.
fn main() {
let p = (1, 2);
println!("{}", p.0);
println!("{}", p.1);
}()
- the empty tuple
- represents the absence of data
- we often use this similarly to how you’d use
voidin C
#![allow(unused)]
fn main() {
fn prints_but_returns_nothing(data: &str) -> () {
println!("passed string: {}", data);
}
}Tuple Structs
- Like a
struct, with fields numbered 0, 1, etc.
struct Point(i32,i32);
fn main() {
let p = Point(1, 2);
println!("{}", p.0);
println!("{}", p.1);
}Enums
- An
enumrepresents different variations of the same subject. - The different choices in an enum are called variants
enum: Definition and Construction
enum Shape {
Square,
Circle,
Rectangle,
Triangle,
}
fn main() {
let shape = Shape::Rectangle;
}Enums with Values
enum Shape {
Dot,
Square(u32),
Rectangle { width: u32, length: u32 }
}
fn main() {
let dot = Shape::Dot;
let square = Shape::Square(10);
let rectangle = Shape::Rectangle { width: 10, length: 20 };
}Enums with Values
- An enum value is the same size, no matter which variant is picked
- It will be the size of the largest variant (plus a tag)
Note:
- From a computer science perspective,
enums are tagged unions. - The tag in an enum specifies which variant is currently valid, and is stored as the smallest integer the compiler can get away with - it depends how many variants you have. Of course, if none of the variants have any data, the enum is just the tag.
- If you have a C background, you can think of this as being a
structcontaining anintand aunion.
Doing a match on an enum
- When an
enumhas variants, you usematchto extract the data - New variables are created from the pattern (e.g.
radius)
#![allow(unused)]
fn main() {
enum Shape {
Dot,
Square(u32),
Rectangle { width: u32, length: u32 }
}
fn check_shape(shape: Shape) {
match shape {
Shape::Square(width) => {
println!("It's a square, with the width {}", width);
}
_ => {
println!("Try a square instead");
}
}
}
}Doing a match on an enum
- There are two variables called
width - The binding of
widthin the pattern on line 10 hides thewidthvariable on line 8
#![allow(unused)]
fn main() {
enum Shape {
Dot,
Square(u32),
Rectangle { width: u32, length: u32 }
}
fn check_shape(shape: Shape) {
let width = 10;
match shape {
Shape::Square(width) => {
println!("It's a square, with width {}", width);
}
_ => {
println!("Try a square instead");
}
}
}
}Note:
- Rust allows the variable shadowing shown above in general
Match guards
Match guards allow further refining of a match
#![allow(unused)]
fn main() {
enum Shape {
Dot,
Square(u32),
Rectangle { width: u32, length: u32 }
}
fn check_shape(shape: Shape) {
match shape {
Shape::Square(width) if width > 10 => {
println!("It's a BIG square, with width {}", width);
}
_ => {
println!("Try a big square instead");
}
}
}
}Combining patterns
- You can use the
|operator to join patterns together
#![allow(unused)]
fn main() {
enum Shape {
Dot,
Square(u32),
Rectangle { width: u32, length: u32 }
}
fn test_shape(shape: Shape) {
match shape {
Shape::Rectangle { width, .. } | Shape::Square(width) => {
println!("Shape has a width of {}", width);
}
_ => {
println!("Not a rectangle, nor a square");
}
}
}
}Shorthand: if let conditionals
- You can use
if letif only one case is of interest. - Still pattern matching
#![allow(unused)]
fn main() {
enum Shape {
Dot,
Square(u32),
Rectangle { width: u32, length: u32 }
}
fn test_shape(shape: Shape) {
if let Shape::Square(width) = shape {
println!("Shape is a Square with width {}", width);
}
}
}if let chains in newer Rust versions
Newer Rust versions (edition 2024) allow if let chaining, for example:
enum Shape {
Circle(i32),
Rectangle(i32, i32),
}
fn test_shape(shape: Shape) {
// Hardcoded here, but could be determined by other logic.
let ignore_rectangle = true;
if !ignore_rectangle && let Shape::Rectangle(length, height) = shape {
println!("Shape is a Rectangle with {length} x {height}");
}
}Shorthand: let else conditionals
- If you expect it to match, but want to handle the error…
- The
elseblock must diverge
#![allow(unused)]
fn main() {
enum Shape {
Dot,
Square(u32),
Rectangle { width: u32, length: u32 }
}
fn test_shape(shape: Shape) {
let Shape::Square(width) = shape else {
println!("I only like squares");
return;
};
println!("Shape is a square with width {}", width);
}
}Shorthand: while let conditionals
- Keep looping whilst the pattern still matches
enum Shape {
Dot,
Square(u32),
Rectangle { width: u32, length: u32 }
}
fn main() {
while let Shape::Square(width) = make_shape() {
println!("got square, width {}", width);
}
}
fn make_shape() -> Shape {
todo!()
}Foreshadowing! 👻
Two very important enums
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
enum Result<T, E> {
Ok(T),
Err(E)
}
}We’ll come back to them after we learn about error handling.
Ownership and Borrowing
Ownership
Ownership is the basis for the memory management of Rust.
Rules
- Every value has exactly one owner
- Ownership can be passed on, both to functions and other types
- The owner is responsible for removing the data from memory
- The owner always has full control over the data and can mutate it
These Rules are
- fundamental to Rust’s type system
- enforced at compile time
- important for optimizations
Example
fn main() {
let s = String::from("Hello 😀");
print_string(s);
// s cannot be used any more - you gave it away
}
fn print_string(s: String) {
println!("The string is {s}")
}Note:
The statement let s = ...; introduces a variable binding called s and gives it a value which is of type String. This distinction is important when it comes to transferring ownership.
The function String::from is an associated function called from on the String type.
The println! call is a macro, which is how we are able to do to Python-style {} string interpolation.
Does this compile?
fn main() {
let s = String::from("Hello 😀");
print_string(s);
print_string(s);
}
fn print_string(s: String) {
println!("The string is {s}")
}It does not!
error[E0382]: use of moved value: `s`
--> src/main.rs:4:18
|
2 | let s = String::from("Hello 😀");
| - move occurs because `s` has type `String`, which does not implement the `Copy` trait
3 | print_string(s);
| - value moved here
4 | print_string(s);
| ^ value used here after move
|
note: consider changing this parameter type in function `print_string` to borrow instead if owning the value isn't necessary
--> src/main.rs:7:20
|
7 | fn print_string(s: String) {
| ------------ ^^^^^^ this parameter takes ownership of the value
| |
| in this function
help: consider cloning the value if the performance cost is acceptable
|
3 | print_string(s.clone());
| ++++++++
For more information about this error, try `rustc --explain E0382`.
Background
- When calling
print_stringwiths, the value insis transferred into the arguments ofprint_string. - At that moment, ownership passes to
print_string. We say the function consumed the value. - The variable binding
sceases to exist, and thusmainis not allowed to access it any more.
Mutability
- The variable binding can be immutable (the default) or mutable.
- If you own it, you can rebind it and change this.
fn main() {
let x = 6;
// x += 1; ❌
let mut x = x;
x += 1; // ✅
}Borrowing
- Transferring ownership back and forth would get tiresome.
- We can let other functions borrow the values we own.
- The outcome of a borrow is a reference
- There are two kinds of reference - Shared/Immutable and Exclusive/Mutable
Shared References
- Also called an immutable reference.
- Use the
&operator to borrow (i.e. to make a reference). - It’s like a C pointer but with special compile-time checks.
- Rust also allows type-conversion functions to be called when you take a reference.
Note:
C pointers are convertible to/from integers. Rust references are not, and Rust pointers may or may not be, depending on what they point at.
Making a Reference
fn main() {
let s = String::from("Hello 😀");
// A reference to a String
let _string_ref: &String = &s;
// The special string-slice type (could also be a reference
// to a string literal)
let _string_slice: &str = &s;
}Note:
The _ prefix just stops a warning about us not using the variable.
Taking a Reference
- We can also say a function takes a reference
- We use a type like
&SomeType:
#![allow(unused)]
fn main() {
fn print_string(s: &String) {
println!("The string is {s}")
}
}Full Example
fn main() {
let s = String::from("Hello 😀");
print_string(&s);
print_string(&s);
}
fn print_string(s: &String) {
println!("The string is {s}")
}Exclusive References
- Also called a mutable reference
- Use the
&mutoperator to borrow (i.e. to make a reference) - Even stricter rules than the
&references - Only a mutable binding can make a mutable reference
Exclusive Reference Rules
- Must be only one exclusive reference to an object at any one time
- Cannot have shared and exclusive references alive at the same time
- => the compiler knows an
&mutreference cannot alias anything
Rust forbids shared mutability
Making an Exclusive Reference
fn main() {
let mut s = String::from("Hello 😀");
let s_ref = &mut s;
}Note:
The binding for s now has to be mutable, otherwise we can’t take a mutable reference to it.
Taking an Exclusive Reference
- We can also say a function takes an exclusive reference
- We use a type like
&mut SomeType:
#![allow(unused)]
fn main() {
fn add_excitement(s: &mut String) {
s.push_str("!");
}
}Full Example
fn main() {
let mut s = String::from("Hello 😀");
add_excitement(&mut s);
println!("The string is {s}");
}
fn add_excitement(s: &mut String) {
s.push_str("!");
}Note:
Try adding more excitement by calling add_excitement multiple times.
A Summary
| Borrowed | Mutably Borrowed | Owned | |
|---|---|---|---|
Type T | &T | &mut T | T |
Type i32 | &i32 | &mut i32 | i32 |
Type String | &String or &str | &mut String | String |
- Mutably Borrowing gives more permissions than Borrowing
- Owning gives more permissions than Mutably Borrowing
Note:
Why are there two types of Borrowed string types (&String and &str)? The first is a reference to a struct (std::string::String, specifically), and the latter is a built-in slice type which points at some bytes in memory which are valid UTF-8 encoded characters.
An aside: Method Calls
- Rust supports Method Calls
- The first argument of the method is either
self,&selfor&mut self - They are converted to function calls by the compiler
fn main() {
let mut s = String::from("Hello 😀");
// This method call...
s.push_str("!!");
// is the same as...
// String::push_str(&mut s, "!!");
println!("The string is {s}");
}Note:
We use Type::function() for associated functions, and variable.method() for method calls, which are just Type::method(&variable) or Type::method(&mut variable), or Type::method(variable), depending on how the method was declared).
Avoiding Borrowing
If you want to give a function their own object, and keeps yours separate, you have two choices:
- Clone
- Copy
Clone
Some types have a .clone() method.
It makes a new object, which looks just like the original object.
fn main() {
let s = String::from("Hello 😀");
let mut s_clone = s.clone();
s_clone.push_str("!!");
println!("s = {s}");
println!("s_clone = {s_clone}");
}Making things Cloneable
You can mark your struct or enum with #[derive(Clone)]
(But only if every value in your struct/enum itself is Clone)
#[derive(Clone)]
struct Square {
width: i32
}
fn main() {
let sq = Square { width: 10 };
let sq2 = sq.clone();
}Copy
- Some types, like integers and floats, are
Copy - Compiler copies these objects automatically
- If cloning is very cheap, you could make your type
Copy
fn main() {
let x = 6;
do_stuff(x);
do_stuff(x);
}
fn do_stuff(x: i32) {
println!("Do I own x, with value {x}?");
}Note:
If your type represents ownership of something, like a File, or a DatabaseRecord, you probably don’t want to make it Copy!
Cleaning up
A value is cleaned up when its owner goes out of scope.
We call this dropping the value.
Custom Cleaning
You can define a specific behaviour to happen on drop using the Drop trait (cf. std::ops::Drop).
For example, the memory used by a String is freed when dropped:
fn main() {
// String created here (some memory is allocated on the heap)
let s = String::from("Hello 😀");
} // String `s` is dropped here and heap memory is freedMore drop implementations:
MutexGuardunlocks the appropriateMutexwhen droppedFilecloses the file handle when droppedTcpStreamcloses the connection when droppedThreaddetaches the thread when dropped- etc…
Error Handling
There are no exceptions
Rust has two ways of indicating errors:
- Returning a value
- Panicking
Returning a value
fn parse_header(data: &str) -> bool {
if !data.starts_with("HEADER: ") {
return false;
}
true
}It would be nice if we could return data as well as ok, or error…
Foretold enums strike back! 🤯
Remember these? They are very important in Rust.
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
enum Result<T, E> {
Ok(T),
Err(E)
}
}
For now, think of T and E as placeholders for your own types. These are also called
generics and there will be a dedicated chapter for them.
I can’t find it
If you have an function where one outcome is “can’t find it”, we use Option:
#![allow(unused)]
fn main() {
fn parse_header(data: &str) -> Option<&str> {
if !data.starts_with("HEADER: ") {
return None;
}
Some(&data[8..])
}
}Note:
It’s so important, it is special-cased within the compiler so you can say None instead of Option::None, as you would with any other enum.
That’s gone a bit wrong
When the result of a function is either Ok, or some Error value, we use Result:
#![allow(unused)]
fn main() {
enum MyError {
BadHeader
}
// Need to describe both the Ok type and the Err type here:
fn parse_header(data: &str) -> Result<&str, MyError> {
if !data.starts_with("HEADER: ") {
return Err(MyError::BadHeader);
}
Ok(&data[8..])
}
}Note:
It’s so important, it is special-cased within the compiler so you can say Ok and Err instead of Result::Ok and Result::Err, as you would with any other enum.
Handling Results by hand
You can handle Result like any other enum:
#![allow(unused)]
fn main() {
use std::io::prelude::*;
fn read_file(filename: &str) -> Result<String, std::io::Error> {
let mut file = match std::fs::File::open(filename) {
Ok(f) => f,
Err(e) => {
return Err(e);
}
};
let mut contents = String::new();
if let Err(e) = file.read_to_string(&mut contents) {
return Err(e);
}
Ok(contents)
}
}Handling Results with ?
It is idiomatic Rust to use ? to let the caller handle errors while continuing
for the regular happy path.
#![allow(unused)]
fn main() {
use std::io::prelude::*;
fn read_file(filename: &str) -> Result<String, std::io::Error> {
let mut file = std::fs::File::open(filename)?;
let mut contents = String::new();
file.read_to_string(&mut contents)?;
Ok(contents)
}
}Note:
This was added in Rust 1.39.
The ? operator will evaluate to the Ok value if the Result is Ok, and it will cause an early return with the error value if it is Err. It will also call .into() to perform a type conversion if necessary (and if possible).
The ? operator allows exception like behaviour: Errors can be bubbled up, similar to exceptions.
What kind of Error?
You can put anything in for the E in Result<T, E>:
#![allow(unused)]
fn main() {
fn literals() -> Result<(), &'static str> {
Err("oh no")
}
fn strings() -> Result<(), String> {
Err(String::from("oh no"))
}
fn enums() -> Result<(), Error> {
Err(Error::BadThing)
}
enum Error { BadThing, OtherThing }
}Using String Literals as the Err Type
Setting E to be &'static str lets you use "String literals"
- It’s cheap
- It’s expressive
- But you can’t change the text to include some specific value
- And your program can’t tell what kind of error it was
Using Strings as the Err Type
Setting E to be String lets you make up text at run-time:
- It’s expressive
- You can render some values into the
String - But it costs you a heap allocation to store the bytes for the
String - And your program still can’t tell what kind of error it was
Using enums as the Err Type
An enum is ideal to express one of a number of different kinds of thing:
#![allow(unused)]
fn main() {
/// Represents the ways this module can fail
enum Error {
/// An error came from the underlying transport
Io,
/// During an arithmetic operation a result was produced that could not be stored
NumericOverflow,
/// etc
DiskFull,
/// etc
NetworkTimeout,
}
}Enum errors with extra context
An enum can also hold data for each variant:
#![allow(unused)]
fn main() {
/// Represents the ways this module can fail
enum Error {
/// An error came from the underlying transport
Io(std::io::Error),
/// During an arithmetic operation a result was produced that could not
/// be stored
NumericOverflow,
/// Ran out of disk space
DiskFull,
/// Remote system did not respond in time
NetworkTimeout(std::time::Duration),
}
}The std::error::Error trait
- The Standard Library has a
traitthat yourenum Errorshould implement - However, it’s not easy to use
- Many people didn’t bother
- See https://doc.rust-lang.org/std/error/trait.Error.html
Helper Crates
So, people created helper crates like thiserror
use thiserror::Error;
#[derive(Error, Debug)]
pub enum DataStoreError {
#[error("data store disconnected")]
Disconnect(#[from] io::Error),
#[error("the data for key `{0}` is not available")]
Redaction(String),
#[error("invalid header (expected {expected:?}, found {found:?})")]
InvalidHeader { expected: String, found: String },
#[error("unknown data store error")]
Unknown,
}Something universal
Exhaustively listing all the ways your dependencies can fail is hard.
One solution:
fn main() -> Result<(), Box<dyn std::error::Error>> {
let _f = std::fs::File::open("hello.txt")?; // IO Error
let _s = std::str::from_utf8(&[0xFF, 0x65])?; // Unicode conversion error
Ok(())
}Anyhow
The anyhow crate gives you a nicer type:
fn main() -> Result<(), anyhow::Error> {
let _f = std::fs::File::open("hello.txt")?; // IO Error
let _s = std::str::from_utf8(&[0xFF, 0x65])?; // Unicode conversion error
Ok(())
}Note:
- Use
anyhowif you do not care what error type your function returns, just that it captures something. This oftentimes applies to applications. - Use
thiserrorif you must design your own error types but want easyErrortrait impl. This oftentimes applies to libraries.
Result type conversions
#![allow(unused)]
fn main() {
enum ErrorX { Oops };
enum ErrorY { Oops };
fn convert_ok(input: Result<u32, ErrorX>) -> Result<u64, ErrorX> {
input.map(|v| v as u64)
}
fn convert_err(input: Result<u32, ErrorX>) -> Result<u32, ErrorY> {
input.map_err(|e| ErrorY::Oops)
}
}Note:
The |..| ... syntax is a closure - an anonymous inline function, where the function parameters are between the | symbols, and the function body follows. The parameter types and the return type are usually inferred automatically (but you can add them if required).
Convert Result <-> Option
#![allow(unused)]
fn main() {
enum Error { Oops };
fn option_to_result(input: Option<u32>) -> Result<u32, Error> {
input.ok_or(Error::Oops)
}
fn result_to_option(input: Result<u32, Error>) -> Option<u32> {
input.ok()
}
}Replace None or Err(e) with a value
#![allow(unused)]
fn main() {
enum Error { Oops };
fn none_becomes_be_zero(input: Option<u32>) -> u32 {
input.unwrap_or(0)
}
fn error_becomes_zero(input: Result<u32, Error>) -> u32 {
input.unwrap_or(0)
}
}There is more
ResultandOptionhave a lot more methods available!ResultdocumentationOptiondocumentation- These methods can reduce a lot of boilerplate code, especially when
combined with the
FromandIntovalue conversion traits.
Note:
- Example for combining this with
From/Into: Mapping a child error into a parent error can be simply achieved by usingchild_err.map_err(|e| e.into())as long aFrom<ChildError>is implemented forParentError
Panicking
The other way to handle errors is to generate a controlled, program-ending, failure.
- You can
panic!("x too large ({})", x); - You can call an API that panics on error (like indexing, e.g.
s[99]) - You can convert a
Result::Errinto a panic with.unwrap()or.expect("Oh no")
Collections
Using Arrays
Arrays ([T; N]) have a fixed size.
fn main() {
let array = [1, 2, 3, 4, 5];
println!("array = {:?}", array);
}Building the array at runtime.
How do you know how many ‘slots’ you’ve used?
fn main() {
let mut array = [0u8; 10];
for idx in 0..5 {
array[idx] = idx as u8;
}
println!("array = {:?}", array);
}Slices
A view into some other data. Written as &[T] (or &mut [T]).
fn main() {
let mut array = [0u8; 10];
for idx in 0..5 {
array[idx] = idx as u8;
}
let data = &array[0..5];
println!("data = {:?}", data);
}Note: Slices are unsized types and can only be access via a reference. This reference is a ‘fat reference’ because instead of just containing a pointer to the start of the data, it also contains a length value.
Vectors
Vec is a growable, heap-allocated, array-like type.
fn process_data(input: &[u32]) {
let mut vector = Vec::new();
for value in input {
vector.push(value * 2);
}
println!("vector = {:?}, first = {}", vector, vector[0]);
}
fn main() { process_data(&[1, 2, 3]); }Note:
The green block of data is heap allocated.
There’s a macro short-cut too…
fn main() {
let vector = vec![1, 2, 3, 4];
let buffer = vec![0u8; 128];
}Check out the docs!
Features of Vec
- Growable (will re-allocate if needed)
- Can borrow it as a
&[T]slice - Can access any element (
vector[i]) quickly - Can push/pop from the back easily
Downsides of Vec
- Not great for insertion
- Everything must be of the same type
- Indices are always
usize
String Slices
The basic string types in Rust are all UTF-8.
A String Slice (&str) is an immutable view on to some valid UTF-8 bytes
fn main() {
let bytes = [0xC2, 0xA3, 0x39, 0x39, 0x21];
let s = std::str::from_utf8(&bytes).unwrap();
println!("{}", s);
}Note:
A string slice is tied to the lifetime of the data that it refers to.
String Literals
- String Literals produce a string slice “with static lifetime”
- Points at some bytes that live in read-only memory with your code
fn main() {
let s: &'static str = "Hello!";
println!("s = {}", s);
}Note:
The lifetime annotation of 'static just means the string slice lives forever
and never gets destroyed. We wrote out the type in full so you can see it - you
can emit it on variable declarations.
There’s a second string literal in this program. Can you spot it?
(It’s the format string in the call to println!)
Strings (docs)
- A growable collection of
char - Actually stored as a
Vec<u8>, with UTF-8 encoding - You cannot access characters by index (only bytes)
- But you never really want to anyway
fn main() {
let string = String::from("Hello!");
}Note:
The green block of data is heap allocated.
Making a String
fn main() {
let s1 = "String literal up-conversion".to_string();
let s2: String = "Into also works".into();
let s3 = String::from("Or using from");
let s4 = format!("String s1 is {:?}", s1);
let s5 = String::new(); // empty
}Appending to a String
fn main() {
let mut start = "Mary had a ".to_string();
start.push_str("little");
let rhyme = start + " lamb";
println!("rhyme = {}", rhyme);
// println!("start = {}", start);
}Joining pieces of String
fn main() {
let pieces = ["Mary", "had", "a", "little", "lamb"];
let rhyme = pieces.join(" ");
println!("Rhyme = {}", rhyme);
}VecDeque (docs)
A ring-buffer, also known as a Double-Ended Queue:
use std::collections::VecDeque;
fn main() {
let mut queue = VecDeque::new();
queue.push_back(1);
queue.push_back(2);
queue.push_back(3);
println!("first: {:?}", queue.pop_front());
println!("second: {:?}", queue.pop_front());
println!("third: {:?}", queue.pop_front());
}Features of VecDeque
- Growable (will re-allocate if needed)
- Can access any element (
queue[i]) quickly - Can push/pop from the front or back easily
Downsides of VecDeque
- Cannot borrow it as a single
&[T]slice without moving items around - Not great for insertion in the middle
- Everything must be of the same type
- Indices are always
usize
HashMap (docs)
If you want to store Values against Keys, Rust has HashMap<K, V>.
Note that the keys must be all the same type, and the values must be all the same type.
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert("Triangle", 3);
map.insert("Square", 4);
println!("Triangles have {:?} sides", map.get("Triangle"));
println!("Triangles have {:?} sides", map["Triangle"]);
println!("map {:?}", map);
}Note:
The index operation will panic if the key is not found, just like with slices and arrays if the index is out of bounds. Get returns an Option.
If you run it a few times, the result will change because it is un-ordered.
The Entry API
What if you want to update an existing value OR add a new value if it’s not there yet?
HashMap has the Entry API:
enum Entry<K, V> {
Occupied(...),
Vacant(...),
}
fn entry(&mut self, key: K) -> Entry<K, V> {
...
}Entry API Example
use std::collections::HashMap;
fn update_connection(map: &mut HashMap<i32, u64>, id: i32) {
map.entry(id)
.and_modify(|v| *v = *v + 1)
.or_insert(1);
}
fn main() {
let mut map = HashMap::new();
update_connection(&mut map, 100);
update_connection(&mut map, 200);
update_connection(&mut map, 100);
println!("{:?}", map);
}Features of HashMap
- Growable (will re-allocate if needed)
- Can access any element (
map[i]) quickly - Great at insertion
- Can choose the Key and Value types independently
Downsides of HashMap
- Cannot borrow it as a single
&[T]slice - Everything must be of the same type
- Unordered
BTreeMap (docs)
Like a HashMap, but kept in-order.
use std::collections::BTreeMap;
fn main() {
let mut map = BTreeMap::new();
map.insert("Triangle", 3);
map.insert("Square", 4);
println!("Triangles have {:?} sides", map.get("Triangle"));
println!("Triangles have {:?} sides", map["Triangle"]);
println!("map {:?}", map);
}Features of BTreeMap
- Growable (will re-allocate if needed)
- Can access any element (
map[i]) quickly - Great at insertion
- Can choose the Key and Value types independently
- Ordered
Downsides of BTreeMap
- Cannot borrow it as a single
&[T]slice - Everything must be of the same type
- Slower than a
HashMap
Sets
We also have HashSet and BTreeSet.
Just sets the V type parameter to ()!
| Type | Owns | Grow | Index | Slice | Cheap Insert |
|---|---|---|---|---|---|
| Array | ✅ | ❌ | usize | ✅ | ❌ |
| Slice | ❌ | ❌ | usize | ✅ | ❌ |
| Vec | ✅ | ✅ | usize | ✅ | ↩ |
| String Slice | ❌ | ❌ | 🤔 | ✅ | ❌ |
| String | ✅ | ✅ | 🤔 | ✅ | ↩ |
| VecDeque | ✅ | ✅ | usize | 🤔 | ↪ / ↩ |
| HashMap | ✅ | ✅ | T | ❌ | ✅ |
| BTreeMap | ✅ | ✅ | T | ❌ | ✅ |
Note:
The 🤔 for indexing string slices and Strings is because the index is a byte offset and the system will panic if you try and chop a UTF-8 encoded character in half.
The 🤔 for indexing VecDeque is because you might have to get the contents in two pieces (i.e. as two disjoint slices) due to wrap-around.
Technically you can insert into the middle of a Vec or a String, but we’re talking about ‘cheap’ insertions that don’t involve moving too much stuff around.
Iterators
What is Iterating?
iterate (verb): to repeat a process, especially as part of a computer program (Cambridge English Dictionary)
To iterate in Rust is to produce a sequence of items, one at a time.
How do you Iterate?
- With an Iterator
- Commonly
.into_iter(),.iter_mut()or.iter()on some collection - There’s also an
IntoIteratortrait for automatically creating an Iterator
What is an Iterator?
- An object with a
.next()method- The method provides
Some(data), orNoneonce the data has run out - The object holds the iterator’s state
- The method provides
- Some Iterators will take data from a collection (e.g. a Slice)
- Some Iterators will calculate each item on-the-fly
- Some Iterators will take data from another iterator, and then calculate something new
Note:
Technically, all iterators calculate things on-the-fly. Some own another iterator and use that as input to their calculation, and some have an internal state that they can use for calculation. fn next(&mut self) -> Self::Item can only access Self so it is about what Self contains.
struct SomeIter<T> where T: Iterator { inner: T }struct SomeOtherIter { random_seed: u32 }
Important to note
- Iterators are lazy
- Iterators are used all over the Rust Standard Library
- Iterators have hidden complexity that you can mostly ignore
- Iterators cannot be invalidated (unlike, say, C++)
- Some Iterators can wrap other Iterators
Basic usage
- You need to make an iterator
- You need to pump it in a loop
fn main() {
let data = vec![1, 2, 3, 4, 5];
let mut iterator = data.iter();
loop {
if let Some(item) = iterator.next() {
println!("Got {}", item);
} else {
break;
}
}
}Basic usage
Same thing, but with while let.
fn main() {
let data = vec![1, 2, 3, 4, 5];
let mut iterator = data.iter();
while let Some(item) = iterator.next() {
println!("Got {}", item);
}
}Basic usage
Same thing, but with for
fn main() {
let data = vec![1, 2, 3, 4, 5];
// for <variable> in <iterator>
for item in data.iter() {
println!("Got {}", item);
}
}Basic usage
Same thing, but we let for call .into_iter() for us.
fn main() {
let data = vec![1, 2, 3, 4, 5];
// for <variable> in <implements IntoIterator>
for item in &data {
println!("Got {}", item);
}
}Three kinds of Iterator
Three kinds of Iterator
- Borrowed (
data.iter()) - Mutably Borrowed (
data.iter_mut()) - Owned (
data.into_iter())
But how did that for-loop work?
If a for loop calls .into_iter() how did we get a borrowed iterator?
fn main() {
let data = vec![1, 2, 3, 4, 5];
for item in &data {
// item is a &i32
println!("Got {}", item);
}
}But how did that for-loop work?
The & is load-bearing…
fn main() {
let data = vec![1, 2, 3, 4, 5];
let temp = &data;
// This is .into_iter() on a `&Vec` not a `Vec`!
let iter = temp.into_iter();
for item in iter {
println!("Got {}", item);
}
}Note:
IntoIteratoris actually dependent on the context. Depending on the context it will produce an iterator with owned elements, with references to elements, with mutable references to elements.- e.g.
impl<T, A> IntoIterator for Vec<T, A>for owned impl<'a, T, A> IntoIterator for &'a Vec<T, A>for refsimpl<'a, T, A> IntoIterator for &'a mut Vec<T, A>for mut refs
Things you can make iterators from
- Ranges (
0..10or0..=9) - Slices (
&[T]) - Things that deref to a slice (like
Vec<T>) - A
HashMaporBTreeMap - A String slice (to get chars, or bytes, or lines, or words…)
- A Buffered I/O Reader, to get Lines of text
- A TCP Listener, to get TCP Streams
- Your own types!
- Much more!
Note:
Technically a Range is an Iterator. Some people consider this to be a mistake.
Especially as Range<T> where T: Copy is not itself Copy.
How does this work?
- Rust has some
traitswhich describe how iterators work. - We’ll talk more about traits later!
You can still enjoy it without knowing how it works
Useful Iterator methods (1)
These consume the old Iterator and return a new Iterator:
skip(N)take(N)cloned()map(func)filter(func_returns_bool)filter_map(func_returns_option)zip(second_iterator)
Note:
skip(N)will skip the first N items from the underlying iterator, then just pass every other item throughtake(N)will take the first N items from the underlying iterator, then just tell you there is nothing leftclonedtakes an iterator that gives you references, and calls.clone()on each reference to create a new objectmap(func)will give you a new iterator that fetches an item from the underlying iterator, callsfuncwith it, and gives you the resultfilter(func)will give you a new iterator that fetches an item from the underlying iterator, callsfuncwith it, and if it’s not true, refuses to give it to you and tries the next item insteadfilter_map(func)is both a filter and a map - thefuncshould return anOption<T>and anythingNoneis filtered outzipwill take this iterator, and the given iterator, and produce a new iterator that produces two-tuples ((itemA, itemB))
Useful Iterator methods (2)
These actively fetch every item from the old Iterator and produce a single value:
sum()count()collect()max()andmin()fold(initial, func)partition(func)find(func)
Note:
sumwill add up every item, assuming they are numericcountwill tell you how many items the iterator producedcollectwill take every item from the iterator and stuff it into a new collection (e.g. aVec<T>)maxandminfind the largest/smallest itemfoldwill maintain an accumulator, and callfuncwith each item and the current value of the accumulatorpartitionwill create two new collections by taking every item from the iterator and stuffing it into one of two new collectionsfindwill only fetch items untilfuncreturnstruefor the given item. It returns anOption<T>.
Call chaining (1)
This style of code is idiomatic in Rust:
/// Sum the squares of the even numbers given
fn process_data(data: &[u32]) -> u32 {
data.iter()
.cloned()
.filter(|n| n % 2 == 0)
.map(|n| n * n)
.sum()
}
fn main() {
let data = [1, 2, 3, 4];
println!("result = {}", process_data(&data));
}Note:
- Point out the type inference where Rust figures out
datais an array ofu32and not the defaulti32s.
Call chaining (2)
What really happened:
/// Sum the squares of the even numbers given
fn process_data(data: &[u32]) -> u32 {
let ref_iter = data.iter();
let value_iter = ref_iter.cloned();
let evens_iter = value_iter.filter(|n| n % 2 == 0);
let squares_iter = evens_iter.map(|n| n * n);
squares_iter.sum()
}
fn main() {
let data = [1, 2, 3, 4];
println!("result = {}", process_data(&data));
}Note:
For the more advanced students, this mini quiz is a good one: https://dtolnay.github.io/rust-quiz/26
Imports and Modules
Namespaces
- A namespace is simply a way to distinguish two things that have the same name.
- It provides a scope to the identifiers within it.
Rust supports namespacing in two ways:
- Crates for re-usable software libraries
- Modules for breaking up your crates
Crates
- A crate is the unit of Rust software suitable for shipping.
- Yes, it’s a deliberate pun.
- The Rust Standard Library is a crate.
- Binary Crates and Library Crates
There’s no build file
- Have you noticed that
Cargo.tomlsays nothing about which files to compile? - Cargo starts with
lib.rsfor a library or the relevantmain.rsfor a binary - It then finds all the modules
Modules
- A module is block of source code within a crate
- It qualifies the names of everything in it
- It has a parent module (or it is the crate root)
- It can have child modules
- The crate is therefore a tree
Standard Library
We’ve been using modules from the Rust Standard Library…
use std::fs;
use std::io::prelude::*;
fn main() -> std::io::Result<()> {
let mut f = fs::File::create("hello.txt")?;
f.write(b"hello")?;
Ok(())
}Note:
- The
std::fsmodule - The
std::iomodule - The
std::io::preludemodule
Prelude modules, like std::io::prelude, usually contain important traits and you usually want to import all of it with a * wildcard.
In-line modules
You can declare a module in-line:
mod animals {
pub struct Cat { name: String }
impl Cat {
pub fn new(name: &str) -> Cat {
Cat { name: name.to_owned() }
}
}
}
fn main() {
let c = animals::Cat::new("Mittens");
// let c = animals::Cat { name: "Mittens".to_string() };
}Modules in a file
You can also put modules in their own file on disk.
This will load from either ./animals/mod.rs or ./animals.rs:
mod animals;
fn main() {
let c = animals::Cat::new("Mittens");
// let c = animals::Cat { name: "Mittens".to_string() };
}Modules can be nested…
~/probe-run $ tree src
src
├── backtrace
│ ├── mod.rs
│ ├── pp.rs
│ ├── symbolicate.rs
│ └── unwind.rs
├── canary.rs
├── cli.rs
├── cortexm.rs
├── dep
│ ├── cratesio.rs
│ ├── mod.rs
│ ├── rust_repo.rs
│ ├── rust_std
│ │ └── toolchain.rs
│ ├── rust_std.rs
│ └── rustc.rs
├── elf.rs
├── main.rs
├── probe.rs
├── registers.rs
├── stacked.rs
└── target_info.rs
Note:
The choice about foo.rs vs foo/mod.rs often depends on whether mod foo
itself has any child modules.
The example is from the Knurling tool probe-run.
What kind of import?
Choosing whether to import the parent module, or each of the types contained within, is something of an art form.
#![allow(unused)]
fn main() {
use std::fs;
use std::collections::VecDeque;
use std::io::prelude::*;
}Standard Library
There’s also a more compact syntax for imports.
use std::{fs, io::prelude::*};
fn main() -> std::io::Result<()> {
let mut f = fs::File::create("hello.txt")?;
f.write(b"hello")?;
Ok(())
}Good Design Practices
Two types of Rust crates
- binary - a program you can run directly
- library - a collection of useful code that you can re-use in a binary
Binary crate
cargo new my_app
my_app/
├── src/
│ └── main.rs
└── Cargo.toml
Library crate
cargo new --lib my_library
my_library/
├── src/
│ └── lib.rs
└── Cargo.toml
How to run the code in a library?
Use tests!
#![allow(unused)]
fn main() {
pub fn add(left: usize, right: usize) -> usize {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}
}Testing
- mark your function with
#[test] - use
assert!,assert_eq!,assert_ne!for assertionsassert_eq!,assert_ne!will show you the difference between left and right arguments- all assertions take an optional custom error message argument
- first failed assertion in a test function will stop the current test, other tests will still run
cargo testwill run all tests
Assertions for your own types:
struct Point(i32, i32);
fn main() {
let p = Point (1, 2);
assert_eq!(p, Point(1, 2));
}Errors:
- “binary operation
==cannot be applied to typePoint”- can’t compare two Points
- “
Pointdoesn’t implementDebug”- can’t print out a Point in error messages
Derives - adding behavior to your types
#[derive(Debug, PartialEq)]
struct Point(i32, i32);
fn main() {
let p = Point (1, 2);
assert_eq!(p, Point(1, 2));
}Debug
Allows printing of values with debug formatting
#[derive(Debug)]
struct Point { x: i32, y: i32 }
#[derive(Debug)]
struct TuplePoint(i32, i32);
fn main() {
let p = Point { y: 2, x: 1 };
let tp = TuplePoint (1, 2);
println!("{:?}", p); // Point { x: 1, y: 2 }
println!("{:?}", tp); // TuplePoint (1, 2)
}PartialEq
- Allows checking for equality (
==and!=) - For complex types does a field-by-field comparison
- For references it compares data that references observe
- Can compare arrays and slices if their elements are
PartialEq, too
PartialEq and Eq
Eq means strict mathematical equality:
a == ashould always be truea == bmeansb == aa == bandb == cmeansa == c
IEEE 754 floating point numbers (f32 and f64) break the first rule (NaN == NaN is always false). They are PartialEq and not Eq.
PartialOrd and Ord
- Same as
PartialEqandEq, but they also allow other comparisons (<,<=,>=,>). - Generally, everything is
Ord, exceptf32andf64. - Characters are compared by their code point numerical values
- Arrays and slices are compared element by element. Length acts as a tiebreaker.
"aaa" < "b", but"aaa" > "a"- elements themselves have to be
PartialOrdorOrd
How derives work?
Debug,PartialEq,Eq, etc. are simultaneously names of “Traits” and names of “derive macros”.- If a trait has a corresponding derive macro it can be “derived”:
- Rust will generate a default implementation.
- Not all traits have a corresponding derive macros
- these traits have to be implemented manually.
Debug and Display
- a pair of traits.
Debugis for debug printing- can be derived
Displayis for user-facing printing- cannot be derived, and must be implemented manually
println!("{:?}", value); // uses `Debug`
println!("{:#?}", value); // uses `Debug` and pretty-prints structures
println!("{}", value); // uses `Display`Traits dependencies
Traits can depend on each other.
EqandPartialOrdboth requirePartialEq.Ordrequires bothEqandPartialOrd
#[derive(Debug, Ord)] // will give an error
#[derive(Debug, PartialEq, Eq, PartialOrd, Ord)] // OkOther useful traits:
Hash- a type can be used as a key forHashMapDefault- a type gets adefault()method to produce a default value0is used for numbers,""for strings- collections starts as empty
Optionfields will beNone
Cloneadds aclone()method to produce a deep copy of a value
derive lists can get be pretty long.
Documentation
///marks doc comments- Markdown
- Rust fragments in doc comments produce documentation tests
- Use it to test you examples.
- Example from a standard library:
Formatting and Linting
rustfmt is a default Rust formatter
cargo fmt
Clippy is a linter for Rust code
cargo clippy
Cargo Workspaces
Cargo Workspaces
Allow you to split your project into several packages
- further encourages modularity
- develop multiple applications and libraries in a single tree
- synchronized dependency management, release process, etc.
- a way to parallelize compilation and speed up builds
- your internal projects should likely be workspaces even if you don’t use monorepos
Anatomy of Rust Workspace
my-app/
├── Cargo.toml # a special workspace file
├── Cargo.lock # notice that Cargo produces a common lockfile for all packages
├── packages/ # can use any directory structure
│ ├── main-app/
│ │ ├── Cargo.toml
│ │ └── src/
│ │ └── main.rs
│ ├── admin-app/
│ │ └── ...
│ ├── common-data-model/
│ │ ├── Cargo.toml
│ │ └── src/
│ │ └── lib.rs
│ ├── useful-macros
│ ├── service-a
│ ├── service-b
│ └── ...
└── tools/ # packages don't have to be in the same directory
├── release-bot/
│ ├── Cargo.toml
│ └── src/
│ └── main.rs
├── data-migration-scripts/
│ ├── Cargo.toml
│ └── src/
│ └── main.rs
└── ...
Workspace Cargo.toml
[workspace]
resolver = "2"
members = ["packages/*", "tools/*"]
[dependencies]
thiserror = "1.0.39"
...
using wildcards for members is very handy when you want to add new member packages, split packages, etc.
Cargo.toml for a workspace member
[package]
name = "main-app"
[dependencies]
thiserror = { workspace = true }
service-a = { path = "../service-a" }
...
Cargo commands for workspaces
cargo run --bin main-appcargo test -p service-a
Creating a workspace
#!/usr/bin/env bash
function nw() {
local name="$1"
local work_dir="$PWD"
mkdir -p "$work_dir/$name/packages"
git init -q "$work_dir/$name"
cat > "$work_dir/$name/Cargo.toml" << EOF
[workspace]
resolver = "2"
members = ["packages/*"]
[workspace.dependencies]
EOF
cat > "$work_dir/$name/.gitignore" << EOF
target
EOF
code "$work_dir/$name"
}
Example:
nw spaceship
cargo new --lib spaceship/packages/fuel-control
Methods and Traits
Methods
Methods
- Methods in Rust, are functions in an
implblock - They take
self(or similar) as the first argument (the method receiver) - They can be called with the method call operator
Example
struct Square(f64);
impl Square {
fn area(&self) -> f64 { self.0 * self.0 }
fn double(&mut self) { self.0 *= 2.0; }
fn destroy(self) -> f64 { self.0 }
}
fn main() {
let mut sq = Square(5.0);
sq.double(); // Square::double(&mut sq)
println!("area is {}", sq.area()); // Square::area(&sq)
sq.destroy(); // Square::destroy(sq)
}Note:
You can always use the full function-call syntax. That is what the method call operator will be converted into during compilation.
For motivation for something that takes self, imagine an embedded device with a Uart object that owns two Pin objects - one for the Tx pin and one for the Rx pin. Whilst the Uart object exists, those pins are in UART mode. But if you destroy the Uart, you want to get the pins back so you can re-use them for something else (e.g. as GPIO pins). Equally you could destroy some HTTPRequest object and recover the TCPStream contained within, so you could use it for WebSocket traffic instead of HTTP traffic.
Method Receivers
&selfmeansself: &Self&mut selfmeansself: &mut Selfselfmeansself: SelfSelfmeans whatever type thisimplblock is for
Method Receivers
- Other, fancier, method receivers are available!
struct Square(f64);
impl Square {
fn by_value(self: Self) {}
fn by_ref(self: &Self) {}
fn by_ref_mut(self: &mut Self) {}
fn by_box(self: Box<Self>) {}
fn by_rc(self: Rc<Self>) {}
fn by_arc(self: Arc<Self>) {}
fn by_pin(self: Pin<&Self>) {}
fn explicit_type(self: Arc<Example>) {}
fn with_lifetime<'a>(self: &'a Self) {}
fn nested<'a>(self: &mut &'a Arc<Rc<Box<Alias>>>) {}
fn via_projection(self: <Example as Trait>::Output) {}
}Notes:
This slide is only intended to show that there’s lots of complexity behind the curtain, and we’re ignoring almost all of it in this course. Come back for Advanced Rust if you want to know more!
Associated Functions
- You can also just declare functions with no method receiver.
- You call these with normal function call syntax.
- Typically we provide a function called
new
pub struct Square(f64);
impl Square {
pub fn new(width: f64) -> Square {
Square(width)
}
}
fn main() {
// Just an associated function - nothing special about `new`
let sq = Square::new(5.0);
}Note:
Question - can anyone just call Square(5.0) instead of Square::new(5.0)? Even from another module?
Associated Constants
impl blocks can also have const values:
#![allow(unused)]
fn main() {
pub struct Square(f64);
impl Square {
const NUMBER_OF_SIDES: u8 = 4;
pub fn perimeter(&self) -> f64 {
self.0 * f64::from(Self::NUMBER_OF_SIDES)
}
}
}Traits
Traits
- A trait is a list of methods and functions that a type must have.
- A trait can provide default implementations if desired.
#![allow(unused)]
fn main() {
trait HasArea {
/// Get the area, in m².
fn area_m2(&self) -> f64;
/// Get the area, in acres.
fn area_acres(&self) -> f64 {
self.area_m2() / 4046.86
}
}
}An example
trait HasArea {
fn area_m2(&self) -> f64;
}
struct Square(f64);
impl HasArea for Square {
fn area_m2(&self) -> f64 {
self.0 * self.0
}
}
fn main() {
let sq = Square(5.0);
println!("{}", sq.area_m2());
}Associated Types
A trait can also have some associated types, which are type aliases chosen when the trait is implemented.
#![allow(unused)]
fn main() {
trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
struct MyRange { start: u32, len: u32 }
impl Iterator for MyRange {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
todo!();
}
}
}Rules for Implementing
You can only implement a Trait for a Type if:
- The Type was declared in this module, or
- The Trait was declared in this module
You can’t implement someone else’s trait on someone else’s type!
Note:
If this was allowed, how would anyone know about it?
Rules for Using
You can only use the trait methods provided by a Trait on a Type if:
- The trait is in scope
- (e.g. you add
use Trait;in that module)
Traits
- The standard library provides lots of traits, such as:
Note:
We walk the attendees through each of these examples. They are only listed in pairs for the pleasing symmetry - nothing in Rust says they have to come in pairs.
Sneaky Workarounds
If a trait method uses &mut self and you really want it to work on some &SomeType reference, you can:
impl SomeTrait for &SomeType {
// ...
}The I/O traits do this.
Using Traits Statically
- One way to use traits is by using
impl Traitas a type. - This is static-typing, and a new function is generated for every actual type passed.
- Known as monomorphisation
- You can also
impl Traitin the return position.
Using Traits Statically: Example
#![allow(unused)]
fn main() {
trait HasArea {
fn area_m2(&self) -> f64;
}
struct AreaCalculator {
area_m2: f64
}
impl AreaCalculator {
// Multiple symbols may be generated by this function
fn add(&mut self, shape: impl HasArea) {
self.area_m2 += shape.area_m2();
}
fn total(&self) -> impl std::fmt::Display {
self.area_m2
}
}
}Note:
The total function says “I will give you a value you can display (with println), but I am not telling you what it is”. You can look up “RPIT” (return position impl trait) for the history of this feature. APIT (argument position impl trait) is probably the less useful of the two.
Using Traits Dynamically
- Rust also supports trait references
- The types are given at run-time through a vtable
- The reference is now a wide pointer
Using Traits Dynamically: Example
#![allow(unused)]
fn main() {
trait HasArea {
fn area_m2(&self) -> f64;
}
struct AreaCalculator {
area_m2: f64
}
impl AreaCalculator {
// Only one symbol is generated by this function. The reference contains
// a pointer to the table, *and* a pointer to a function table.
fn add(&mut self, shape: &dyn HasArea) {
self.area_m2 += shape.area_m2();
}
fn total(&self) -> &dyn std::fmt::Display {
&self.area_m2
}
}
}Note:
In earlier editions, it was just &Trait, but it was changed to &dyn Trait
Which is better?
Monomorphisation? Or Polymorphism?
Requiring other Traits
- Traits can also require other traits to also be implemented
#![allow(unused)]
fn main() {
trait Printable: std::fmt::Debug {
fn print(&self) {
println!("I am {:?}", self);
}
}
}Special Traits
- Some traits have no functions (
Copy,Send,Sync, etc)- But code can require that the trait is implemented
- More in this in generics!
- Traits can be marked
unsafe- Must use the
unsafekeyword to implement - They’re telling you to read the instructions!
- Must use the
Rust I/O Traits
There are two kinds of computer:
- Windows NT based
- POSIX based (macOS, Linux, QNX, etc)
Rust supports both.
Note:
We’re specifically talking about libstd targets here. Targets that only have
libcore have very little I/O support built-in - it’s all third party crates.
They are very different:
HANDLE CreateFileW(
/* [in] */ LPCWSTR lpFileName,
/* [in] */ DWORD dwDesiredAccess,
/* [in] */ DWORD dwShareMode,
/* [in, optional] */ LPSECURITY_ATTRIBUTES lpSecurityAttributes,
/* [in] */ DWORD dwCreationDisposition,
/* [in] */ DWORD dwFlagsAndAttributes,
/* [in, optional] */ HANDLE hTemplateFile
);
int open(const char *pathname, int flags, mode_t mode);
Abstractions
To provide a common API, Rust offers some basic abstractions:
- A
Readtrait for reading bytes - A
Writetrait for writing bytes - Buffered wrappers for the above (
BufReaderandBufWriter) - A
Seektrait for adjusting the read/write offset in a file, etc - A
Filetype to represent open files - Types for
Stdin,StdoutandStderr - The
Cursortype to make a[u8]readable/writable
The Read Trait
https://doc.rust-lang.org/std/io/trait.Read.html
#![allow(unused)]
fn main() {
use std::io::Result;
pub trait Read {
// One required method
fn read(&mut self, buf: &mut [u8]) -> Result<usize>;
// Lots of provided methods, such as:
fn read_to_string(&mut self, buf: &mut String) -> Result<usize> { todo!() }
}
}Immutable Files
- A
Fileon POSIX is just an integer (recallopenreturns anint) - Do you need a
&mut Fileto write?- No - the OS handles shared mutability internally
- But the trait requires
&mut self…
Implementing Traits on &Type
impl Read for File {
}
impl Read for &File {
}See the std::io::File docs.
OS Syscalls
- Remember, Rust is explicit
- If you ask to read 8 bytes, Rust will ask the OS to get 8 bytes from the device
- Asking the OS for anything is expensive!
- Asking the OS for a million small things is really expensive…
Buffered Readers
- There is a
BufReadtrait, for buffered I/O devices - There is a
BufReaderstruct- Owns a
R: Read, andimpl BufRead - Has a buffer in RAM and reads in large-ish chunks
- Owns a
#![allow(unused)]
fn main() {
use std::io::BufRead;
fn print_file() -> std::io::Result<()> {
let f = std::fs::File::open("/etc/hosts")?;
let reader = std::io::BufReader::new(f);
for line in reader.lines() {
println!("{}", line?);
}
Ok(())
}
}The write! macro
- You can
println!to standard output - You can
format!to aString - You can also
write!to anyT: std::io::Write
use std::io::Write;
fn main() -> std::io::Result<()> {
let filling = "Cheese and Jam";
let f = std::fs::File::create("lunch.txt")?;
write!(&f, "I have {filling} sandwiches")?;
Ok(())
}Networking
- In Rust, a
TcpStreamalso implements theReadandWritetraits. - You create a
TcpStreamwith either:TcpStream::connect- for outbound connectionsTcpListener::accept- for incoming connectionsTcpListener::incoming- an iterator over incoming connections
- As before, you might want to wrap your
TcpStreamin aBufReader
End of the Line
- It’s obvious when you’ve hit the end of a
File - When do you hit the end of a
TcpStream?- When either side does a
shutdown
- When either side does a
Note:
Readtrait has a methodread_to_end()
Binding Ports
TcpListenerneeds to know which IP address and port to bind- Rust has a
ToSocketAddrstrait impl’d on many things&str,(IpAddr, u16),(&str, u16), etc
- It does DNS lookups automatically (which may return multiple addresses…)
fn main() -> Result<(), std::io::Error> {
let listener = std::net::TcpListener::bind("127.0.0.1:7878")?;
Ok(())
}More Networking
- There is also
std::net::UdpSocket IpAddris an enum ofIpv4AddrandIpv6AddrSocketAddris an enum ofSocketAddrV4andSocketAddrV6- But TLS, HTTP and QUIC are all third-party crates
Note:
Some current prominent examples of each -
- TLS - RusTLS
- HTTP - hyperium/http
- QUIC - cloudflare/quiche
Failures
- Almost any I/O operation can fail
- Almost all
std::ioAPIs returnResult<T, std::io::Error> std::io::Result<T>is an alias- Watch out for it in the docs!
Generics
Generics are fundamental for Rust.
Generic Structs
Structs can have type parameters.
struct Point<Precision> {
x: Precision,
y: Precision,
}
fn main() {
let point = Point { x: 1_u32, y: 2 };
let point: Point<i32> = Point { x: 1, y: 2 };
}Note:
The part <Precision> introduces a type parameter called Precision. Often people just use T but you don’t have to!
Type Inference
- Inside a function, Rust can look at the types and infer the types of variables and type parameters.
- Rust will only look at other signatures, never other bodies.
- If the function signature differs from the body, the body is wrong.
Generic Enums
Enums can have type parameters.
enum Either<T, X> {
Left(T),
Right(X),
}
fn main() {
let alternative: Either<i32, f64> = Either::Left(123);
}Note:
What happens if I leave out the <i32, f64> specifier? What would type parameter X be set to?
Generic Functions
Functions can have type parameters.
#![allow(unused)]
fn main() {
fn print_stuff<X>(value: X) {
// What can you do with `value` here?
}
}Note:
Default bounds are Sized, so finding the size of the type is one thing that you can do. You can also take a reference or a pointer to the value.
Generic Implementations
struct Vector<T> {
x: T,
y: T,
}
impl<T> Vector<T> {
fn new(x: T, y: T) -> Vector<T> {
Vector { x, y }
}
}
impl Vector<f32> {
fn magnitude(&self) -> f32 {
((self.x * self.x) + (self.y * self.y)).sqrt()
}
}
fn main() {
let v1 = Vector::new(1.0, 1.0);
println!("{}", v1.magnitude());
let v2 = Vector::new(1, 1);
// println!("{}", v2.magnitude());
}Note:
Can I call my_vector.magnitude() if T is … a String? A Person? A TCPStream?
Are there some trait bounds we could place on T such that T + T -> T and T * T -> T and T::sqrt() were all available?
The error:
error[E0599]: no method named `magnitude` found for struct `Vector<{integer}>` in the current scope
--> src/main.rs:23:23
|
2 | struct Vector<T> {
| ---------------- method `magnitude` not found for this struct
...
23 | println!("{}", v2.magnitude());
| ^^^^^^^^^ method not found in `Vector<{integer}>`
|
= note: the method was found for
- `Vector<f32>`
For more information about this error, try `rustc --explain E0599`.Adding Bounds
- Generics aren’t much use without bounds.
- A bound says which traits must be implemented on any type used for that type parameter
- You can apply the bounds on the type, or a function/method, or both.
Adding Bounds - Example
trait HasArea {
fn area(&self) -> f32;
}
fn print_area<T>(shape: &T) where T: HasArea {
let area = shape.area();
println!("Area = {area:?}");
}
struct UnitSquare;
impl HasArea for UnitSquare {
fn area(&self) -> f32 {
1.0
}
}
fn main() {
let u = UnitSquare;
print_area(&u);
}Adding Bounds - Alt. Example
trait HasArea {
fn area(&self) -> f32;
}
fn print_area<T: HasArea>(shape: &T) {
let area = shape.area();
println!("Area = {area:?}");
}
struct UnitSquare;
impl HasArea for UnitSquare {
fn area(&self) -> f32 {
1.0
}
}
fn main() {
let u = UnitSquare;
print_area(&u);
}Note:
This is exactly equivalent to the previous example, but shorter. However, if you end up with a large set of bounds, they are easier to format when at the end of the line.
General Rule
- If you can, try and avoid adding bounds to
structs. - Simpler to only add them to the methods.
Multiple Bounds
You can specify multiple bounds.
trait HasArea {
fn area(&self) -> f32;
}
fn print_area<T: std::fmt::Debug + HasArea>(shape: &T) {
println!("Shape {:?} has area {}", shape, shape.area());
}
#[derive(Debug)]
struct UnitSquare;
impl HasArea for UnitSquare {
fn area(&self) -> f32 { 1.0 }
}
fn main() {
let u = UnitSquare;
print_area(&u);
}impl Trait
- The
impl Traitsyntax in argument position was just syntactic sugar. - (It does something special in the return position though)
#![allow(unused)]
fn main() {
trait HasArea {
fn area_m2(&self) -> f64;
}
struct AreaCalculator {
area_m2: f64
}
impl AreaCalculator {
// Same: fn add(&mut self, shape: impl HasArea) {
fn add<T: HasArea>(&mut self, shape: T) {
self.area_m2 += shape.area_m2();
}
}
}Note:
Some types that cannot be written out, like the closure, can be expressed as return types using impl. e.g. fn score(y: i32) -> impl Fn(i32) -> i32.
Caution
- Using Generics is Hard Mode Rust
- Don’t reach for it in the first instance…
- Try and just use concrete types?
Generic over Constants
In Rust 1.51, we gained the ability to be generic over constant values too.
struct Polygon<const SIDES: u8> {
colour: u32
}
impl<const SIDES: u8> Polygon<SIDES> {
fn new(colour: u32) -> Polygon<SIDES> { Polygon { colour } }
fn print(&self) { println!("{} sides, colour=0x{:06x}", SIDES, self.colour); }
}
fn main() {
let triangle: Polygon<3> = Polygon::new(0x00FF00);
triangle.print();
}Note:
SIDES is a property of the type, and doesn’t occupy any memory within any
values of that type at run-time - the constant is pasted in wherever it is used.
Generic Traits
Traits themselves can have type parameters too!
trait HasArea<T> {
fn area(&self) -> T;
}
// Here we only accept a shape where the `U` in `HasArea<Y>` is printable
fn print_area<T, U>(shape: &T) where T: HasArea<U>, U: std::fmt::Debug {
let area = shape.area();
println!("Area = {area:?}");
}
struct UnitSquare;
impl HasArea<f64> for UnitSquare {
fn area(&self) -> f64 {
1.0
}
}
fn main() {
let u = UnitSquare;
print_area(&u);
}Special Bounds
- Some bounds apply automatically
- Special syntax to turn them off
#![allow(unused)]
fn main() {
fn print_debug<T: std::fmt::Debug + ?Sized>(value: &T) {
println!("value is {:?}", value);
}
}Note:
This bound says “It must implement std::fmt::Debug, but I don’t care if it has a size known at compile-time”.
Things that don’t have sizes known at compile time (but which may or may not implement std::fmt::Debug) include:
- String Slices
- Closures
Lifetimes
Rust Ownership
- Every piece of memory in Rust program has exactly one owner at the time
- Ownership changes (“moves”)
fn takes_ownership(data: Data)fn producer() -> Datalet people = [paul, john, emma];
Producing owned data
fn producer() -> String {
String::new()
}Producing references?
fn producer() -> &str {
// ???
}&str“looks” at some string data. Where can this data come from?
Local Data
Does this work?
fn producer() -> &str {
let s = String::new();
&s
}Local Data
No, we can’t return a reference to local data…
error[E0515]: cannot return reference to local variable `s`
--> src/lib.rs:3:5
|
3 | &s
| ^^ returns a reference to data owned by the current function
Local Data
You will also see:
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:18
|
1 | fn producer() -> &str {
| ^ expected named lifetime parameter
|
Static Data
#![allow(unused)]
fn main() {
fn producer() -> &'static str {
"hello"
}
}- bytes
h e l l oare “baked” into your program - part of static memory (not heap or stack)
- a slice pointing to these bytes will always be valid
- safe to return from
producerfunction
Note:
You didn’t need to specify 'static for the static variable - there’s literally no other lifetime that can work here.
How big is a &'static str? Do you think the length lives with the string data, or inside the str-reference itself?
(It lives with the reference - so you can take sub-slices)
Static Data
It doesn’t have to be a string literal - any reference to a static is OK.
#![allow(unused)]
fn main() {
static HELLO: [u8; 5] = [0x68, 0x65, 0x6c, 0x6c, 0x6f];
fn producer() -> &'static str {
std::str::from_utf8(&HELLO).unwrap()
}
}'static annotation
- Rust never assumes
'staticfor function returns or fields in types &'static Tmeans this reference toTwill never become invalidT: 'staticmeans that “if typeThas any references inside they should be'static”Tmay have no references inside at all!
- string literals are always
&'static str
fn takes_and_returns(s: &str) -> &str {
}Where can the returned &str come from?
- can't be local data
- is not marked as
'static - Conclusion: must come from
s!
Multiple sources
fn takes_many_and_returns(s1: &str, s2: &str) -> &str {
}Where can the returned &str come from?
- is not marked as
'static - should it be
s1ors2? - Ambiguous. Should ask programmer for help!
Tag system
fn takes_many_and_returns<'a>(s1: &str, s2: &'a str) -> &'a str {
}“Returned &str comes from s2”
'a
- “Lifetime annotation”
- often called “lifetime” for short, but that’s a very bad term
- every reference has a lifetime
- annotation doesn’t name a lifetime of a reference, but used to tie lifetimes of several references together
- builds “can’t outlive” and “should stay valid for as long as” relations
- arbitrary names:
'a,'b,'c,'whatever
Lifetime annotations in action
fn first_three_of_each(s1: &str, s2: &str) -> (&str, &str) {
(&s1[0..3], &s1[0..3])
}
fn main() {
let amsterdam = format!("AMS Amsterdam");
let (amsterdam_code, denver_code) = {
let denver = format!("DEN Denver");
first_three_of_each(&amsterdam, &denver)
};
println!("{} -> {}", amsterdam_code, denver_code);
}Annotate!
fn first_three_of_each<'a, 'b>(s1: &'a str, s2: &'b str) -> (&'a str, &'b str) {
(&s1[0..3], &s1[0..3])
}Annotations are used to validate function body
“The source you used in code doesn’t match the tags”
error: lifetime may not live long enough
--> src/lib.rs:2:5
|
1 | fn first_three_of_each<'a, 'b>(s1: &'a str, s2: &'b str) -> (&'a str, &'b str) {
| -- -- lifetime `'b` defined here
| |
| lifetime `'a` defined here
2 | (&s1[0..3], &s1[0..3])
| ^^^^^^^^^^^^^^^^^^^^^^ function was supposed to return data with lifetime `'b` but it is returning data with lifetime `'a`
|
= help: consider adding the following bound: `'a: 'b`
Annotations are used to validate reference lifetimes at a call site
“Produced reference can’t outlive the source”
error[E0597]: `amsterdam` does not live long enough
--> src/main.rs:10:29
|
6 | let amsterdam = format!("AMS Amsterdam");
| --------- binding `amsterdam` declared here
...
10 | first_three_of_each(&amsterdam, &denver)
| --------------------^^^^^^^^^^----------
| | |
| | borrowed value does not live long enough
| argument requires that `amsterdam` is borrowed for `'static`
...
14 | }
| - `amsterdam` dropped here while still borrowed
Lifetime annotations help the compiler help you!
- You give Rust hints
- Rust checks memory access for correctness
fn first_three_of_each<'a, 'b>(s1: &'a str, s2: &'b str) -> (&'a str, &'b str) {
(&s1[0..3], &s2[0..3])
}
fn main() {
let amsterdam = format!("AMS Amsterdam");
let denver = format!("DEN Denver");
let (amsterdam_code, denver_code) = {
first_three_of_each(&amsterdam, &denver)
};
println!("{} -> {}", amsterdam_code, denver_code);
}What if multiple parameters can be sources?
fn pick_one(s1: &'? str, s2: &'? str) -> &'? str {
if coin_flip() {
s1
} else {
s2
}
}What if multiple parameters can be sources?
fn pick_one<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if coin_flip() {
s1
} else {
s2
}
}- returned reference can’t outlive either
s1ors2 - potentially more restrictive
Note:
This function body does not force the two inputs to live for the same amount of time. Variables live for as long as they live and we can’t change that here. This just says “I’m going to use the same label for the lifetimes these two references have, so pick whichever is the shorter”.
Example
fn coin_flip() -> bool { false }
fn pick_one<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if coin_flip() {
s1
} else {
s2
}
}
fn main() {
let a = String::from("a");
let b = "b";
let result = pick_one(&a, b);
// drop(a);
println!("{}", result);
}Lifetime annotations for types
struct Configuration {
database_url: &str,
}Where does the string data come from?
Generic lifetime parameter
struct Configuration<'a> {
database_url: &'a str,
}
- An instance of
Configurationcan’t outlive a string
that it refers to viadatabase_url. - The string can’t be dropped
while an instance ofConfigurationstill refers to it.
Lifetimes and Generics
- Lifetime annotations act like generics from type system PoV.
- Can be used to to add bounds to types:
where T: Debug + 'a- Type
Thas to be printable with:?. - If
Thas references inside, they have to stay valid for as long as'atag requires.
- Type
- Can be used to match lifetime generics in
structorenumwith the annotations used in function signatures and in turn with exact lifetimes of references.
Complex example
fn select_peer<'a>(peers: &[&'a str]) -> Option<Cow<'a, str>> {
for p in peers {
if is_up(p) {
return Some(Cow::Borrowed(p))
}
}
None
}
fn main() {}Compiler concludes:
Returned value will not be allowed to outlive any reference in peers list
let selected = select_peer(&peers);
Lifetime annotations in practice
- Like generics, annotations make function signatures verbose and difficult to read
- they often can be glossed over when reading code
T: 'staticmeans “Owned data or static references”, owned data can be very short-lived- Using owned data in your types helps avoid borrow checker difficulties
Closures
Rust’s Function Traits
trait FnOnce<Args>trait FnMut<Args>: FnOnce<Args>trait Fn<Args>: FnMut<Args>
Note:
- Instances of FnOnce can only be called once.
- Instances of FnMut can be called repeatedly and may mutate state.
- Instances of Fn can be called repeatedly without mutating state.
Fn(a trait) andfn(a function pointer) are different!
These traits are implemented by:
- Function Pointers
- Closures
Function Pointers
fn add_one(x: usize) -> usize {
x + 1
}
fn main() {
let ptr: fn(usize) -> usize = add_one;
println!("ptr(5) = {}", ptr(5));
}Closures
- Defined with
|<args>| - Most basic kind, are just function pointers
fn main() {
let clos: fn(usize) -> usize = |x| x + 5;
println!("clos(5) = {}", clos(5));
}Capturing
- Closures can capture their environment.
- Now it’s an anonymous
struct, not afn - It implements
Fn
fn main() {
let increase_by = 1;
let clos = |x| x + increase_by;
println!("clos(5) = {}", clos(5));
}The variable increase_by that is captured by the closure here is called an upvar
or a free variable.
Capturing Mutably
- Closures can capture their environment by mutable reference
- Now it implements
FnMut
fn main() {
let mut total = 0;
let mut update = |x| total += x;
update(5);
update(5);
println!("total: {}", total);
}Note:
The closure is dropped before the println!, making total accessible again (the &mut ref stored in the closure is now gone).
If you try and call update() after the println! you get a compile error.
Capturing by transferring ownership
This closure implements FnOnce.
fn main() {
let items = vec![1, 2, 3, 4];
let update = move || {
for item in items {
println!("item is {}", item);
}
};
update();
// println!("items is {:?}", items);
}But why?
- But why is this useful?
- It makes iterators really powerful!
fn main() {
let items = [1, 2, 3, 4, 5, 6];
let n = 2;
for even_number in items.iter().filter(|x| (**x % n) == 0) {
println!("{} is even", even_number);
}
}Cleaning up
It’s also very powerful if you have something you need to clean up.
- You do some set-up
- You want do some work (defined by the caller)
- You want to clean up after.
#![allow(unused)]
fn main() {
fn setup_teardown<F, T>(f: F) -> T where F: FnOnce(&mut Vec<u32>) -> T {
let mut state = Vec::new();
println!("> Setting up state");
let t = f(&mut state);
println!("< State contains {:?}", state);
t
}
}Cleaning up
fn setup_teardown<F, T>(f: F) -> T where F: FnOnce(&mut Vec<u32>) -> T {
let mut state = Vec::new();
println!("> Setting up state");
let t = f(&mut state);
println!("< State contains {:?}", state);
t
}
fn main() {
setup_teardown(|s| s.push(1));
setup_teardown(|s| {
s.push(1);
s.push(2);
s.push(3);
});
}Note:
In release mode, all this code just gets inlined.
Heap Allocation (Box, Rc and Cow)
Where do Rust variables live?
struct Square {
width: f32
}
fn main() {
let x: u64 = 0;
let y = Square { width: 1.0 };
let mut z: String = "Hello".to_string();
z.push_str(", world!");
}Note:
- The variable
xis an 8-byte (64-bit) value, and lives on the stack. - The variable
yis a 4-byte value, and also lives on the stack. - The variable
zis a 3x4-byte value on 32-bit platforms, and a 3x8-byte value on 64-bit platforms. TheStringitself is a struct, and the bytes contained within the struct live on the heap.
Let’s see some addresses…
struct Square {
width: f32
}
fn main() {
let x: u64 = 0;
let y = Square { width: 1.0 };
let mut z: String = "Hello".to_string();
z.push_str(", world!");
println!("x @ {:p}", &x);
println!("y @ {:p}", &y);
println!("z @ {:p}", &z);
println!("z @ {:p}", z.as_str());
}Note:
You expect to see something like:
x @ 0x7ffc2272c618
y @ 0x7ffc2272c624
z @ 0x7ffc2272c628
z @ 0x555829f269d0
The first z @ line is the struct String { ... } itself. The second z @ line are the bytes the String contains. They have a different addresses because they are in the heap and not on the stack.
If you run it multiple times, you will get different results. This is due to the Operating System randomizing the virtual addresses used for the stack and the heap, to make security vulnerabilities harder to exploit.
On macOS, you can run vmmap <pid> to print the addresses for each region. On Linux you can use pmap <pid>, or you could add something like:
#![allow(unused)]
fn main() {
if let Ok(maps) = std::fs::read_to_string(&format!("/proc/{}/maps", std::process::id())) {
println!("{}", maps);
}
}How does Rust handle the heap?
On three levels:
- Talking to your Operating System (or its C Library)
- A low-level API, called the Global Allocator
- A high-level API, with
Box,Rc,Vec, etc
What’s in the Box?
- A
Box<T>in Rust, is a handle to a unique, owned, heap-allocated value of typeT - The value is the size of a pointer
- The contents of the Box can be any T (including unsized things)
Note:
Pointers can be ‘thin’ (one word in length) or ‘wide’ (two words in length). In a wide pointer, the second word holds the length of the thing being pointed to, or a pointer to the vtable if it’s a dyn-trait pointer. The same applies to Boxes.
Why not raw pointers?
Because Box<T>:
- doesn’t let you do pointer arithmetic on it
- will automatically free the memory when it goes out of scope
- implements
Deref<T>andDerefMut<T>
Making a Box
The Deref and DerefMut trait implementations let us use a Box quite naturally:
fn main() {
let x: Box<f64> = Box::new(1.0_f64);
let y: f64 = x.sin() * 2.0;
let z: &f64 = &x;
println!("x={x}, y={y}, z={z}");
}When should I use a Box?
- Not very often - friendlier containers (like
Vec<T>) exist - If you have a large value that moves around a lot
- Moving a
Box<T>is cheap, because only the pointer moves, not the contents
- Moving a
- To hide the size or type of a returned value…
Boxed Traits
fn make_stuff(want_integer: bool) -> Box<dyn std::fmt::Debug> {
if want_integer {
Box::new(42_i32)
} else {
Box::new("Hello".to_string())
}
}
fn main() {
println!("make_stuff(true): {:?}", make_stuff(true));
println!("make_stuff(false): {:?}", make_stuff(false));
}Note:
An i32 and a String are very different sizes, and a function must have a single fixed size for the return value. But it does - it returns a Box and the Box itself always has the same size. The thing that varies in size is the value inside the box and that lives somewhere else - on the heap in fact.
This trick is also useful for closures, where the type cannot even be said out loud because it’s compiler-generated. But you can say a closure implements the FnOnce trait, for example.
Smarter Boxes
What if I want my Box to have multiple owners? And for the memory to be freed when both of the owners have finished with it?
We have the reference counted Rc<T> type for that!
Using Rc<T>
use std::rc::Rc;
struct Point { x: i32, y: i32 }
fn main() {
let first_handle = Rc::new(Point { x: 1, y: 1});
let second_handle = first_handle.clone();
let third_handle = second_handle.clone();
}Reference Counting
- The
Rctype is a handle to reference-counted heap allocation - When you do a
clone()the count goes up by one - When you drop it, the count goes down by one
- The memory isn’t freed until the count hits zero
- There’s a
Weakversion which will not keep the allocation alive - to break cycles
Note:
A cycle would be if you managed to construct two Rc wrapped structs and had
each one hold an Rc reference to the other. Now neither can ever be freed,
because each will always have at least one owner (the other).
Thread-safety
Rccannot be sent into a thread (or through any API that requires the type to beSend).- If in doubt, try it! Rust will save you from yourself.
- The trade-off is that
Rcis really fast! - There is an Atomic Reference Counted type,
Arcif you need it.
Rc is not mutable
NB: Rc allows sharing, but not mutability…
use std::rc::{Rc, Weak};
struct Dog { name: String, owner: Weak<Human> }
struct Human { name: String, pet_dogs: Vec<Dog> }
fn main() {
let mut sam = Rc::new(
Human { name: "Sam".to_string(), pet_dogs: Vec::new() }
);
let rover = Dog { name: "Rover".to_string(), owner: Rc::downgrade(&sam) };
// This is not allowed, because `sam` is actually immutable
// sam.pet_dogs.push(rover);
}Note:
You get an error like:
error[E0596]: cannot borrow data in an `Rc` as mutable
--> src/main.rs:12:5
|
12 | sam.pet_dogs.push(rover);
| ^^^^^^^^^^^^ cannot borrow as mutable
|
= help: trait `DerefMut` is required to modify through a dereference, but it is not implemented for `Rc<Human>`
For more information about this error, try `rustc --explain E0596`.
Why do you want this structure? Because given some &Dog you might very well want to know who owns it!
Shared Mutability
We have more on this later…
use std::rc::{Rc, Weak};
use std::cell::RefCell;
struct Dog { name: String, owner: Weak<RefCell<Human>> }
struct Human { name: String, pet_dogs: Vec<Dog> }
fn main() {
let mut sam = Rc::new(RefCell::new(
Human { name: "Sam".to_string(), pet_dogs: Vec::new() }
));
let rover = Dog { name: "Rover".to_string(), owner: Rc::downgrade(&sam) };
// This is now allowed because `RefCell::borrow_mut` does a run-time borrow check
sam.borrow_mut().pet_dogs.push(rover);
}Maybe Boxed, maybe not?
Why is this function less than ideal?
/// Replaces all the ` ` characters with `_`
fn replace_spaces(input: &str) -> String {
todo!()
}
fn main() {
println!("{}", replace_spaces("Hello, world!"));
println!("{}", replace_spaces("Hello!"));
}Note:
Did the second call replace anything? Did you have to allocate a String and copy all the data anyway, even though nothing changed?
Copy-On-Write
Rust has the Cow type to handle this.
/// Replaces all the ` ` characters with `_`
fn replace_spaces(input: &str) -> std::borrow::Cow<str> {
todo!()
}
fn main() {
println!("{}", replace_spaces("Hello, world!"));
println!("{}", replace_spaces("Hello!"));
}Note:
Cow works on any T where there is both a Borrowed version and an Owned version.
For example, &[u8] and Vec<u8>.
Shared Mutability (Cell, RefCell)
Rust has a simple rule
| Immutable | Mutable | |
|---|---|---|
| Exclusive | &mut T | &mut T |
| Shared | &T | 🔥🔥🔥 |
These rules can be … bent
(but not broken)
Why the rules exist…
- Optimizations!
- It is undefined behaviour (UB) to have multiple
&mutreferences to the same object at the same time - You must avoid UB
Note:
If you have UB in your program (anywhere), it is entirely valid for the compiler to delete your entire program and replace it with an empty program.
Bending the rules
There is only one way to modify data through a &T reference:
UnsafeCell
UnsafeCell
use std::cell::UnsafeCell;
fn main() {
let x: UnsafeCell<i32> = UnsafeCell::new(42);
let exc_ref: &mut i32 = unsafe { &mut *x.get() };
*exc_ref += 27;
drop(exc_ref);
let shared_1: &i32 = unsafe { &*x.get() };
assert_eq!(*shared_1, 42 + 27);
let shared_2: &i32 = unsafe { &*x.get() };
assert_eq!(*shared_1, *shared_2);
}Note:
The UnsafeCell::get(&self) -> *mut T method is safe, but dereferencing the pointer (or converting it to a &mut reference) is unsafe because a human must verify there is no aliasing.
Can we be safer?
A human must do a lot of manual checks here.
Can we make it nicer to use?
Cell
A Cell is safe to use.
But you can only copy in and copy out.
A motivating example
We have some blog posts which have immutable content, and an incrementing view count.
Ideally, we would have a fn view(&self) -> &str to return the content, and increment the view count.
Without Cell s
#![allow(unused)]
fn main() {
#[derive(Debug, Default)]
struct Post {
content: String,
viewed_times: u64,
}
impl Post {
// `mut` is a problem here!
fn view(&mut self) -> &str {
self.viewed_times += 1;
&self.content
}
}
}Without Cell
This isn’t ideal! view takes a &mut self, meaning this won’t work:
fn main() {
let post = Post { content: "Blah".into(), ..Post::default() };
// This line is a compile error!
// println!("{}", post.view());
}
// From before
#[derive(Debug, Default)]
struct Post {
content: String,
viewed_times: u64,
}
impl Post {
// `&mut self` is the problem here!
fn view(&mut self) -> &str {
self.viewed_times += 1;
&self.content
}
}Without Cell
fn main() {
// We need to make the entire struct mutable!
let mut post = Post { content: "Blah".into(), ..Post::default() };
println!("{}", post.view());
// Now this is allowed too...
post.content.push_str(" - extra content");
}
// From before
#[derive(Debug, Default)]
struct Post {
content: String,
viewed_times: u64,
}
impl Post {
fn view(&mut self) -> &str {
self.viewed_times += 1;
&self.content
}
}Using Cell instead
Let’s see our previous example with Cell.
fn main() {
let post = Post {
content: "Blah".into(),
..Post::default()
};
println!("{}", post.view());
}
#[derive(Debug, Default)]
struct Post {
content: String,
viewed_times: std::cell::Cell<u64>,
}
impl Post {
fn view(&self) -> &str {
// Note how we are making a copy, then replacing the original.
let current_views = self.viewed_times.get();
self.viewed_times.set(current_views + 1);
&self.content
}
}Note:
As an in-depth example of the borrow checker’s limitations, consider the Splitting Borrows idiom, which allows one to borrow different fields of the same struct with different mutability semantics:
#![allow(unused)]
fn main() {
struct Foo {
a: i32,
b: i32,
c: i32,
}
let mut x = Foo {a: 0, b: 0, c: 0};
let a = &mut x.a;
let b = &mut x.b;
let c = &x.c;
*b += 1;
let c2 = &x.c;
*a += 10;
println!("{} {} {} {}", a, b, c, c2);
}The code works, but, once you have mutably borrowed a field you cannot mutably borrow the whole value (e.g. by calling a method on it) at the same time - otherwise you could get two mutable references to the same field at the same time.
Here’s an example where tuple fields are special-cased for the borrow checker:
let mut z = (1, 2);
let r = &z.1;
z.0 += 1;
println!("{:?}, {}", z, r);but fails on an equivalent array
let mut z = [1, 2];
let r = &z[1];
z[0] += 1;
println!("{:?}, {}", z, r);RefCell
A RefCell is also safe, but lets you borrow or mutably borrow the contents.
The borrow checking is deferred to run-time
Using RefCell
use std::cell::RefCell;
fn main() {
let x: RefCell<i32> = RefCell::new(42);
let mut exc_ref = x.borrow_mut();
*exc_ref += 27;
drop(exc_ref);
let shared_1 = x.borrow();
// This isn't allowed here:
// let exc_ref = x.borrow_mut();
assert_eq!(*shared_1, 42 + 27);
let shared_2 = x.borrow();
assert_eq!(*shared_1, *shared_2);
}Using RefCell instead
Let’s see our previous example with RefCell.
fn main() {
let post = Post { content: "Blah".into(), ..Post::default() };
println!("{}", post.view());
}
#[derive(Debug, Default)]
struct Post {
content: String,
viewed_times: std::cell::RefCell<u64>,
}
impl Post {
fn view(&self) -> &str {
let mut view_count_ref = self.viewed_times.borrow_mut();
*view_count_ref += 1;
&self.content
}
}RefCell Tradeoffs
Moving the borrow checking to run-time:
- Might make your program actually compile 😀
- Might cause your program to panic 😢
interior mutability is something of a last resort
Using with Rc
To get shared ownership and mutability you need two things:
Rc<RefCell<T>>- (Multi-threaded programs might use
Arc<Mutex<T>>)
OnceCell for special cases
A OnceCell lets you initialise a value using &self, but not subsequently modify it.
fn main() {
let post: Post = Post { content: "Blah".into(), ..Post::default() };
println!("{:?}", post.first_viewed());
}
#[derive(Debug, Default)]
struct Post {
content: String,
first_viewed_at: std::cell::OnceCell<std::time::Instant>,
}
impl Post {
fn first_viewed(&self) -> std::time::Instant {
self.first_viewed_at.get_or_init(std::time::Instant::now).clone()
}
}Thread Safety (Send/Sync, Arc, Mutex)
Rust is thread-safe
But what does that mean?
An Example in C (or C++)
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
void *thread_function(void *p_arg) {
int* p = (int*) p_arg;
for(int i = 0; i < 1000000; i++) {
*p += 1;
}
return NULL;
}
int main() {
int value = 0;
pthread_t thread1, thread2;
pthread_create(&thread1, NULL, thread_function, &value);
pthread_create(&thread2, NULL, thread_function, &value);
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
printf("value = %d\n", value);
exit(0);
}
What does that produce…
1000000 * 2 = 2000000, right?
$ ./a.out
value = 1059863
But there were no compiler errors!
(See https://godbolt.org/z/41x1dG6oY)
Let’s try Rust
fn thread_function(arg: &mut i32) {
for _ in 0..1_000_000 {
*arg += 1;
}
}
fn main() {
let mut value = 0;
std::thread::scope(|s| {
s.spawn(|| thread_function(&mut value));
s.spawn(|| thread_function(&mut value));
});
println!("value = {value}");
}Oh!
error[E0499]: cannot borrow `value` as mutable more than once at a time
--> src/main.rs:11:17
|
9 | std::thread::scope(|s| {
| - has type `&'1 Scope<'1, '_>`
10 | s.spawn(|| thread_function(&mut value));
| ---------------------------------------
| | | |
| | | first borrow occurs due to use of `value` in closure
| | first mutable borrow occurs here
| argument requires that `value` is borrowed for `'1`
11 | s.spawn(|| thread_function(&mut value));
| ^^ ----- second borrow occurs due to use of `value` in closure
| |
| second mutable borrow occurs here
For more information about this error, try `rustc --explain E0499`.
It’s our old friend/enemy shared mutability!
How about a RefCell…
fn thread_function(arg: &std::cell::RefCell<i32>) {
for _ in 0..1_000_000 {
let mut p = arg.borrow_mut();
*p += 1;
}
}
fn main() {
let mut value = std::cell::RefCell::new(0);
std::thread::scope(|s| {
s.spawn(|| thread_function(&value));
s.spawn(|| thread_function(&value));
});
println!("value = {}", value.borrow());
}Oh come on…
error[E0277]: `RefCell<i32>` cannot be shared between threads safely
--> src/main.rs:11:17
|
11 | s.spawn(|| thread_function(&value));
| ----- ^^^^^^^^^^^^^^^^^^^^^^^^^^ `RefCell<i32>` cannot be shared between threads safely
| |
| required by a bound introduced by this call
|
= help: the trait `Sync` is not implemented for `RefCell<i32>`, which is required by `{closure@src/main.rs:11:17: 11:19}: Send`
= note: if you want to do aliasing and mutation between multiple threads, use `std::sync::RwLock` instead
= note: required for `&RefCell<i32>` to implement `Send`
note: required because it's used within this closure
--> src/main.rs:11:17
|
11 | s.spawn(|| thread_function(&value));
| ^^
note: required by a bound in `Scope::<'scope, 'env>::spawn`
--> /home/mrg/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/thread/scoped.rs:196:28
|
194 | pub fn spawn<F, T>(&'scope self, f: F) -> ScopedJoinHandle<'scope, T>
| ----- required by a bound in this associated function
195 | where
196 | F: FnOnce() -> T + Send + 'scope,
| ^^^^ required by this bound in `Scope::<'scope, 'env>::spawn`
For more information about this error, try `rustc --explain E0277`.
What is Send?
- It is a marker trait with no methods
- We use it to mark types which are safe to send between threads
pub unsafe auto trait Send { }What is Sync?
- It is a marker trait with no methods
- We use it to mark types where it is safe to send their references between threads
- A type
TisSyncif and only if&TisSend
pub unsafe auto trait Sync { }Is there a Sync version of RefCell?
Yes, several - and the error message suggested one: std::sync::RwLock.
There’s also the slightly simpler std::sync::Mutex.
Using a Mutex
fn thread_function(arg: &std::sync::Mutex<i32>) {
for _ in 0..1_000_000 {
let mut p = arg.lock().unwrap();
*p += 1;
}
}
fn main() {
let value = std::sync::Mutex::new(0);
std::thread::scope(|s| {
s.spawn(|| thread_function(&value));
s.spawn(|| thread_function(&value));
});
println!("value = {}", value.lock().unwrap());
}Why the unwrap?
- The
Mutexis locked onlock() - It is unlocked when the value returned from
lock()is dropped - What if you
panic!whilst holding the lock? - -> The next
lock()will returnErr(...) - You can basically ignore it (the panic is a bigger issue…)
What about Rc<T>?
That’s not thread-safe either. Use std::sync::Arc<T>.
fn thread_function(arg: &std::sync::Mutex<i32>) {
for _ in 0..1_000_000 {
let mut p = arg.lock().unwrap();
*p += 1;
}
}
fn main() {
let value = std::sync::Arc::new(std::sync::Mutex::new(0));
let t1 = std::thread::spawn({
let value = value.clone();
move || thread_function(&value)
});
let t2 = std::thread::spawn({
let value = value.clone();
move || thread_function(&value)
});
let _ = t1.join();
let _ = t2.join();
println!("value = {}", value.lock().unwrap());
}Atomic Values
- Locking things is fairly … heavyweight
- Are there integers which just work when used across threads?
- … which just support shared mutability?
- Yes: See https://doc.rust-lang.org/std/sync/atomic
Methods on Atomics
- We have
AtomicBool,AtomicPtr, and 10 sizes of Atomic integer load()andstore()fetch_add()andfetch_sub()compare_exchange()- etc
Note:
loadandstorework as expectedfetch_addwill add a value to the atomic, and return its old valuefetch_subwill subtract a value from the atomic, and return its old valuecompare_exchangewill swap an atomic for some new value, provided it is currently equal to some given existing value- All these functions require an
Ordering, which explains whether you are only concerned about this value, or other operations in memory which should happen before or after this atomic access; e.g. when taking a lock.
An Example
We highly recommend “Rust Atomics and Locks” by Mara Bos for further details.
use std::sync::atomic::{Ordering, AtomicI32};
fn thread_function(arg: &AtomicI32) {
for _ in 0..1_000_000 {
arg.fetch_add(1, Ordering::Relaxed);
}
}
fn main() {
let value = AtomicI32::new(0);
std::thread::scope(|s| {
s.spawn(|| thread_function(&value));
s.spawn(|| thread_function(&value));
});
println!("value = {}", value.load(Ordering::Relaxed));
}Spawning Threads and Scoped Threads
Platform Differences - Windows
- On Windows, a Process is just an address space, and it has one Thread by default.
- You can start more Threads
HANDLE CreateThread(
/* [in, optional] */ LPSECURITY_ATTRIBUTES lpThreadAttributes,
/* [in] */ SIZE_T dwStackSize,
/* [in] */ LPTHREAD_START_ROUTINE lpStartAddress, // <<-- function to run in thread
/* [in, optional] */ __drv_aliasesMem LPVOID lpParameter, // <<-- context for thread function
/* [in] */ DWORD dwCreationFlags,
/* [out, optional] */ LPDWORD lpThreadId
);
Platform Differences - POSIX
- On POSIX, a Process includes one thread of execution.
- You can start more Threads, typically using the POSIX Threads API
int pthread_create(
pthread_t *restrict thread,
const pthread_attr_t *restrict attr,
void *(*start_routine)(void *), // <<-- function to run in thread
void *restrict arg // <<-- context for thread function
);
Rusty Threads
The Rust thread API looks like this:
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T + Send + 'static,
T: Send + 'static,Using spawn
- You could pass a function to
std::thread::spawn. - In almost all cases you pass a closure
use std::{thread, time};
fn main() {
let thread_handle = thread::spawn(|| {
thread::sleep(time::Duration::from_secs(1));
println!("I'm a thread");
});
thread_handle.join().unwrap();
}Why no context?
There’s no void* p_context argument, because closures can close-over local variables.
use std::thread;
fn main() {
let number_of_loops = 5; // on main's stack
let thread_handle = thread::spawn(move || {
for _i in 0..number_of_loops { // captured by value, not reference
println!("I'm a thread");
}
});
thread_handle.join().unwrap();
}Note:
Try changing this move closure to a regular referencing closure.
Context lifetimes
However, the thread might live forever…
use std::{sync::Mutex, thread};
fn main() {
let buffer: Mutex<Vec<i32>> = Mutex::new(Vec::new());
let thread_handle = thread::spawn(|| {
for i in 0..5 {
// captured by reference, does not live long enough
// buffer.lock().unwrap().push(i);
}
});
thread_handle.join().unwrap();
let locked_buffer = buffer.lock();
println!("{:?}", &locked_buffer);
}
Making context live forever
If a thread can live forever, we need its context to live just as long.
use std::{sync::{Arc, Mutex}, thread};
fn main() {
let buffer = Arc::new(Mutex::new(Vec::new()));
let thread_buffer = buffer.clone();
let thread_handle = thread::spawn(move || {
for i in 0..5 {
thread_buffer.lock().unwrap().push(i);
}
});
thread_handle.join().unwrap();
let locked_buffer = buffer.lock().unwrap();
println!("{:?}", &locked_buffer);
}Tidying up the handle
- In Rust, functions take expressions
- Blocks are expressions…
let thread_buffer = buffer.clone();
let thread_handle = thread::spawn(
move || {
for i in 0..5 {
thread_buffer.lock().unwrap().push(i);
}
}
);Tidying up the handle
- In Rust, functions take expressions
- Blocks are expressions…
let thread_handle = thread::spawn({
let thread_buffer = buffer.clone();
move || {
for i in 0..5 {
thread_buffer.lock().unwrap().push(i);
}
}
});Note:
This clearly limits the visual scope of the thread_buffer variable, to match the logical scope caused by the fact it is transferred by value into the closure.
Scoped Threads
As of 1.63, we can say the threads will all have ended before we carry on our calling function.
use std::{sync::Mutex, thread};
fn main() {
let buffer = Mutex::new(Vec::new());
thread::scope(|s| {
s.spawn(|| {
for i in 0..5 {
buffer.lock().unwrap().push(i);
}
});
});
let locked_buffer = buffer.lock().unwrap();
println!("{:?}", &locked_buffer);
}Advanced Strings
There are several different kinds of strings in Rust.
Most common are String and &str.
String
- Owns the data it stores, and can be mutated freely
- The bytes it points at exist on the heap
- Does not implement
Copy, but implementsClone
&str
- A “string slice reference” (or just “string slice”)
- Usually only seen as a borrowed value
- The bytes it points at may be anywhere: heap, stack, or in read-only memory
Creation
fn main() {
// &'static str
let this = "Hello";
// String
let that: String = String::from("Hello");
// &str
let other = that.as_str();
}When to Use What?
Stringis the easiest to use when starting out. Refine later.Stringowns its data, so works well as a field of astructorenum.&stris typically used in function arguments.
Deref Coercion
Just because multiple types exist doesn’t mean they can’t work in harmony.
fn main() {
let part_one = String::from("Hello ");
let part_two = String::from("there ");
let whole = part_one + &part_two + "world!";
println!("{}", whole);
}This is because String s implement Deref<Target=str> .
Exotic String types
-
OsStrandOsStringmay show up when working with file systems or system calls. -
CStrandCStringmay show up when working with FFI.
The differences between [Os|C]Str and [Os|C]String are generally the same as the normal types.
OsString & OsStr
These types represent platform native strings. This is necessary because Unix and Windows strings have different characteristics.
Behind the OsString Scenes
- Unix strings are often arbitrary non-zero 8-bit sequences, usually interpreted as UTF-8.
- Windows strings are often arbitrary non-zero 16-bit sequences, usually interpreted as UTF-16.
- Rust strings are always valid UTF-8, and may contain
NULbytes.
OsString and OsStr bridge this gap and allow for conversion to and from String and str.
Note:
In particular, UNIX file paths are not required to be valid UTF-8 and you might encounter such paths when looking at someone’s disk.
Windows file paths are also not required to be valid UTF-16 (i.e. might contain invalid surrogate pairs) and you might encounter such paths when looking at someone’s disk.
CString & CStr
These types represent valid C compatible strings.
They are predominantly used when doing FFI with external code.
It is strongly recommended you read all of the documentation on these types before using them.
Common String Tasks
Splitting:
fn main() {
let words = "Cow says moo";
let each: Vec<_> = words.split(" ").collect();
println!("{:?}", each);
}Common String Tasks
Concatenation:
fn main() {
let animal = String::from("Cow");
let sound = String::from("moo");
let words = [&animal, " says ", &sound].concat();
println!("{:?}", words);
}Common String Tasks
Replacing:
fn main() {
let words = "Cow says moo";
let replaced = words.replace("moo", "roar");
println!("{}", replaced);
}Accepting String or str
It’s possible to accept either rather painlessly:
fn accept_either<S>(thing: S) -> String
where S: AsRef<str> {
String::from("foo") + thing.as_ref()
}
fn main() {
println!("{}", accept_either("blah"));
println!("{}", accept_either(String::from("blah")));
}Raw String Literals
- Starts with
rfollowed by zero or more#followed by" - Ends with
"followed by the same number of# - Can span multiple lines, leading spaces become part of the line
- Escape sequences are not processed
fn main () {
let json = r##"
{
"name": "Rust Analyzer",
"brandColor": "#5bbad5"
}
"##;
assert_eq!(r"\n", "\\n");
}Byte String Literals
- not really strings
- used to declare static byte slices (have a
&[u8]type)
fn main() {
let byte_string: &[u8] = b"allows ASCII and \xF0\x9F\x98\x80 only";
println!("Can Debug fmt but not Display fmt: {:?}", byte_string);
if let Ok(string) = std::str::from_utf8(byte_string) {
println!("Now can Display '{}'", string);
}
}Building Robust Programs with Kani
Rust Guarantees are Very Strong
- No
null-dereferencing - No uninitialized memory access
- No use-after-free
- No double-free
- No data races
Some bits can still be tricky
- Numbers, both integer and floating point
- Some operations can
panic! - FFI, unsafe code
IEEE 754 Floating point numbers
NaN- propagates through operations
x + NaN => NaN - breaks equality symmetry (
NaN != NaN)
- propagates through operations
- Cancellation
- subtraction of nearly equal operands may cause extreme loss of accuracy
- Division Safety test is difficult
- Limited exponent range leads to overflows and underflows
Integers in Rust
a + bcan overflow- triggers a
panicat runtime in debug mode - wraps around in release mode
- this is customizable!
- triggers a
a.checked_add(b)produces anOptiona.overflowing_add(b)produces a(value, overflow_flag)a.saturating_add(b)clamps the value within theMIN..=MAXrangea.wrapping_add(b)allows wraparounds withoutpanic- most people would still prefer writing code using operators
Panics
- “Does my program
panic?” is a hard question in Rust #[no_std]-only?panic-never- triggers a linker error if there’s panicking code path in the binary
- limited use: Standard Library and 3rd party crates have panicking code
clippyhas lints against well-known panicking APIs in the Standard Library- No easy way to list all panicking call-sites across all dependencies
Unsafe Rust
ptr.as_ref()producesOption<&T>- can prevent
null-dereferencing - cannot guarantee that the pointer is well-aligned / points to correct type
- can prevent
- lifetime information can be lost
Verifying program’s behavior
- Static analysis tools:
clippy - Testing
Generative testing
“Let’s come up with many potential program inputs
and observe program behavior“
Fuzz testing
- Produce essentially random inputs
- Often context-aware.
- Time budget
- “run the test X times” (X is often in 10_000s)
- Outcomes are non-deterministic
Property-based testing
- Generate the complete set of potential input combinations.
- Test time often grows non-linearly
- Time limit can prevent it from finding bugs
- Still selects values at random to try to observe different behaviors earlier.
- Observe different behavior => explore related input combinations to produce minimal test case.
Model Checking
- Aware of your code structure
- Including hidden code paths like panics
- Builds a model of all of your program’s states
- Uses SAT / SMT solver to prove the validity of program behavior
- Building a model of your code may take a long time
Generative testing is a spectrum
- Fuzzing
- Easier to set up
- May miss bugs
- Property testing
- Middle ground
- Model Checking
- Harder to apply
- Proves correctness
Installing Kani
cargo install --locked kani-verifier
cargo kani setup
Note: Natively runs on x86-64 Linux, and Intel and Apple Silicon macOS Windows users can run the example in a dev container.
How to use Kani 1
cargo new --lib hello-kani
cd hello-kani
cargo add --dev kani-verifier
How to use Kani 2
#[cfg(kani)]
mod proofs {
use super::*;
#[kani::proof]
fn verify_add() {
let a: u64 = kani::any();
let b: u64 = kani::any();
let result = add(a, b);
// Assert that the result does not overflow
assert!(result >= a);
assert!(result >= b);
}
}Note: while the word “proof” is used in code Kani calls its tests “harnesses” because technically the function verify_add acts as a test harness that runs generated tests.
How to use Kani 3
cargo kani
...
SUMMARY:
** 1 of 3 failed
Failed Checks: attempt to add with overflow
File: "src/lib.rs", line 2, in add
VERIFICATION:- FAILED
...
How to use Kani 4
cargo kani -Z concrete-playback --concrete-playback=print
/// Test generated for harness `proofs::verify_add`
///
/// Check for `assertion`: "attempt to add with overflow"
#[test]
fn kani_concrete_playback_verify_add_7155943916565760311() {
let concrete_vals: Vec<Vec<u8>> = vec![
// 13835058055282163713ul
vec![1, 0, 0, 0, 0, 0, 0, 192],
// 9223372036854775804ul
vec![252, 255, 255, 255, 255, 255, 255, 127],
];
kani::concrete_playback_run(concrete_vals, verify_add);
}How to use Kani 5
#![allow(unused)]
fn main() {
#[cfg(kani)]
mod proofs {
use super::*;
#[test]
fn kani_concrete_playback_verify_add_7155943916565760311() {
//
}
}
}
# run playback tests
cargo kani playback -Z concrete-playback
Rough edges
kanicrate- not published on
crates.io - the crate is injected in your binary when you run
cargo kani - some of kani dependencies rely on nightly-only code
- confuse Rust Analyzer / IntelliJ code assists
- not published on
- out-of-the-box Developer Experience is very painful
- but can be fixed in VSCode!
Let’s fix it! - VSCode
- Rust Analyzer
- Kani extension
- CodeLLDB or Microsoft C/C++ (on Windows) for debugging
- You can use Docker and DevContainers on unsupported platforms
Let’s fix it! - Cargo.toml
[dev-dependencies]
kani-verifier = "0.56.0"
[dependencies]
# enables autocomplete and code inspections for `kani::*` api
kani = { version = "0.56", git = "https://github.com/model-checking/kani", tag = "kani-0.56.0", optional = true }
# removes warnings about unknown `cfg` attributes
[lints.rust]
unexpected_cfgs = { level = "warn", check-cfg = ['cfg(rust_analyzer)', 'cfg(kani)'] }
Let’s fix it! - .vscode/settings.json
{
// tell Rust Analyzer that Kani features are active
"rust-analyzer.cargo.features": ["kani"]
}
Let’s fix it! - *.rs
Kani proc macros appear broken to Rust Analyzer
#[cfg_attr(not(rust_analyzer), cfg(kani))]
mod proofs {
use super::*;
#[cfg_attr(not(rust_analyzer), kani::proof)]
fn verify_add() {
}
#[test]
fn kani_concrete_playback_verify_add_7155943916565760311() {
}
}Full “hello world” example in our repository
See example-code/kani/kani-hello-world
Other Kani features
- Functional contracts
- VSCode extension to run (and debug!) playbacks
- Ability to fine-tune tests:
#[kani::unwind(<number>)]#[kani::stub(<original>, <replacement>)]#[kani::solver(<solver>)]kani::any_where(<predicate>)
Feature Highlight: Function contracts
- Define a contract for a function
- Verify the function behavior
- Optional: Let Kani stub out the function
when checking larger body of code
Function contracts
// tell Kani what kind of values to generate
#[cfg_attr(kani, kani::requires(min != 0 && max != 0))]
// tell Kani about the expectations
#[cfg_attr(kani, kani::ensures(|&result: &u8| {
result != 0
&& max % result == 0
&& min % result == 0
};
))]
// only needed if the function is recursive
#[cfg_attr(kani, kani::recursion)]
pub fn gcd(max: u8, min: u8) -> u8 {Verifying contracts
#[kani::proof_for_contract(gcd)]
fn check_gcd() {
let max: u8 = kani::any();
let min: u8 = kani::any();
gcd(max, min);
}Using of verified contracts in other proofs
#[kani::proof]
#[kani::stub_verified(gcd)]
fn check_reduce_fraction() {
let numerator: u8 = kani::any();
let denominator: u8 = kani::any();
// uses `gcd`
reduce_fraction(numerator, denominator);
}Limitations
- No multithreading support
- No support for atomic operations
- No support for async runtimes (but the syntax is supported)
- No inline assembly
- No use of
panic!,catch_unwind, andresume_unwindfor flow control - Loops and deep recursion balloon the number of states that require inspection
- …
Test-friendly code
- Isolate IO
- Isolate synchronization, message passing,
await - Isolate target-dependent code
By making our code more test-friendly we make it Kani-friendly, too!
What code to test
- Numerical code
- Parsers, serialization and deserialization code
- Decision trees, complex conditional logic
unsafe
Dealing with Unwrap
Handling your errors
- Rust is intentionally strict: when failure modes happen, you have to decide how to handle them right there
- Recall:
Option<T>gives you information on if your operation produced something or nothingResult<T, E>lets you know if something succeeded or something else (E) happened
- We can propagate the appropriate error context by transforming one into the other and vice versa
Unwrap -> ?
.unwrap()’ing bothOptionandResultseems like an easy way out- Switching from
.unwrap()calls often leads to changes in function signatures, and the refactoring becomes wider and difficult with time and code
Instead, prefer using the early return ? operator where possible, or at least .expect()
? Examples
Let’s see how we can get to ? as quickly as possible in cases where
- You have many eager returns
- You have
matchstatements where all cases must succeed to go forward
? vs Eager: Before
? turns this
fn write_info(info: &Info) -> io::Result<()> {
// Early return on error
let mut file = match File::create("my_best_friends.txt") {
Err(e) => return Err(e),
Ok(f) => f,
};
if let Err(e) = writeln!("name: {}", info.name) {
return Err(e)
}
if let Err(e) = writeln!("age: {}", info.age) {
return Err(e)
}
if let Err(e) = writeln!("rating: {}", info.rating) {
return Err(e)
}
Ok(())
}? vs Eager Returns: After
Into this
fn write_info(info: &Info) -> io::Result<()> {
let mut file = File::create("my_best_friends.txt")?;
// Early return on error
writeln!("name: {}", info.name)?;
writeln("age: {}", info.age)?;
writeln!("rating: {}", info.rating))?;
Ok(())
}? vs Pattern Matching
As well as this
#![allow(unused)]
fn main() {
fn add_last_numbers(stack: &mut Vec<i32>) -> Option<i32> {
let a = stack.pop();
let b = stack.pop();
match (a, b) {
(Some(x), Some(y)) => Some(x + y),
_ => None,
}
}
}? vs Pattern Matching 2
#![allow(unused)]
fn main() {
fn add_last_numbers(stack: &mut Vec<i32>) -> Option<i32> {
Some(stack.pop()? + stack.pop()?)
}
}We prefer using ? instead of highly nested pattern matching
Option into Result: Before
- Sometimes we return
Option, but we want aResultbecause it adds more context:
struct UserId {
name: String,
num: u32,
}
fn find_user(username: &str) -> Option<&str> {
let f = match std::fs::File::open("/etc/password") {
// ...
}
}- We will use
or_else()to changeOption<T>intoResult<T, E>
Option into Result: After
struct UserId {
name: String,
num: u32,
}
pub fn find_user(username: &str) -> Result<UserId, i32> {
let f = std::fs::File::open("/etc/passwd")
.or_else(|_| Err(0))?;
Ok(UserId{name: "John".into(), num: 1})
}- As applications grow, they tend to have a higher proportion of
Results rather thanOptions
Result to Result: Before
- We can process the context of the error to produce something more meaningful than
i32 - Concretely: use
map_err()on aResult<_, A>to get aResult<_, B>
pub fn find_user(username: &str) -> Result<UserId, String> {
let f = std::fs::File::open("/etc/passwd")
.map_err(|e| format!("Failed to open password file: {:?}", e))?;
// ...
}Result to Result: After
- However,
Stringy based errors are a code smell - Prefer idiomatic error types that use
enums:
enum MyError {
BadPassword(String),
IncorrectID,
// ...
}
impl std::error::Error for MyError {}
pub fn find_user(username: &str) -> Result<UserId, MyError> {
let f = std::fs::File::open("/etc/passwd")
.map_err(|e| MyError::BadPassword(format!("Failed to open password file: {:?}", e)))?;
// ...
}To be ? or not to be ?
- Using
?means we deal with the error right now, but not right here - Don’t apply
?blindly. There may be cases where other choices make sense- It’s undesirable for long-running processes, or if we don’t care about the failure
- Handle the error instead instead of propagating it
- Combine multiple
Results/Options via pattern matching
When to not ?: Before
for stream in tcp_listener.incoming() {
// Should I use `stream?` here?
// No, because my whole server would stop accepting connections
let Ok(stream) = stream else {
eprintln("Bad connection");
continue;
}
}When to not ?: After
if let (Ok(a), Ok(b)) = (job_a(), job_b()) {
// run this code only when both jobs succeeded
}-
If you only care about moving on in the happy path, try judicious pattern matching with
if lets -
Note: This throws away and ignores errors from
job_a()andjob_b()!
Iterators: Result into Option
- Iterators usually just care about processing or finding certain elements and throwing out the uninteresting data
- Use
.filter_map()for this:
let a = ["1", "two", "NaN", "four", "5"];
// I don't care about bad results, I filter them out
let mut iter = a.iter()
.filter_map(|s| s.parse::<i32>()
.ok());
// Instead of
let mut iter = a.iter()
.map(|s| s.parse())
.filter(|s| s.is_ok())
.map(|s| s.unwrap());- Concretely, this means turning
Result<T, E>into anOption<T>by using the.ok()method
Iterators and collecting errors
OptionandResultsupport transposition: they can wrap collections or be elements of them- If you want to process each error separately, use
Vec<Result<T, _>>:
let vec_of_results: Vec<Result<i32, _>> = inputs.iter()
.map(|s| s.parse::<i32>())
.collect();Iterators and collecting errors 2
- If you only care about all of them succeeding, you can
.collect()them into aResult<Vec<i32>, _>:
let result_of_vec: Result<Vec<i32>, _> = inputs.iter()
.map(|s| s.parse::<i32>())
.collect()?;Which way to wrap?
In general, we prefer wrapping the collection with an error (Result<Vec<T>, _> and Option<Vec<T>> )
rather than the other way around
Recap
We’ve gone over many transformations:
Option<T>toResult<T, E>and vice versaResult<T, E>toResult<T, U>
Many more variants exist depending on if you ignore the error, replace its value, provide a default, etc.
To deal with references, use .as_ref().
As Ref
It’s arguably always better to pass Option<&T> than &Option<T> if T is immutable.
If your function accepts Option<&T> and you have foo: &T, you can pass in
foo.as_ref(),foo,Some(&foo)andSome(foo)
But if your function accepts &Option<T>, you can only accept
&fooand&Some(foo)
which is more restrictive
Useful References
- Result’s stdlib docs
- Option’s stdlib docs
- A very useful diagram is given in the Effective Rust book for all these conversions and methods
Conclusion
Worry about
Result<T, E><=>Option<T>andResult<T, E><=>Result<T, F>
until you need something else
Debugging Rust
tl;dr
VSCode + CodeLLDB
The best debugging experience on Windows, Linux, and macOS
Honorable Mentions
- IntelliJ Rust
rr/ Pernosco for time-traveling and postmortem debugging
How Debuggers Work
Debuggers use special metadata embedded into executable to correctly match bits of machine code to lines of source code, areas of memory to variables and their types, etc.
Kinda like Source Maps for JavaScript.
How Debuggers Work
Two things have to happen for a debugger to work and provide decent developer experience:
- The compiler has to emit debug info.
- The debugger has to be modified / extended to understand this information.
How Debuggers Work
Two things have to happen for a debugger to work and provide decent developer experience:
- The compiler has to emit debug info.
- The debugger has to be modified / extended to understand this information.
Compiler
rustc uses llvm which emits debug info in DWARF or PDB format.
- PDB is produced by
windows-msvctoolchains (likex86_64-pc-windows-msvc) - DWARF is used by all other toolchains, including GNU toolchains on Windows (like
x86_64-pc-windows-gnu)
DWARF
- Open standard.
- Very C/C++ specific.
- Has custom field types for other languages to use.
- Rust tries to reuse existing C/C++ fields where possible, so many debuggers work out of the box.
- A companion to ELF…
Extending DWARF
DWARF standard is growing organically over time and largely implementation driven.
Extending DWARF
- Come up with a new name for Rust-specific DWARF field.
- Change the compiler to emit new debug info and use this field.
- Change a debugger to understand this new field.
- Propose the new field to be standardized, so that other debuggers can reuse the field, too.
Standardizing takes almost no time due to how few people in the world actually work on DWARF.
PDB
- Proprietary format with no documentation.
- Like DWARF is very C/C++ centric.
- Harder to extend.
- Rust tries to reuse C/C++ fields as much as possible, so debugging is still reasonable.
You may have a better experience debugging Rust on macOS or Linux than on Windows, because of PDB.
How Debuggers Work
Two things have to happen for a debugger to work and provide decent developer experience:
- The compiler has to emit debug info.
- The debugger has to be modified / extended to understand this information.
Debuggers
IDEs and editors rely on these two to provide GUI debugging
GDB
- Supports a lot of languages.
- Adopts Rust-specific features quickly.
- Harder to contribute in general.
LLDB
- Default choice for Rust.
- Part of LLVM that Rust uses for compilation.
- Used to support many languages, but the team decided to focus on C, C++, and Objective C only.
- Has extension API for supporting other languages, which is not enough for Rust.
LLDB
Rust project maintains a fork of LLDB with extended support for the language.
- Part of overall LLVM fork.
- Constantly updated and well-maintained.
- Non-Rust-specific bug fixes get upstreamed to main LLVM repository
Wrappers
Rust comes with rust-gdb and rust-lldb wrappers around debuggers.
They improve visualizing Rust values printed in console.
Editors and IDEs
Rust-analyzer does not come with debugger support on its own.
Instead it relies on other editor / ide plugins for debugging support.
Prompts you to install one when you open a Rust project.
VSCode Extensions
CodeLLDB.
- LLDB-only.
- Maintains it’s own fork of Rust’s LLDB with even more Rust enhancements!
- Downloads it on first installation.
- Seamless debugging experience.
Both Microsoft C/C++ and Native Debug support GDB and LLDB.
Microsoft’s extension offers better support for displaying PDB information on Windows.
IntelliJ-Rust
- A plugin for IDEA and CLion
- Produced by JetBrain.
- Like CodeLLDB also maintains it’s own fork of Rust’s LLDB for better DX.
- Requires a JB license.
What to use?
- VSCode + CodeLLDB offer the best debugging experience across all platforms.
- Microsoft recommends CodeLLDB even for Windows use.
- IntelliJ-Rust is great if that’s your IDE of choice.
- Native Debug and Microsoft C/C++ extensions can work for you on platforms where only GDB is available.
rr
- A Linux-only terminal-based time-traveling debugger.
- Uses GDB under the hood, supports Rust.
- Pernosco - GUI debugging tool on top of
rron top ofgdb- offers Rust support, too. - May help you in very difficult situations.
Things may not work well
- PDB may result in subpar debugging experience.
- If possible try debugging your code on OSes other than Windows
- Or try using GNU-based toolchain on Windows.
- Watch expressions are limited.
- Can’t use
matchorifexpressions - Some method calls may not produce results.
- Can’t use
- Some values can’t be shown: function preferences, closures.
- Breakpoints may sometimes not work in closures and in async code.
- Trait objects and trait methods may be difficult for debugger to resolve.
When debugger fails you
- Try to isolate the code in question into smaller functions.
- Add debug logging / tracing.
- Tests.
Future
- New Rust Debugging Working Group:
- Unites people from Rust, GDB, and
rr - people from LLVM, CodeLLDB, Rust-Analyzer, and IntelliJ Rust expressed interest in helping out.🎉
- Unites people from Rust, GDB, and
- Plans:
- LLVM team is open to merge Rust-specific features into LLDB directly, may not need a Rust fork, or CodeLLDB / IntelliJ forks.
- Further expand DWARF to cover tricky Rust features like trait object method references.
Deconstructing Send, Arc, and Mutex
thread::spawn Function
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,
{
// ...
}Quick Primer on Rust Closures
- 3 categories of data
- data the closure closes over / captures: Upvars
- convenient compiler terminology
- not represented by closure type signature
- parameters
- returned value
- data the closure closes over / captures: Upvars
let upper_threshold = 20;
let outliers: Vec<_> = data.iter().copied().filter(|n| -> bool {
// `n` is a parameter, `upper_threshold` is an *upvar*
n >= upper_threshold
}).collect();Spawn closure type
F: FnOnce() -> T- closure doesn’t accept any parameters
- closure can consume upvars (“FnOnce”)
F: Send + 'static- applies to upvars
T: Send + 'static- applies to returned value
T: 'static
Two options allowed:
- the type doesn’t have any references inside (“Owned data”)
struct User { name: String }
- the references inside the type are
'staticstruct Db { connection_string: &'static str }
Why F: 'static and T: 'static?
- applies to data passed from parent thread to child thread or vice-versa
- prevents passing references to local variables
- one thread can finish before the other and such references may become invalid
+ 'staticavoids this by ensuring any references point to data that has the static lifetime (i.e. that lives forever)
T: Send
pub unsafe auto trait Send { }
automeans all types get this trait automatically- opt-out instead of opt-in
- various types in standard library implement
Sendor!Send unsafemeans you have to putunsafekeyword in front ofimplwhen implementingSendor!Send- precautionary measure
Why would one implement Send or !Send
- Rust pointers (
*const T,*mut T,NonNull<T>) are!Send- Use-case: what if the pointer comes from FFI library that assumes that all functions using this pointer are called from the same thread?
Archas aNonNull<..>inside and becomes!Sendautomatically- to override this behavior
Arcexplicitly implementsSend
- to override this behavior
Send in thread::spawn Function
F: Send and T: Send means that all data traveling from the parent thread to child thread has to be marked as Send
- Rust compiler has no inherent knowledge of threads, but the use of marker traits and lifetime annotations let the type / borrow checker prevent data race errors
Sharing data between threads
Example: Message Log for TCP Echo Server
use std::{
io::{self, BufRead as _, Write as _},
net, thread,
};
fn handle_client(stream: net::TcpStream) -> Result<(), io::Error> {
let mut writer = io::BufWriter::new(&stream);
let reader = io::BufReader::new(&stream);
for line in reader.lines() {
let line = line?;
writeln!(writer, "{}", line)?;
writer.flush()?;
}
Ok(())
}
fn main() -> Result<(), io::Error> {
let listener = net::TcpListener::bind("0.0.0.0:7878")?;
for stream in listener.incoming() {
let stream = stream?;
thread::spawn(|| {
let _ = handle_client(stream);
});
}
Ok(())
}Task
- create a log of lengths of all lines coming from all streams
let mut log = Vec::<usize>::new();log.push(line.len());
“Dream” API
fn handle_client(stream: net::TcpStream, log: &mut Vec<usize>) -> Result<(), io::Error> {
// ...
for line in ... {
log.push(line.len());
// ...
}
Ok(())
}
fn main() -> Result<(), io::Error> {
let mut log = vec![];
for stream in listener.incoming() {
// ...
thread::spawn(|| {
let _ = handle_client(stream, &mut log);
});
}
Ok(())
}Errors
error[E0373]: closure may outlive the current function, but it borrows `log`, which is owned by the current function
--> src/main.rs:26:23
|
26 | thread::spawn(|| {
| ^^ may outlive borrowed value `log`
27 | let _ = handle_client(stream.unwrap(), &mut log);
| --- `log` is borrowed here
|
--> src/main.rs:26:23
|
26 | thread::spawn(|| {
| ^^ may outlive borrowed value `log`
27 | let _ = handle_client(stream.unwrap(), &mut log);
| --- `log` is borrowed here
|
note: function requires argument type to outlive `'static`
Lifetime problem
Problem:
- local data may be cleaned up prematurely
Solution:
- move the decision when to clean the data from compile-time to run-time
- use reference-counting
Attempt 1: Rc
let mut log = Rc::new(vec![]);let mut thread_log = log.clone()now doesn’t clone the data, but simply increases the reference count- both variables now have owned type, and satisfy
F: 'staticrequirement
- both variables now have owned type, and satisfy
error[E0277]: `Rc<Vec<usize>>` cannot be sent between threads safely
Rc in Rust Standard Library
- uses
usizefor reference counting - explicitly marked as
!Send
pub struct Rc<T> {
ptr: NonNull<RcBox<T>>,
}
impl<T> !Send for Rc<T> {}
struct RcBox<T> {
strong: Cell<usize>,
weak: Cell<usize>,
value: T,
}Arc in Rust Standard Library
- uses
AtomicUsizefor reference counting - explicitly marked as
Send
pub struct Arc<T> {
ptr: NonNull<ArcInner<T>>,
}
impl<T> Send for Arc<T> {}
struct ArcInner<T: ?Sized> {
strong: atomic::AtomicUsize,
weak: atomic::AtomicUsize,
data: T,
}Rc vs Arc
ArcusesAtomicUsizefor reference counting- slower
- safe to increment / decrement from multiple threads
- With the help of marker trait
Sendand trait bounds onthread::spawn, the compiler forces you to use the correct type
Arc / Rc “transparency”
let mut log = Arc::new(Vec::new());
// how does this code work?
log.len();
// and why doesn't this work?
log.push(1);Deref and DerefMut traits
pub trait Deref {
type Target: ?Sized;
fn deref(&self) -> &Self::Target;
}
pub trait DerefMut: Deref {
fn deref_mut(&mut self) -> &mut Self::Target;
}Deref coercions
Derefcan convert a&selfreference to a reference of another type- conversion function call can be inserted by the compiler for you automatically
- in most cases the conversion is a no-op or a fixed pointer offset
- deref functions can be inlined
Targetis an associated type- can’t
deref()into multiple different types
- can’t
DerefMut: Derefallows theDerefMuttrait to reuse the sameTargettype- read-only and read-write references coerce to the references of the same type
Arc / Rc “transparency” with Deref
let mut log = Arc::new(Vec::new());
// Arc<T> implements `Deref` from `&Arc<T> into `&T`
log.len();
// the same as
Vec::len(<Arc<_> as Deref>::deref(&log));
// Arc<T> DOES NOT implement `DerefMut`
// log.push(1);
// the line above would have expanded to:
// Vec::push(<Arc<_> as DerefMut>::deref_mut(&mut log), 1);Arc and mutability
- lack of
impl DerefMut for Arcprevents accidental creation of multiple&mutto underlying data - the solution is to move mutability decision to runtime
let log = Arc::new(Mutex::new(Vec::new()));
Arcguarantees availability of data in memory- prevents memory form being cleaned up prematurely
Mutexguarantees exclusivity of mutable access- provides only one
&mutto underlying data simultaneously
- provides only one
Mutex in Action
logis passed as&and isderef-ed fromArcby the compilermutability is localized to a localguardvariableMutex::lockmethod takes&self
MutexGuardimplementsDerefandDerefMut!'_lifetime annotation is needed only because guard struct has a&Mutexinside
fn handle_client(..., log: &Mutex<Vec<usize>>) -> ... {
for line in ... {
let mut guard: MutexGuard<'_, Vec<usize>> = log.lock().unwrap();
guard.push(line.len());
// line above expands to:
// Vec::push(<MutexGuard<'_, _> as DerefMut>::deref_mut(&mut guard), line.len());
writeln!(writer, "{}", line)?;
writer.flush()?;
}
}Mutex locking and unlocking
- we
lockthe mutex for exclusive access to underlying data at runtime - old C APIs used a pair of functions to lock and unlock the mutex
MutexGuarddoes unlocking automatically when is dropped- time between guard creation and drop is called critical section
Lock Poisoning
MutexGuardin itsDropimplementation checks if it is being dropped normally or during apanicunwind- in later case sets a poison flag on the mutex
- calling
lock().unwrap()on a poisoned Mutex causespanic- if the mutex is “popular” poisoning can cause many application threads to panic, too.
PoisonErrordoesn’t provide information about the panic that caused the poisoning
Critical Section “Hygiene”
- keep it short to reduce the window when mutex is locked
- avoid calling functions that can panic
- using a named variable for Mutex guard helps avoiding unexpected temporary lifetime behavior
Critical Section Example
fn handle_client(..., log: &Mutex<Vec<usize>>) -> ... {
for line in ... {
{
let mut guard: MutexGuard<'_, Vec<usize>> = log.lock().unwrap();
guard.push(line.len());
} // critical section ends here, before all the IO
writeln!(writer, "{}", line)?;
writer.flush()?;
}
}
drop(guard)also works, but extra block nicely highlights the critical section
Lessons Learned
- careful use of traits and trait boundaries lets the compiler detect problematic multi-threading code at compile time
ArcandMutexlet the program ensure data availability and exclusive mutability at runtime where the compiler can’t predict the behavior of the programDerefcoercions make concurrency primitives virtually invisible and transparent to use- Make invalid state unrepresentable
Full Example
use std::{
io::{self, BufRead as _, Write as _},
net,
sync::{Arc, Mutex},
thread,
};
fn handle_client(stream: net::TcpStream, log: &Mutex<Vec<usize>>) -> Result<(), io::Error> {
let mut writer = io::BufWriter::new(&stream);
let reader = io::BufReader::new(&stream);
for line in reader.lines() {
let line = line?;
{
let mut guard = log.lock().unwrap();
guard.push(line.len());
}
writeln!(writer, "{}", line)?;
writer.flush()?;
}
Ok(())
}
fn main() -> Result<(), io::Error> {
let log = Arc::new(Mutex::new(vec![]));
let listener = net::TcpListener::bind("0.0.0.0:7878")?;
for stream in listener.incoming() {
let stream = stream?;
let thread_log = log.clone();
thread::spawn(move || {
let _ = handle_client(stream, &thread_log);
});
}
Ok(())
}Dependency Management with Cargo
Cargo.toml - A manifest file
[package]
name = "tcp-mailbox"
version = "0.1.0"
[dependencies]
async-std = "1" # would also choose 1.5
clap = "2.2" # would also choose 2.3
Cargo.lock - A lock file
- contains a list of all project dependencies, de-facto versions and hashes of downloaded dependencies
- when a version is yanked from
Crates.iobut you have the correct hash for it in a lock file Cargo will still let you download it and use it- still gives you warning about that version being problematic
- should be committed to your repository for applications
Dependency resolution
- uses “Zero-aware” SemVer for versioning
1.3.5is compatible with versions>= 1.3.5and< 2.0.00.3.5is compatible with versions>= 0.3.5and< 0.4.00.0.3only allows0.0.3
- allows version-incompatible transitive dependencies
- except C/C++ dependencies
- combines dependencies with compatible requirements as much as possible
- allows path, git, and custom registry dependencies
How a dependency version is selected
- for every requirement Cargo selects acceptable version intervals
[1.1.0; 1.6.0),[1.3.5, 2.0.0),[2.0.0; 3.0.0)
- Cargo checks for interval intersections to reduce the number of unique intervals
[1.3.5; 1.6.0),[2.0.0; 3.0.0)
- for every unique interval it selects the most recent available version
=1.5.18,=2.7.11
- selected versions and corresponding package hashes are written into
Cargo.lock
Dependency resolution: Example
└── my-app May install:
├── A = "1"
│ ├── X = "1" A = "1.0.17"
│ └── Y = "1.3" => B = "1.5.0"
└── B = "1" X = "2.0.3"
├── X = "2" X = "1.2.14"
└── Y = "1.5" Y = "1.8.5"
Where do dependencies come from?
- Crates.io
- Private registries (open-source, self-hosted, or hosted)
- Git and Path dependencies
- dependencies can be vendored
Notes:
- private registries
Shipyard and Kellnr will also generate API docs for you
Crates.io
- default package registry
- 100k crates and counting
- every Rust Beta release is tested against all of them every week
- packages aren’t deleted, but yanked
- if you have a correct hash for a yanked version in your
Cargo.lockyour build won’t break (you still get a warning)
- if you have a correct hash for a yanked version in your
Docs.rs
- complete API documentation for the whole Rust ecosystem
- automatically publishes API documentation for every version of every crate on Crates.io
- documentation for old versions stays up, too. Easy to switch between versions.
- links across crates just work
Other kinds of dependencies
- git dependencies
- both
git+httpsandgit+sshare allowed - can specify branch, tag, commit hash
- when downloaded by Cargo exact commit hash used is written into
Cargo.lock
- both
- path dependencies
- both relative and absolute paths are allowed
- common in workspaces
C Libraries as dependencies
- Rust can call functions from C libraries using
unsafecode- integrate with operating system APIs, frameworks, SDKs, etc.
- talk to custom hardware
- reuse existing code (SQLite, OpenSSL, libgit2, etc.)
- building a crate that relies on C libraries often requires customization
- done using
build.rsfile
- done using
build.rs file
- compiled and executed before the rest of the package
- can manipulate files, execute external programs, etc.
- download / install custom SDKs
- call
cc,cmake, etc. to build C++ dependencies - execute
bindgento generate Rust bindings to C libraries
- output can be used to set Cargo options dynamically
println!("cargo:rustc-link-lib=gizmo"); println!("cargo:rustc-link-search=native={}/gizmo/", library_path);
-sys crates
- often Rust libraries that integrate with C are split into a pair of crates:
library-name-sys- thin wrapper around C functions
- often all code is autogenerated by
bindgen
library-name- depends on
library-name-sys - exposes convenient and idiomatic Rust API to users
- depends on
- examples:
opensslandopenssl-syszstdandzstd-sysrusqliteandlibsqlite3-sys
Deref Coercions
Motivation
Why does the following work?
struct Point {
x: i32,
y: i32
}
fn main() {
let boxed_p = Box::new(Point { x: 1, y: 2 });
println!("{}", boxed_p.x);
}Box doesn’t have a field named “x”!
Auto-Dereferencing
Rust automatically dereferences in certain cases. Like everything else, it must be explicitly requested:
- Through a call or field access using the
.operator - By explicitly dereferencing through
* - When borrowing through
& - This sometimes leads to the ugly
&*-Pattern
This makes wrapper types very ergonomic and easy to use!
Dereferencing is described by the Deref and DerefMut-Traits.
impl<T> std::ops::Deref for Box<T> {
type Target = T;
fn deref(&self) -> &T {
todo!()
}
}This call is introduced when dereferencing is requested.
Important deref behaviours
- String -> &str
- Vec<T> -> &[T]
Functions that don’t modify the lengths of a String or a Vector should accept a slice instead. The memory layout is chosen so that this is cost free.
fn print_me(message: &str) { println!("{}", message); }
fn main() {
print_me("Foo");
let a_string = String::from("Bar");
print_me(&a_string);
print_me(a_string.as_str())
}Basic Design Patterns
.clone() before Lifetime Annotations
- As a beginner, use
.clone()to overcome compiler struggle. - It is alright! Refactor later.
String before &str
- Use “owned” types before references.
- It is alright! Refactor later.
String concatenation: Use format!()
- Owned type
Stringcan be generated easily. let s: String = format!("No fear from {}", "Rust Strings")
Clippy is your friend in linting
- A collection of lints to catch common mistakes and improve your Rust code.
- Installation:
rustup component add clippy - Run:
cargo clippy - Documentation: https://rust-lang.github.io/rust-clippy/stable/index.html
Pattern: From<T>, Into<T>
Conversion of one Type into another.
If X is From<T>, then T is Into<X> automatically.
The usage depends on the context.
Pattern: From<T>, Into<T> - Example
fn main() {
let string = String::from("string slice");
let string2: String = "string slice".into();
}Pattern: What does ? do?
use std::fs::File;
use std::io::{self, Write};
enum MyError {
FileWriteError,
}
impl From<io::Error> for MyError {
fn from(e: io::Error) -> MyError {
MyError::FileWriteError
}
}
fn write_to_file_using_q() -> Result<(), MyError> {
let mut file = File::create("my_best_friends.txt")?;
file.write_all(b"This is a list of my best friends.")?;
println!("I wrote to the file");
Ok(())
}
// This is equivalent to:
fn write_to_file_using_match() -> Result<(), MyError> {
let mut file = File::create("my_best_friends.txt")?;
match file.write_all(b"This is a list of my best friends.") {
Ok(v) => v,
Err(e) => return Err(From::from(e)),
}
println!("I wrote to the file");
Ok(())
}
fn main() {}Pattern: AsRef<T>
Reference-to-reference-conversion. Indicates that a type can easily produce references to another type.
Pattern: AsRef<T> - Example
use std::fs::File;
use std::path::Path;
use std::path::PathBuf;
fn main() {
open_file(&"test");
let path_buf = PathBuf::from("test");
open_file(&path_buf);
}
fn open_file<P: AsRef<Path>>(p: &P) {
let path = p.as_ref();
let file = File::open(path);
}Pattern: Constructor new()
- No constructors, but there is a convention.
- An associated function to construct new “instances”.
- Use
Defaulttrait. Try using#[derive(Default)]first.
#![allow(unused)]
fn main() {
pub struct Stuff {
value: i64,
}
impl Stuff {
/// constructor by convention
fn new(value: i64) -> Self {
Self { value: value }
}
}
}Pattern: NewType
- Use Rust type system to convey meaning to the user.
- Especially for Types that should be similar to other Types.
- Also used to
implexternal Traits on external Types
#![allow(unused)]
fn main() {
struct MyString(String);
impl MyString {
//... my implementations for MyString
}
}Pattern: Extending external Types
- Recall that at least one of Trait or Type should be local to
impl. - This pattern allows you to extend external Type using a local Trait.
trait VecExt {
fn magic_number(&self) -> usize;
}
impl<T> VecExt for Vec<T> {
fn magic_number(&self) -> usize {
42
}
}
fn main() {
let v = vec![1, 2, 3, 4, 5];
println!("Magic Number = {}", v.magic_number());
}Pattern: Narrowing variable’s scope
- Shadowing allows you to redefine a variable with
letkeyword again. - Use it to get the inner Type, say in
Option. - Use it to your advantage to make variable immutable after it’s served its purpose.
// Get the inner type from Option
let array = [1, 2, 3, 4];
let item = array.get(1);
if let Some(item) = item {
println!("{:?}", item);
}
// Use shadowing to make the variable immutable outside of
// where it needs to be mutable
let mut data = 42;
// change the data
data += 1;
// Shadow using `let` again
let data = data;
// data is immutable from now onDocumentation
rustdoc
Rust provides a standard documentation tool called rustdoc. It is commonly used through cargo doc.
Because of this Rust code is almost always documented in a common format.
std Documentation
The standard library documentation is hosted at https://doc.rust-lang.org/std/.
A local, offline version can be opened with:
$ rustup doc --std
Crate Documentation
Documentation for crates hosted on http://crates.io/ can be found at https://docs.rs/.
Some crates may also have other documentation found via the “Documentation” link on their listing in http://crates.io/.
Example: A Module
https://doc.rust-lang.org/std/vec
This page documents the vec module.
It starts with some examples, then lists any structs, traits, or functions the module exports.
How is it Generated?
rustdoc can read Rust code and Markdown documents.
//! and /// comments are read as Markdown.
#![allow(unused)]
fn main() {
//! Module documentation. (e.g. the 'Examples' part of `std::vec`).
/// Document functions, structs, traits and values.
/// This documents a function.
fn function_with_documentation() {}
// This comment will not be shown as documentation.
// The function itself will be.
fn function_without_documentation() {}
}Example: Components
https://doc.rust-lang.org/std/string/#structs
Example: Functions
https://doc.rust-lang.org/std/string/struct.String.html#method.new
Code Examples
By default code blocks in documentation are tested.
#![allow(unused)]
fn main() {
/// ```rust
/// assert_eq!(always_true(), true)
/// ```
fn always_true() -> bool { true }
}No-Run Examples
This code is marked ‘do not run’, as it doesn’t terminate.
#![allow(unused)]
fn main() {
/// ```rust,no_run
/// serve();
/// ```
fn serve() -> ! { loop {} }
}Navigation
The arguments and return types of functions are links to their respective types.
The sidebar on the left offers quick navigate to other parts of the module.
Cargo integration
This command builds and opens the docs to your current project:
$ cargo doc --open
Normally only pub items are documented. You can change this:
$ cargo doc --document-private-items --open
Drop, panic, and abort
What happens in detail when values drop?
Drop-Order
Rust generally guarantees drop order (RFC1857)
Drop-Order
- Values are dropped at the end of their scope
- The order is the reverse introduction order
- Unbound values drop immediately
- Structure fields are dropped first to last
Destructors
Sometimes, certain actions must be taken before deallocation.
For this, the Drop trait can be implemented.
struct LevelDB {
handle: *mut leveldb_database_t
}
impl Drop for LevelDB {
fn drop(&mut self) {
unsafe { leveldb_close(self.handle) };
}
}Warning!
Destructors cannot return errors.
Also possible
Explicit destruction of a value through a consuming function. This cannot be statically enforced currently.
Implementing a Drop-bomb (a failing destructor) can make sure this error is caught early.
Panics
Rust also has another error mechanism: panic!
fn main() {
panicking_function();
}
fn panicking_function() {
panic!("gosh, don't call me!");
}In case of a panic, the following happens:
- The current thread immediately halts
- The stack is unwound
- All affected values are dropped and their destructors run
Panics are implementation-wise similar to C++-Exceptions, but should only be used for fatal errors. They cannot be (normally) caught.
The affected thread dies.
Catching Panics
Panicking across FFI-boundaries is undefined behaviour. In these cases, panics must be caught. For cases like this, there are std::panic::catch-unwind and std::panic::resume-unwind.
Hooks
std::panic::set_hook allows setting a global handler that is run before the unwinding happens.
In general, Result is always the right way to propagate errors if they are to be handled.
Abort
In some environments, unwinding on panic! is not very meaningful. For those cases, rustc and cargo have a switch that immediately aborts the program on panic.
The panic hook is executed.
Double-panics
Panicking while a panic is being handled - for example in a destructor - invokes undefined behaviour. For that reason, the program will immediately abort.
Dynamic Dispatch
Sometimes, we want to take the decision of which implementation to use at runtime instead of letting the compiler monomorphize the code.
There’s two approaches.
Dispatch through Enums
If the number of possible choices is limited, an Enum can be used:
#![allow(unused)]
fn main() {
enum Operation {
Get,
Set(String),
Count
}
fn execute(op: Operation) {
match op {
Operation::Get => { }
Operation::Set(s) => { }
Operation::Count => { }
}
}
}Alternative Form
#![allow(unused)]
fn main() {
enum Operation {
Get,
Set(String),
Count
}
impl Operation {
fn execute(&self) {
match &self {
&Operation::Get => { }
&Operation::Set(s) => { }
&Operation::Count => { }
}
}
}
}Recommendation
For best performance, try to minimize repeated matches on the enum.
See https://godbolt.org/z/8Yf4751qh
Note:
It takes multiple instructions to extract the tag from the enum and then jump to the appropriate block of code based on the value of that tag. If you use the Trait Objects we describe later, the kind of thing is encoded in the pointer to the dynamic dispatch table (or v-table) and so the CPU can just do two jumps instead of ‘if this is 0, do X, else if this is a 1, do Y, else …’.
Trait Objects
We can make references which do not know the type of the value but instead only know one particular trait that the value implements.
This is a trait object.
Internally, trait objects are a pair of pointers - one to a vtable and one the value itself.
Note:
The term vtable is short for virtual dispatch table, and it’s basically a struct full of function pointers that is auto-generated by the compiler.
Usage
fn print(thing: &dyn std::fmt::Debug) {
// I can call `std::fmt::Debug` methods on `thing`
println!("{:?}", thing);
// But I don't know what the *actual* type is
}
fn main() {
print(&String::from("hello"));
print(&123);
}Limitations
- You can only use one trait per object
- Plus auto traits, like
SendandSync
- Plus auto traits, like
- This trait must fulfill certain conditions
Rules for dyn-compatible traits (abbreviated)
- Must not have
Self: Sized - No associated constants or GATs
- All methods must:
- Have no type parameters
- Not use
Self, only&selfetc - Not return
impl Trait
See the docs for details.
Note that these used to be called “object safety” rules before 1.83.
Performance
There is a small cost for jumping via the vtable, but it’s cheaper than an enum match.
See https://godbolt.org/z/cheWrvM45
Trait Objects and Closures
Closure traits are dyn-compatible.
#![allow(unused)]
fn main() {
fn factory() -> Box<dyn Fn(i32) -> i32> {
let num = 5;
Box::new(move |x| x + num)
}
}Is this a reference to a String?
Any type that is 'static + Sized implements std::any::Any.
We can use this to ask “is this reference actually a reference to this specific type?”
fn print_if_string(value: &dyn std::any::Any) {
if let Some(s) = value.downcast_ref::<String>() {
println!("It's a string({}): '{}'", s.len(), s);
} else {
println!("Not a string...");
}
}
fn main() {
print_if_string(&0);
print_if_string(&String::from("cookie monster"));
}Note:
Be sure to check the documentation because Any has some important restrictions.
Macros
What can macros do?
Macros can be used to things such as:
- Generate repetitive code
- Create Domain-Specific Languages (or DSLs)
- Write things that would otherwise be hard without Macros
There are two kinds of macro
- Declarative
- Procedural
Declarative Macros
Declarative Macros
- Defined using
macro_rules! - Perform pattern matching and substitution
- Can do repeated actions
Declarative Macros are:
- Hygienic: expansion happens in a different ‘syntax context’
- Correct: they cannot expand to invalid code
- Limited: they cannot, for example, pollute their expansion site
The vec! macro
fn main() {
// You write:
let v = vec![1, 2, 3];
// The compiler sees (roughly):
let v = {
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
};
}How does that work?
“Match zero or more expressions, and paste each into into a temp_vec.push() call”
#![allow(unused)]
fn main() {
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}
}Note:
The actual macro is more complicated as it sets the Vec to have the correct capacity up front, to avoid re-allocation during the pushing of the values. Any new variables we introduce are given a colour to distinguish them from any the caller had created in the same scope.
println! and friends
println! is a macro, because:
- Rust does not have variadic functions
- Rust wants to type-check the call
Expanding println!
fn main() {
// You write
println!("Hello {}, aged {}", "Sam", 40);
// The compiler sees (roughly):
let arguments = Arguments {
pieces: &["Hello ", ", aged ", "\n"],
args: &[
Argument { value: &"Sam", formatter: string_formatter },
Argument { value: &40, formatter: integer_formatter },
],
};
::std::io::_print(arguments);
}Note:
This is a simplified example - the real output is slightly more complicated, and is in fact handled by a compiler built-in so you can’t even see the macro source for yourself.
Downsides of Declarative Macros
- Can be difficult to debug
- Can be confusing to read and understand
When Should You Use Declarative Macros?
- When there are no other good alternatives
Procedural macros
Procedural macros
- A procedural macro is a function that takes some code as input, and produces some code.
- It runs at compile time
- It is written in Rust and must therefore be compiled before your program is
Three kinds of procedural macro
- Custom
#[derive]macros - Attribute-like macros
- Function-like macros
Custom #[derive] macros
Work like the built-in Rust derives, once you’ve imported them:
use serde::Serialize;
#[derive(Debug, Clone, Serialize)]
struct Square {
width: u32,
}
fn main() {
let sq = Square { width: 25 };
let json = serde_json::to_string(&sq).unwrap();
println!("{}", json);
}Often named after the traits they implement.
Note:
In the Rust Docs search results, the trait appears in blue, and the macro appears in green.
Rust can always work out whether you mean the trait or the macro, from the context.
Attribute-like macros
- Placed above a type, function, or field
- Can have optional arguments
#[tokio::main(worker_threads = 2)]
async fn main() {
println!("Hello world");
}Function-like macros
Called like a function:
let query = sqlx::query!("SELECT * FROM `person`");Downsides of Procedural Macros
- Can be difficult to debug
- Slows down compilation a lot
- Have to be stored in a separate crate
- You’re basically building compiler plug-ins at build time
When Should You Use Procedural Macros?
- When it saves your users a sufficient amount of work
Property Testing
This is your brain
- Everything we know is subject to bias
- Everything we build reflects these biases
Problem:
Our code reflects our biases, our tests are often biased similarly
Solution:
Don’t write tests
Solution:
Write expectations
- Have the machine generate random test cases
- Make beliefs explicit, force them to pay rent
This is called property testing
Crate: proptest
// this property is false, but perhaps
// not unreasonable to expect to be true
proptest! {
#[test]
fn mult_and_div(ref a in any::<usize>()) {
let result = (a * 5) / 5;
assert_eq!(result, a);
}
}Crate: proptest
$ cargo test
test mult_and_div ... FAILED
Test failed: attempt to multiply with overflow;
minimal failing input: ref a = 3689348814741910324
test result: FAILED. 0 passed; 1 failed
Crate: proptest
$ cat proptest-regressions/main.txt
# Seeds for failure cases proptest has
# generated. It is automatically read
# and these particular cases re-run before
# any novel cases are generated.
# shrinks to ref a = 3689348814741910324
xs 4050946508 1278147119 4151624343 875310407
Wonderful for testing codecs, serialization, compression, or any set of operations that should retain equality.
proptest! {
#[test]
fn compress_roundtrip(ref s in ".*") {
let result = decompress(compress(s));
assert_eq!(result, s);
}
}It’s easy to generate more structured input, too
proptest! {
#[test]
fn parses_all_valid_dates(
ref s in "[0-9]{4}-[0-9]{2}-[0-9]{2}"
) {
parse_date(s).unwrap();
}
}Configuration is a great target
proptest! {
#[test]
fn doesnt_crash(
bit in 0usize..1_000_000,
page_sz_exponent in 0usize..30
) {
let page_sz = 1 << page_sz_exponent;
let mut bits = Bitfield::new(page_sz);
assert_eq!(bits.set(bit, true), Change::Changed);
assert_eq!(bits.get(bit), true);
}
}Miscellaneous Tips
- Isolate business logic from IO concerns
- Use
assert!anddebug_assert!on non-trivial things! this makes our “fuzzers” extremely effective - Try not to use
unwrap()everywhere, at least useexpect("helpful message")to speed up debugging - When propagating errors, include context that helps you get back to the root
Rust Projects Build Time
Understanding Rust projects build time
- Cargo keeps track of changes you make and only rebuilds what is necessary
- when building a crate
rustccan do most of code generation in parallel, but many frontend steps still require synchronization - depending on the type of build, times spent in different build phases may be vastly different.
- debug vs release
- various flags for
rustcand LLVM - a build from scratch vs an incremental build
Producing a build timings report
rm -rf target/debug && cargo build --timings
.
└── target/
├── cargo-timings/
│ ├── cargo-timings.html
│ └── cargo-timings-<timestamp>.html
├── debug/
└── ...
Timings Report
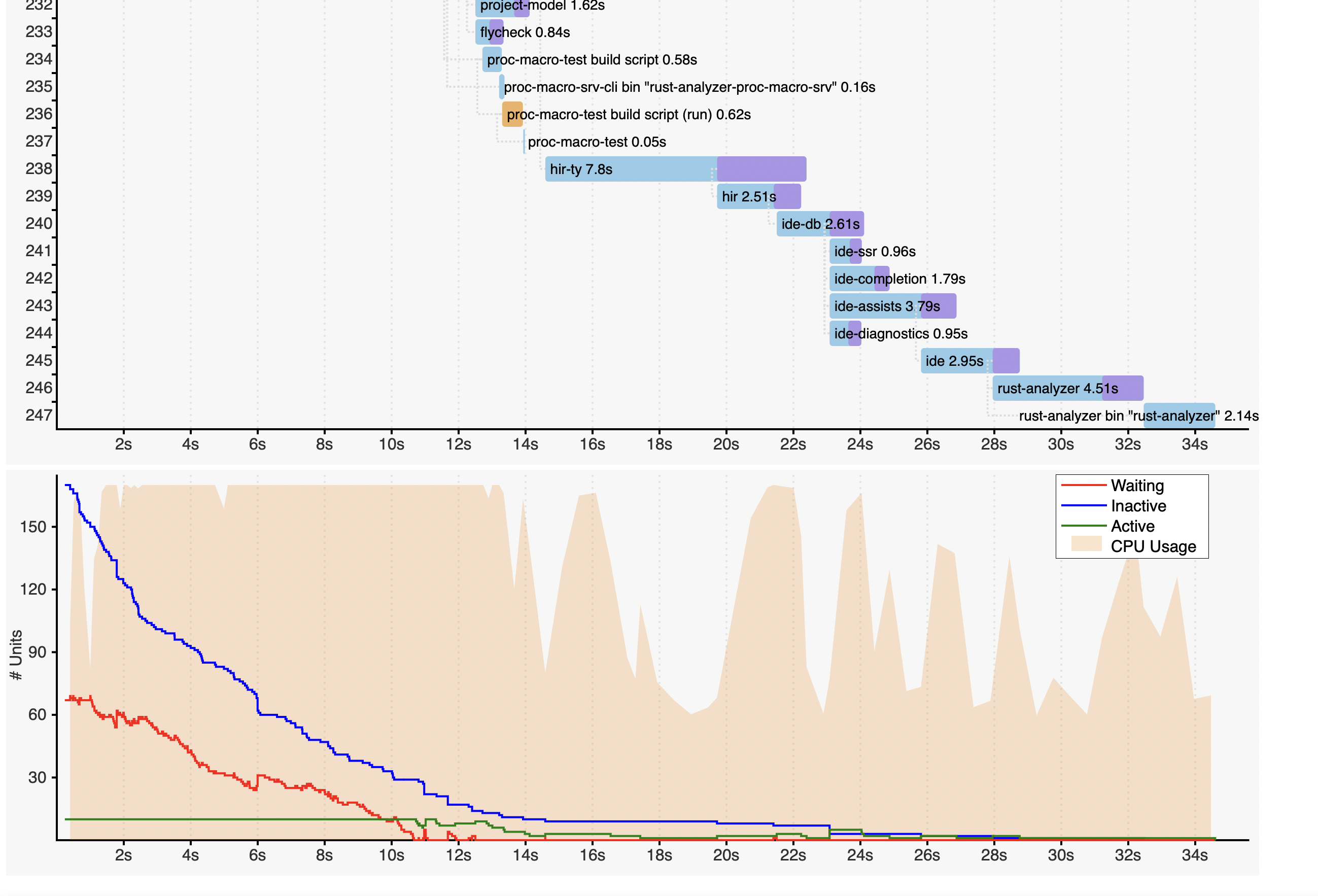
Reading the report
- Cargo can’t start building a crate until all its dependencies have been built.
- Cargo only waits for
rustcto produce an LLVM IR, further compilation by LLVM can run in background (purple)
- Cargo only waits for
- a crate can’t start building until its
build.rsis built and finishes running (yellow) - if multiple crates depend on a single crate they often can start building in parallel
- if a package is both a binary and a library then the binary is built after a library
- integration tests, examples, benchmarks, and documentation tests all produce binaries and thus take extra time to build.
Actions you can take
Keep your crates independent of each other
-
Bad dependency graph:
D -> C -> B -> A -> App -
Good dependency graph (A, B, and C can be built in parallel and with greater incrementality):
/-> A \ D -> B -> App \-> C /
Note: To clarify
- more parallelism -> the compiler can do more work at the same time
- more incrementality -> the compiler can avoid doing work it’s done before
Turn off unused features
-
Before:
[dependencies] tokio = { version = "1", features = ["full"] } # build all of Tokio . -
After:
[dependencies] tokio = { version = "1", features = ["net", "io-util", "rt-multi-thread"] }
Prefer pure-Rust dependencies
-
crate cannot be built before
build.rsis compiled and executed- crates using C-dependencies have to rely on
build.rs build.rsmight trigger C/C++ compilation which in turn is often slow
- crates using C-dependencies have to rely on
-
e.g.:
rustlsinstead ofopenssl
Use multi-module integration tests:
- Before (3 binaries)
├── src/
│ └── ...
└── tests/
├── account-management.rs
├── billing.rs
└── reporting.rs
- After (a single binary)
├── src/
│ └── ...
└── tests/
└── my-app-tests/
├── main.rs # includes the rest as modules .
├── account-management.rs
├── billing.rs
└── reporting.rs
- Also benchmark and examples
Other tips
- split your large package into a few smaller ones to improve build parallelization
- extract your binaries into separate packages
- remove unused dependencies
Tools
cargo-chefto speed up your docker buildssccachefor caching intermediary build artifacts across multiple projects and developers
Send & Sync
There are two special traits in Rust for concurrency semantics.
Sendmarks a structure safe to send between threads.Syncmarks a structure safe to share between threads.- (
&TisSend)
- (
These traits are what Rust uses to prevent data races.
They are automatically derived for all types if appropriate.
Automatically Derived
use std::thread;
#[derive(Debug)]
struct Thing;
// Can send between threads!
fn main() {
let thing = Thing;
thread::spawn(move || {
println!("{:?}", thing);
}).join().unwrap();
}There are some notable types which are not Send or Sync.
Such as Rc, raw pointers, and UnsafeCell.
Example: Rc
use std::rc::Rc;
use std::thread;
// Does not work!
fn main() {
let value = Rc::new(true);
thread::spawn(move || {
println!("{:?}", value);
}).join().unwrap();
}Example: Rc
error[E0277]: `Rc<bool>` cannot be sent between threads safely
--> src/main.rs:7:19
|
7 | thread::spawn(move || {
| ------------- ^------
| | |
| _____|_____________within this `{closure@src/main.rs:7:19: 7:26}`
| | |
| | required by a bound introduced by this call
8 | | println!("{:?}", value);
9 | | }).join().unwrap();
| |_____^ `Rc<bool>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:7:19: 7:26}`, the trait `Send` is not implemented for `Rc<bool>`, which is required by `{closure@src/main.rs:7:19: 7:26}: Send`
note: required because it's used within this closure
--> src/main.rs:7:19
|
7 | thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /home/mrg/.rustup/toolchains/stable-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/std/src/thread/mod.rs:675:8
|
672 | pub fn spawn<F, T>(f: F) -> JoinHandle<T>
| ----- required by a bound in this function
...
675 | F: Send + 'static,
| ^^^^ required by this bound in `spawn`
For more information about this error, try `rustc --explain E0277`.
Implementing
It’s possible to add the implementation of Send and Sync to a type.
#![allow(unused)]
fn main() {
struct Thing(*mut String);
unsafe impl Send for Thing {}
unsafe impl Sync for Thing {}
}In these cases, the task of thread safety is left to the implementor.
Relationships
If a type implements both Sync and Copy then it can also implement Send.
Relationships
A type &T can implement Send if the type T also implements Sync.
unsafe impl<'a, T: Sync + ?Sized> Send for &'a T {}Relationships
A type &mut T can implement Send if the type T also implements Send.
unsafe impl<'a, T: Send + ?Sized> Send for &'a mut T {}Consequences
What are the consequences of having Send and Sync?
Consequences
Carrying this information at the type system level allows driving data race bugs down to a compile time level.
Preventing this error class from reaching production systems.
Send and Sync are independent of the choice of concurrency (async, threaded, etc.).
Serialization and Deserialization (serde)
Serialization and Deserialization
Serialize & Deserialize
To make a Rust structure (de)serializable:
#[derive(Debug, serde::Serialize, serde::Deserialize)]
struct Move {
id: usize,
direction: Direction,
}
#[derive(Debug, serde::Serialize, serde::Deserialize)]
enum Direction { North, South, East, West }Formats
Serde supports a number of formats, such as:
- JSON
- CBOR
- YAML
- TOML
- BSON
- MessagePack
- … More!
Did you enjoy that acronym salad?
Serialize
To JSON:
use serde::{Serialize, Deserialize};
#[derive(Debug, Serialize, Deserialize)]
struct Move {
id: usize,
direction: Direction,
}
#[derive(Debug, Serialize, Deserialize)]
enum Direction { North, South, East, West }
fn main() {
let action = Move { id: 1, direction: West };
let payload = serde_json::to_string(&action);
println!("{:?}", payload);
}Deserialize
From JSON:
use serde::{Serialize, Deserialize};
#[derive(Debug, Serialize, Deserialize)]
struct Move {
id: usize,
direction: Direction,
}
#[derive(Debug, Serialize, Deserialize)]
enum Direction { North, South, East, West }
fn main() {
let payload = r#"{ "id": 1, "direction": "West" }"#;
let action = serde_json::from_str::<Move>(&payload);
println!("{:?}", action);
}Transcode
use serde::{Serialize, Deserialize};
use serde_transcode::transcode;
#[derive(Debug, Serialize, Deserialize)]
struct Move {
id: usize,
direction: Direction,
}
#[derive(Debug, Serialize, Deserialize)]
enum Direction { North, South, East, West }
fn main() {
let payload = r#"{ "id": 1, "direction": "West" }"#;
let mut buffer = String::new();
{
let mut ser = toml::Serializer::new(&mut buffer);
let mut de = serde_json::Deserializer::from_str(&payload);
transcode(&mut de, &mut ser)
.unwrap();
}
println!("{:?}", buffer);
}Attributes
serde has a large number of attributes you can utilize:
#[serde(deny_unknown_fields)] // Be extra strict
struct Move {
#[serde(default)] // Call usize::default()
id: usize,
#[serde(rename = "dir")] // Use a different name
direction: Direction,
}https://serde.rs/attributes.html
Testing
Testing is fundamental to Rust.
Unit, integration, and documentation tests all come built-in.
Organizing Tests
Tests typically end up in 1 of 4 possible locations:
- Immediately beside the functionality tested (Unit Tests)
- In a
testssubmodule (Unit Tests) - In documentation. (Documentation Test)
- In the
tests/directory. (Integration Tests)
Unit Tests
- Allows testing functionality in the same module and environment.
- Typically exist immediately near the functionality.
- Good for testing to make sure a single action works.
Unit Tests
- Allows testing as if the functionality is being used elsewhere in the project.
- For testing private APIs and functionality.
- Good for testing expected processes and use cases.
tests Submodule
#![allow(unused)]
fn main() {
enum Direction { North, South, East, West }
fn is_north(dir: Direction) -> bool {
match dir {
Direction::North => true,
_ => false,
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn is_north_works() {
assert!(is_north(Direction::North) == true);
assert!(is_north(Direction::South) == false);
}
}
}tests Submodule
$ cargo test
running 1 test
test tests::is_north_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Documentation Tests
- Allows testing public functionality.
- Is displayed in
rustdocoutput. - For demonstrating expected use cases and examples.
Documentation Tests
#![allow(unused)]
fn main() {
/// ```rust
/// use example::Direction;
/// let way_home = Direction::North;
/// ```
pub enum Direction { North, South, East, West }
}Documentation Tests
$ cargo test
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured
Doc-tests example
running 1 test
test Direction_0 ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Integration Tests
- Tests as if the crate is an external dependency.
- Intended for longer or full-function tests.
Integration Tests
./tests/basic.rs
use example::{is_north, Direction};
#[test]
fn is_north_works() {
assert!(is_north(Direction::North) == true);
assert!(is_north(Direction::South) == false);
}Integration Tests
$ cargo test
running 1 test
test is_north_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured
Running target/debug/deps/example-9f39afa5d2a1c6bf
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured
Doc-tests example
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured
std Library Tour
It’s time for a tour of some interesting parts in std.
We will focus on parts we have not otherwise covered.
PhantomData
Zero-sized types are used to mark things that “act like” they own a T.
These are useful for types which require markers, generics, or use unsafe code.
use std::marker::PhantomData;
struct HttpRequest<ResponseValue> {
// Eventually returns this type.
response_value: PhantomData<ResponseValue>,
}
fn main() {}Command
A process builder, providing fine-grained control over how a new process should be spawned.
Used for interacting with other executables.
#![allow(unused)]
fn main() {
use std::process::Command;
fn example() {
Command::new("ls")
.args(&["-l", "-a"])
.spawn()
.expect("ls command failed to start");
}
}Filesystem Manipulation
Path handling and file manipulation.
use std::fs::{File, canonicalize};
use std::io::Write;
fn main() {
let mut file = File::create("foo.txt").unwrap();
file.write_all(b"Hello, world!").unwrap();
let path = canonicalize("foo.txt").unwrap();
let components: Vec<_> = path.components().collect();
println!("{:?}", components);
}Using Cargo
Crates and Packages
- Rust code is arranged into packages
- a package is described by a
Cargo.tomlfile - building a package can produce a single library, and 0 or more executables
- these are called crates
- unlike C/C++ compilers that compile code file by file,
rustctreat all files for a crate as a single compilation unit
- Cargo calls
rustcto build each crate in the package.
Cargo
- standard build toolchain for Rust projects
- shipped with
rustc
What Cargo does
- resolves and installs project dependencies
- runs
rustcto compile your code - runs a linker to produce libraries and executables
- runs tests and benchmarks
- builds documentation and runs documentation tests
- runs additional tools like code formatter and linter
- can be extended with additional custom commands
Cargo does Everything!
Cargo commands
cargo new my-appcargo run- runs a debug build of your program, builds it if necessarycargo fmt- formats your codecargo check- only reports errors, doesn’t actually compile your codecargo clippy- runs a lintercargo test- builds your project if necessary and runs tests- by default runs unit tests, integration tests, and documentation tests
- you can select which tests to run
cargo build --release- produces an optimized version of your application or library
Cargo commands (cont)
There are many more!
cargo bench- builds an optimized version of your project and runs benchmarkscargo doc --open- builds documentation for your project and all its dependencies and opens it in a browsercargo run --example ...- runs an example from yourexamples/directory
See Cargo Book for more.
Cargo command arguments
Most cargo commands accept a few common arguments:
+toolchain--target--features,--all-features, and--no-default-features--timings
Putting it all together:
cargo +nightly run --target x86_64-apple-darwin --features "a b c dependency/feature" --timings
- use nightly Rust
- enable features
a,b,c, and afeaturefeature of adependencycrate - (assuming we use Apple Silicon computer) build a macOS executable for x86 processor and run it using built-in emulation (Rosetta2)
- collect statistics during the build process and generate a report
Features
- allows conditional compilation
- support for different operating systems
- adapters for different libraries
- optional extensions
- can expose features from transitive dependencies
Using Features
-
in code:
#[cfg(feature = "json")] mod json_support; -
in
Cargo.toml[features] json = [] # list of features that this feature depends on default = [] # "json" feature is not enabled by default -
when someone uses your dependency
my-lib = { version: "1.0.0", features = ["json"] }
Anatomy of Rust package
cargo new hello-world
├── Cargo.lock
├── Cargo.toml
└── src/
└── main.rs
Anatomy of Rust package
├── Cargo.lock
├── Cargo.toml
├── build.rs
├── src/
│ ├── lib.rs
│ ├── main.rs
│ ├── ...
│ └── bin/
│ ├── additional-executable.rs
│ └── multi-file-executable/
│ ├── main.rs
│ └── ...
├── benches/
│ └── ...
├── examples/
│ └── ...
└── tests/
├── some-integration-tests.rs
└── multi-file-test/
├── main.rs
└── ...
Cargo.toml - A manifest file
[package]
name = "tcp-mailbox"
version = "0.1.0"
[dependencies]
async-std = "1" # would also choose 1.5
clap = "2.2" # would also choose 2.3
Using Types to encode State
Systems have state
The system state is the product of all the things in the system that can be varied.
State can often be sub-divided into smaller units - some independent, some connected.
Examples?
A GPIO pin on a microcontroller. It typically has:
- An output driver, that allows it to drive current out of the pin (or not)
- An input buffer, that allows the CPU to read the state of the pin
- An output level (high or low)
Functionality can depend on state
Is this program correct?
let p = GpioPin::new(7);
if p.is_low() {
println!("Button is pressed");
}Note:
- What if the pin defaults to “output mode”?
- What does it mean to read the level of a pin in output mode?
Ignoring the problem
You don’t have to solve this problem.
See, Arduino, which happily uses int for GPIO pin IDs, not values of custom
types.
But we can do better?
We’ve got a type system with traits and a powerful static analysis engine…
let p = OutputPin::new(7);
if p.is_low() {
println!("Button is pressed");
}1 | struct OutputPin {}
| ---------------- method `is_low` not found for this struct
...
9 | if p.is_low() {
| ^^^^^^ method not found in `OutputPin`
How would you change state?
With a method that takes ownership:
impl OutputPin {
fn into_input(self) -> InputPin {
poke_hardware_registers();
InputPin { self.pin_id }
}
}
impl InputPin {
fn into_output(self) -> OutputPin {
poke_hardware_registers();
OutputPin { self.pin_id }
}
}Note:
The function call poke_hardware_registers() is a placeholder for whatever work
you need to do on that microcontroller to change the state of that pin.
Non-Zero Sized Types
This type consumes 1 byte of RAM (maybe 4 bytes, with alignment). Is that strictly required?
#![allow(unused)]
fn main() {
struct OutputPin {
pin_id: u8
}
}Zero Sized Types
This type is of zero size. But any method call on it has access to the pin number, through the type system.
struct OutputPin<const PIN: u8> { _inner: () }
impl<const PIN: u8> OutputPin<PIN> {
fn print_id(&self) {
println!("I am pin {}", PIN);
}
}
fn main() {
let p: OutputPin<5> = OutputPin { _inner: () };
p.print_id();
println!("size is {}", std::mem::size_of_val(&p));
}Note:
The _inner field is not pub, and therefore ensures values of this type can’t
be constructed outside the module it was defined in. This forces people to use
the new functions you provide!
Generic Pin Modes?
#![allow(unused)]
fn main() {
pub trait PinMode {}
pub struct Output {}
impl PinMode for Output {}
pub struct Input {}
impl PinMode for Input {}
pub struct Pin<MODE> where MODE: PinMode { mode: MODE }
impl Pin<Output> {
pub fn set_high(&self) { }
pub fn set_low(&self) { }
}
impl Pin<Input> {
pub fn is_high(&self) -> bool { todo!() }
pub fn is_low(&self) -> bool { todo!() }
}
}Preventing mis-use.
Who can impl PinMode for Type? Turns out anyone can…
use my_driver_crate::{Pin, PinMode};
struct OnFire {}
impl PinMode for OnFire {}
let pin: Pin<OnFire> = ...;Sealing traits
#![allow(unused)]
fn main() {
mod private { pub trait Sealed {} }
pub trait PinMode: private::Sealed {}
pub struct Output {}
impl PinMode for Output {}
impl private::Sealed for Output {}
pub struct Input {}
impl PinMode for Input {}
impl private::Sealed for Input {}
}Note:
The ‘private’ module is not pub, but the trait within it is pub. This means
you cannot implement the PinMode trait yourself unless you can also ‘see’ a
path to the private::Sealed trait - which is only visible within this
module.
It’s a trick to ensure only this module can implement the trait, but anyone else can see the trait and which types implement it.
WebAssembly
What?
WebAssembly (WASM) enables running Rust (among others) in a sandbox environment, including the browser.
WebAssembly is supported as a compile target.
High performance
WASM is built with speed in mind and executes almost as fast as native code.
The WASM sandbox
In its initial state, WASM does only provide memory and execution, no functionality.
This can be added through the host system in various ways.
Hello World
(module
;; Import the required fd_write WASI function which will write the given io vectors to stdout
;; The function signature for fd_write is:
;; (File Descriptor, *iovs, iovs_len, nwritten) -> Returns number of bytes written
(import "wasi_unstable" "fd_write" (func $fd_write (param i32 i32 i32 i32) (result i32)))
(memory 1)
(export "memory" (memory 0))
;; Write 'hello world\n' to memory at an offset of 8 bytes
;; Note the trailing newline which is required for the text to appear
(data (i32.const 8) "hello world\n")
(func $main (export "_start")
;; Creating a new io vector within linear memory
(i32.store (i32.const 0) (i32.const 8)) ;; iov.iov_base - This is a pointer to the start of the 'hello world\n' string
(i32.store (i32.const 4) (i32.const 12)) ;; iov.iov_len - The length of the 'hello world\n' string
(call $fd_write
(i32.const 1) ;; file_descriptor - 1 for stdout
(i32.const 0) ;; *iovs - The pointer to the iov array, which is stored at memory location 0
(i32.const 1) ;; iovs_len - We're printing 1 string stored in an iov - so one.
(i32.const 20) ;; nwritten - A place in memory to store the number of bytes written
)
drop ;; Discard the number of bytes written from the top of the stack
)
)
WASM targets in Rust
Rust ships 3 WASM targets:
- wasm32-unknown-emscripten (legacy)
- ships with an implementation of libc for WASM
- wasm32-unknown-unknown (stable)
- direct compilation to WASM, with no additional tooling
- wasm32-wasi (in development)
- WASM with support for interface types, a structured way of adding capabilities
Installation: rustup Target
rustup allows installing multiple compilation targets.
$ rustup target install wasm32-unknown-unknown
$ rustup target install wasm32-wasi
Installing a host runtime
$ curl -sSLf https://wasmtime.dev/install.sh | bash
- Currently need building from git: https://github.com/bytecodealliance/wasmtime
Usage: Hello World!
$ cargo new hello
Created binary (application) `hello` package
$ cargo build --target wasm32-wasi
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
$ wasmtime target/wasm32-wasi/debug/hello.wasm
Hello, world!
A Rust & WASM Tutorial
https://ferrous-systems.github.io/wasm-training-2022/
Unsafe Rust
Rust’s type system provides many guarantees, but sometimes, they make specific solutions hard or impossible.
For that reason, Rust has the concept of “unsafe code”.
Unsafe code is allowed to:
- freely access memory
- dereference raw pointers
- call external functions
- declare values
SendandSync - write to unsynced global variables
By definition, these are not unsafe:
- conversion to raw pointers
- memory leaks
Making pointers
#![allow(unused_variables)]
fn main() {
let mut x = 1;
// The old way
let p1 = &x as *const i32;
let p2 = &mut x as *mut i32;
// Added in 1.51, was unsafe until 1.82
let p1 = core::ptr::addr_of!(x);
let p2 = core::ptr::addr_of_mut!(x);
// As of Rust 1.82, use this instead:
let p1 = &raw const x;
let p2 = &raw mut x;
}Unsafe code should never:
- be used to manage memory managed by a different allocator (e.g. construct a
std:::vec::Vecfrom a C++ vector and drop it) - cheat on the borrow checker, for example by changing lifetimes or mutability of a type. The most common source of “but I was so sure that works” bugs.
Rust’s little secret
When implementing data structures, unsafe isn’t unusual.
Safe Rust is the worst language to implement linked lists. There’s a full text on this
Unsafe code must always be marked unsafe.
fn main() {
let mut x = 1;
let p = &raw mut x;
unsafe {
my_write(p, 100);
}
println!("x is {} (or {})", x, unsafe { p.read() });
}
pub unsafe fn my_write<T>(p: *mut T, new_value: T) {
p.write(new_value)
}Note:
Modern Rust generally tries to have only a small number of unsafe operations
per unsafe block. And any unsafe function should still use unsafe blocks for
the unsafe code within, even though the function itself is unsafe to call.
Try running clippy on this example and play with clippy::multiple_unsafe_ops_per_block and clippy::undocumented_unsafe_blocks. Then try “Edition 2024”.
Traps of unsafe
- Not all examples are that simple.
unsafemust guarantee the invariants that Rust expects. - This especially applies to ownership and mutable borrowing
unsafecan lead to a value having 2 owners -> double freeunsafecan make immutable data temporarily mutable, which will lead to broken promises and tears.
Rust allows you to shoot yourself in the foot, it just requires you to take your gun out of the holster and remove the safety first.
Practical example
As Rust forbids aliasing, it is impossible in safe Rust to split a slice into 2 non-overlapping parts.
#![allow(unused)]
fn main() {
#[inline]
fn split_at_mut<T>(value: &mut [T], mid: usize) -> (&mut [T], &mut [T]) {
let len = value.len();
let ptr = value.as_mut_ptr();
assert!(mid <= len);
unsafe {
(std::slice::from_raw_parts_mut(ptr, mid),
std::slice::from_raw_parts_mut(ptr.add(mid), len - mid))
}
}
}Highlight unsafe code in VSCode
- Will highlight which function calls are
unsafeinside anunsafeblock - Helpful for longer
unsafeblocks
{
"editor.semanticTokenColorCustomizations": {
"rules": {
"*.unsafe:rust": "#ff00ff"
}
}
}
Foreign Function Interface (FFI)
What is it?
- For interfacing Rust code with foreign functions
- For interfacing foreign code with Rust functions
Application Binary Interface (ABI)
(Like an API, but for machine code calling machine code)
The Rust ABI is not stable.
Rust also supports your platform’s ABI(s).
Note:
Processors don’t understand ‘function parameters’. They have registers, and they have the stack. The compiler of the caller function must decide where to place each argument - either in a register or on the stack. The compiler of the callee function (the function being called) must decide where to retrieve each argument from. There are also decisions to be made regarding which registers a function can freely re-use, and which registers must be carefully restore to their initial value on return. If a function can freely re-use a register, then the caller needs to think about saving and restoring the register contents. If each function is responsible to putting things back exactly as they were, then the caller has less work to do, but maybe you’re saving and restoring registers that no-one cares about. When the stack is used, you also have agree whether the caller or the callee is responsible for resetting the stack point to where it was before the caller called the callee.
Think also what happens if you have a floating-point unit - do f32 and f64 values go into FPU registers, or are they placed in integer registers?
Clearly these two compilers must agree, otherwise the callee will not receive the correct arguments and your program will perform UB!
x86 is ~40 years old and many standards exist on how to do this. See https://en.wikipedia.org/wiki/X86_calling_conventions#Historical_background.
AMD64 is only ~20 years old, and there are two standards - the Microsoft one for Windows, and the Linux one (which is based on System V UNIX).
ARM64 has one main standard (the Arm Architecture Procedure Call Standard, or AAPCS), plus one Microsoft invented which works much more like AMD64 and lets ARM64 call emulated AMD64 much more easily. That’s called ARM64EC.
CPUs have registers, and they have a pointer to the stack (in RAM)
Where does this function find its arguments? Where does the return value go?
#![allow(unused)]
fn main() {
struct SomeStruct(u32, f64);
fn hello(param1: i32, param2: f64) -> SomeStruct { todo!() }
}Libraries
Your Rust code might want to interact with shared/static libraries.
Or be one.
Efficient bindings
There are no conversion costs moving from C to Rust or vice-versa
Using Rust from C
We have this amazing Rust library, we want to use in our existing C project.
#![allow(unused)]
fn main() {
struct MagicAdder {
amount: u32
}
impl MagicAdder {
fn new(amount: u32) -> MagicAdder {
MagicAdder {
amount
}
}
fn process_value(&self, value: u32) -> u32 {
self.amount + value
}
}
}Things TODO
- Tell C these functions exist
- Tell Rust to use C-compatible types and functions
- Link the external code as a library
- Provide some C types that match the Rust types
- Call our Rust functions
C-flavoured Rust Code
#![allow(unused)]
fn main() {
#[repr(C)]
struct MagicAdder {
amount: u32
}
impl MagicAdder {
fn new(amount: u32) -> MagicAdder { todo!() }
fn process_value(&self, value: u32) -> u32 { todo!() }
}
#[no_mangle]
extern "C" fn magicadder_new(amount: u32) -> MagicAdder {
MagicAdder::new(amount)
}
#[no_mangle]
extern "C" fn magicadder_process_value(adder: *const MagicAdder, value: u32) -> u32 {
if let Some(ma) = unsafe { adder.as_ref() } {
ma.process_value(value)
} else {
0
}
}
}Note:
The .as_ref() method on pointers requires that the pointer either be null, or that it point at a valid, aligned, fully initialized object. If they just feed you a random integer, bad things will happen, and we can’t tell if they’ve done that!
Matching C header
/// Designed to have the exact same shape as the Rust version
typedef struct magic_adder_t {
uint32_t amount;
} magic_adder_t;
/// Wraps MagicAdder::new
magic_adder_t magicadder_new(uint32_t amount);
/// Wraps MagicAdder::process_value
uint32_t magicadder_process_value(magic_adder_t* self, uint32_t value);
Making a library
You can tell rustc to make:
- binaries (bin)
- libraries (lib)
- rlib
- dylib
- staticlib
- cdylib
Note:
See https://doc.rust-lang.org/reference/linkage.html
Cargo.toml
[package]
name = "magic_adder"
version = "1.0.0"
edition = "2021"
[lib]
crate-type = ["lib", "staticlib", "cdylib"]
Note:
See ./examples/ffi_use_rust_in_c for a working example.
Using C from Rust
We have this amazing C library, we want to use as-is in our Rust project.
cool_library.h:
/** Parse a null-terminated string */
unsigned int cool_library_function(const unsigned char* p);
cool_library.c:
#include "hello.h"
unsigned int cool_library_function(const unsigned char* s) {
unsigned int result = 0;
for(const char* p = s; *p; p++) {
result *= 10;
if ((*p < '0') || (*p > '9')) { return 0; }
result += (*p - '0');
}
return result;
}
Things TODO
- Tell Rust these functions exist
- Link the external code as a library
- Call those with
unsafe { ... } - Transmute data for C functions
Naming things is hard
#![allow(unused)]
#![allow(non_camel_case_types, non_upper_case_globals, non_snake_case)]
fn main() {
}
Disables some Rust naming lints
Binding functions
/** Parse a null-terminated string */
unsigned int cool_library_function(const char* p);
#![allow(unused)]
fn main() {
use std::ffi::c_char; // also in core::ffi
extern "C" {
// We state that this function exists, but there's no definition.
// The linker looks for this 'symbol name' in the other objects
fn cool_library_function(p: *const c_char) -> u32;
}
}Note:
You cannot do extern "C" fn some_function(); with no function body - you must use the block.
Changes in Rust 1.82
You can now mark external functions as safe:
unsafe extern "C" {
// This function is basically impossible to call wrong, so let's mark it safe
safe fn do_stuff(x: i32) -> i32;
}
fn main() {
dbg!(do_stuff(3));
}
#[unsafe(export_name = "do_stuff")]
extern "C" fn my_do_stuff(x: i32) -> i32 {
x + 1
}Note:
You can only mark an extern function as safe within an unsafe extern block.
Also note that in Rust 1.82, export_name became an unsafe attribute, along
with no_mangle and link_section. The old form is still allowed in Edition
2021 and earlier (for backwards compatibility), but you will have to use the new
syntax in Edition 2024.
Primitive types
Some C types have direct Rust equivalents. See also core::ffi.
| C | Rust |
|---|---|
int32_t | i32 |
unsigned int | c_uint |
unsigned char | u8 (not char!) |
void | () |
char* | CStr or *const c_char |
T* | Box<T> (if T is sized) |
Note:
On some systems, a C char is not 8 bits in size. Rust does not support those
platforms, and likely never will. Rust does support platforms where int is
only 16-bits in size.
If T: ?Sized, then Box<T> may be larger than a single pointer as it will
also need to hold the length information. That means it is no longer the same
size and layout as T*.
Calling this
use std::ffi::{c_char, c_uint};
extern "C" {
fn cool_library_function(p: *const c_char) -> c_uint;
}
fn main() {
let s = c"123"; // <-- a null-terminated string!
let result: u32 = unsafe { cool_library_function(s.as_ptr()) };
println!("cool_library_function({s:?}) => {result}");
}Some more specific details…
Cargo (build-system) support
- Build native code via build-dependency crates:
build.rscan give linker extra arguments
Opaque types
When not knowing (or caring) about internal layout, opaque structs can be used.
#![allow(unused)]
fn main() {
/// This is like a 'struct FoobarContext;' in C
#[repr(C)]
pub struct FoobarContext { _priv: [i32; 0] }
extern "C" {
fn foobar_init() -> *mut FoobarContext;
fn foobar_do(ctx: *mut FoobarContext, foo: i32);
fn foobar_destroy(ctx: *mut FoobarContext);
}
/// Use this in your Rust code
pub struct FoobarHandle(*mut FoobarContext);
}Callbacks
extern "C" applies to function pointers given to extern functions too.
use std::ffi::c_void;
pub type FooCallback = extern "C" fn(state: *mut c_void);
extern "C" {
pub fn libfoo_register_callback(state: *mut c_void, cb: FooCallback);
}
extern "C" fn my_callback(_state: *mut c_void) {
// Do stuff here
}
fn main() {
unsafe { libfoo_register_callback(core::ptr::null_mut(), my_callback); }
}But this is a lot of manual work?
There’s a better way!
Making C headers from Rust
Making Rust source from C headers
Loading auto-generated Rust source
#[allow(non_camel_case_types, non_snake_case, non_upper_case_globals)]
pub mod bindings {
include!(concat!(env!("OUT_DIR"), "/bindings.rs"));
}Calling these tools:
- On the command line
- Executing a command in
build.rs - Calling a library function in
build.rs
sys crates
xxxx-sys is a Rust crate that provides a thin wrapper around some C library xxxx.
You normally have a higher-level xxxx crate that provides a Rust interface
Note:
For example libgit2-sys (wraps libgit2), or nrfxlib-sys (nRF9160 support)
Working With Nightly
Why?
- There are many features which are not yet stable
- language
- library
- cargo, rustdoc, etc
- Dependencies may require nightly
- You can’t wait for the train
- Compile times and error messages are sometimes better (sometimes not)
Using Nightly
Use rustup to override the version used in a specific directory.
cd /nightly_project
rustup override set nightly-2024-02-01
Pinning a version
You can also store the information in your repo:
$ cat rust-toolchain.toml
[toolchain]
channel = "nightly-2024-02-01"
Language features
Language features are parts of Rust we haven’t quite agreed on yet, but there’s an implementation there to be tested. Each one has a tracking issue.
Some examples:
riscv_target_feature- addstarget_featureon RISC-Vnaked_functions- functions with no prologue or epiloguenever_type- supporting!as a type
RPIT, RPITIT, AFIT, and more
- Return Position Impl Trait
- Return Position Impl Trait in Trait
- Async Function in Trait
- A handy guide
Note:
- RPIT would be something like
fn fetch() -> impl Debug. - RPITIT is a trait method that has impl trait in the return position.
- AFIT is a trait method like
async fn do_stuff()
Enabling Language Features
To enable, add the feature attribute to your top-level module:
#![feature(riscv_target_feature)]Compiler features
Unstable compiler flags start with -Z.
See them all with:
rustc +nightly -Z help
Library features
Some parts of the Standard Library are ‘unstable’ and only available on nightly.
Nothing special required to opt-in, just nightly Rust.
You can see them in the docs, like slice::new_zeroed_slice()
Cargo features
You can specify unstable cargo features in your .cargo/config.toml:
[unstable]
mtime-on-use = true
The Standard Library
- The Standard Library is written in Rust
- It must therefore be compiled
- But stable
rustccannot compile the Standard Library - =>
rustupgives you a pre-compiled Standard Library for your target
Note:
Why does it require nightly? Because it’s full of unstable library APIs, and makes use of unstable compiler features.
So how do they build libstd during a toolchain release? With a secret magic flag that makes stable Rust look like nightly Rust for the purposes of building the standard library. You should not use this flag yourself.
Compiling the Standard Library
- If you have nightly rust, you can compile it from source yourself
rustup component add rust-srcrustc -Z build-std=core,alloc ..., or give cargo this config:
[unstable]
build-std = ["core", "alloc"]
Availability
- Nightly doesn’t always successfully build
- rustup can go back in time and find a working build
- rustup-component-history can help
The books
The Shape of a Rust Program
- Embedded systems come in many shapes and sizes
- Rust tries to be flexible and support developers
Some Terms
- Binary
- Static Library
- Dynamic Library
- RTOS
Note:
A binary is a collection of executable machine code and data, typically but not exclusively in ELF format, with a defined ‘entry point’. The CPU should jump to the address of the ‘entry point’ and start executing from there.
A static library is an archive containing object code, typically with a .a
extension. The object code contains gaps where the run-time addresses need to be
plugged in by a linker, before it can be considered executable code.
A dynamic library looks more like a binary (and is typically in ELF format), but
it still contains gaps that need to be plugged by a dynamic linker (also known
as a loader). Linux .so files and Windows .dll files are in this category.
A Real-Time Operating System manages the execution of one or more tasks, typically with pre-emptive context switching, but not exclusively.
1) Flat Binaries
- Top-level is a Rust Binary
- Typically
main.rs
- Typically
- Program runs on start-up
- Started by the reset vector, or the boot ROM
- Can pull in an RTOS or async runtime, as a static library
- Linker sees everything
- Flat address space
- The most common approach
- See RTIC, embassy, Eclipse ThreadX, or FreeRTOS
2) Bootloader + Application
- Two binaries, linked separately
- First binary (e.g. bootloader) starts the second (e.g. application)
- Sometimes the second calls back into the first
- Use linker scripts to divide up memory
- Also often used to implement Arm Secure Mode (TrustZone) APIs
- See RP2350 HAL or the nRF9160 SPM
Note:
The RP2350 Bootloader is in ROM, but it’s still a binary. It inspects the application in flash (optionally performing a hash check or a cryptographic signature check) before jumping to the application. The application can then make calls back into the ROM bootloader, by calling a function that lives at a well-known address (or that has a function pointer that is stored at a well-known address). The bootloader in ROM starts in the Arm Cortex-M33’s ‘Secure’ state, but can switch the CPU into ‘non-secure’ state before running the application, if that’s what the application metadata says to do.
The nRF9160 Secure Partition Manager is similar, but must be written to the
start of the nRF9160’s flash. It also expects the exclusive use of a particular
block of SRAM and so you must avoid that region of SRAM in your application. See
the nrf9160-hal’s memory.x file for an example.
3) Tasks are Libraries
- Each ‘task’ is a static library
- The OS provides a ‘skeleton’ binary
- It imports and calls your tasks
- Tasks provide an entry point, and some mechanism to call the OS
- Typically SVC calls
- See Zephyr and RTEMS
Note:
SVC is the Arm mnemonic for performing a system call. These are also known as ‘software interrupts’ and earlier Arm architectures used the mnemonic SWI.
4) Tasks are Binaries (dynamic linking)
- Some systems have multiple ‘flash slots’
- The run-time address is not known at link time
- Enforces isolation between tasks - has to use SVC calls
- Rust does not currently support RWPI or ROPI code
- Rust has some support for PIC/PIE code
- But then you have to write a dynamic linker for fix the code at load time
- See TockOS or Linux/macOS/Windows/QNX…
Note:
As of 2024, TockOS only allows Rust applications to be installed in the first flash slot, for this reason. C applications can be installed into any flash slot, because ROPI/RWPI works for C.
RWPI is read-write position independence, and involves static data not having a fixed address but instead being accessed via a reserved register that always contains the ‘static base pointer’ (i.e. the base address of the RW data).
ROPI is read-only position independence, and involves executable code not having a fixed address but instead being accessed via PC-relative jumps.
PIC/PIE is position independent code / executable. This involves non-PC-relative jumps to code or data being made via a Global Offset Table (GOT). The GOT needs modifying at load time, once you know where everything is in memory. Linux programs and shared libraries are PIE/PIC.
5) Tasks are Binaries (static linking)
- Like (4), but you have a tool work out the linking once you have all the binaries
- Doesn’t require ROPI or RWPI
- But you have to know the full set of tasks in advance
- See Hubris
Summary
- Flat Binaries
- Bootloader + Application
- Tasks are Libraries
- Tasks are Binaries (dynamic linking)
- Tasks are Binaries (static linking)
Remember, these are embedded systems issues, not necessarily Rust-specific issues.
Async Building Blocks
Async
- Built from important “building blocks”
- Futures, Tasks, Executors, Streams, and more
Differences between async & sync
- sync programming often has imperative behaviour
- async programming is about constructing a process at runtime and then executing it
- this process is called the “futures tree”
An async Rust function
use tokio::{fs::File, io::AsyncReadExt};
async fn read_from_disk(path: &str) -> std::io::Result<String> {
let mut file = File::open(path).await?;
let mut buffer = String::new();
file.read_to_string(&mut buffer).await?;
Ok(buffer)
}(sketch) Desugaring return type
use std::future::Future;
use tokio::{fs::File, io::AsyncReadExt};
fn read_from_disk<'a>(path: &'a str)
-> impl Future<Output = std::io::Result<String>> + 'a
{
async move {
let mut file = File::open(path).await?;
let mut buffer = String::new();
file.read_to_string(&mut buffer).await?;
Ok(buffer)
}
}What are Futures
Futures represent a datastructure that - at some point in the future - give us the value that we are waiting for. The Future may be:
- delayed
- immediate
- infinite
Futures are operations
Futures are complete operations that can be awaited for.
Examples:
read: Read (up to) a number of bytesread_to_end: Read a complete input streamconnect: Connect a socket
Futures are poll-based
They can be checked if they are done, and are usually mapped to readiness based APIs like epoll.
.await registers interest in completion
use tokio::{fs::File, io::AsyncReadExt};
async fn read_from_disk(path: &str) -> std::io::Result<String> {
let mut file = File::open(path).await?;
let mut buffer = String::new();
file.read_to_string(&mut buffer).await?;
Ok(buffer)
}Futures are cold
fn main() {
let read_from_disk_future = read_from_disk();
}Futures need to be executed
use tokio::{fs::File, io::AsyncReadExt};
#[tokio::main]
async fn main() {
let read_from_disk_future = read_from_disk("Cargo.toml");
let result = async {
let task = tokio::task::spawn(read_from_disk_future);
task.await
}
.await;
println!("{:?}", result);
}
async fn read_from_disk(path: &str) -> std::io::Result<String> {
let mut file = File::open(path).await?;
let mut buffer = String::new();
file.read_to_string(&mut buffer).await?;
Ok(buffer)
}Tasks
- A task connects a future to the executor
- The task is the concurrent unit!
- A task is similar to a thread, but is user-space scheduled
Futures all the way down: Combining Futures
use tokio::fs::File;
use tokio::io::AsyncReadExt;
use tokio::time::Duration;
#[tokio::main]
async fn main() {
let read_from_disk_future = read_from_disk("Cargo.toml");
let timeout = Duration::from_millis(1000);
let timeout_read = tokio::time::timeout(timeout, read_from_disk_future);
let result = async {
let task = tokio::task::spawn(timeout_read);
task.await
}
.await;
println!("{:?}", result);
}Ownership/Borrowing Memory in concurrent systems
- Ownership works just like expected - it flows in and out of tasks/futures
- Borrows work over
.awaitpoints- This means: All owned memory in a Future must remain at the same place
- Sharing between tasks is often done using
Rc/Arc
Categories of Executors
- Single-threaded
- Generally better latency, no synchronisation requirements
- Highly susceptible to accidental blockades
- Harmed by accidental pre-emption
- Multi-threaded
- Generally better resource use, synchronisation requirements
- Harmed by accidental pre-emption
- Deblocking
- Actively monitor for blocked execution threads and will spin up new ones
Reference Counting
- Reference counting on single-threaded executors can be done using
Rc - Reference counting on multi-threaded executors can be done using
Arc
Streams
- Streams are async iterators
- They represent potentially infinite arrivals
- They cannot be executed, but operations on them are futures
Classic Stream operations
- iteration
- merging
- filtering
Async iteration
while let Some(item) = stream.next().await {
//...
}Intro to Tokio
What is Tokio
- Async runtime for Rust
- Provides async version of common I/O
- Provides network APIs and more
More than one project
- Mio
- Tokio Runtime
- Hyper
- Tonic
- Tower
Mio
- Metal I/O
- Lowest layer
Example Mio
let addr = "127.0.0.1:13265".parse()?;
let mut server = TcpListener::bind(addr)?;
// Start listening for incoming connections.
poll.registry()
.register(&mut server, SERVER, Interest::READABLE)?;
// Setup the client socket.
let mut client = TcpStream::connect(addr)?;
// Register the socket.
poll.registry()
.register(&mut client, CLIENT, Interest::READABLE | Interest::WRITABLE)?;Tokio Runtime
- Foundational API
- Async version of common std I/O commands
- Efficient executor for async tasks
Example Tokio
#[tokio::main]
async fn main() {
// Bind the listener to the address
let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap();
loop {
// The second item contains the IP and port of the new connection.
let (socket, _) = listener.accept().await.unwrap();
process(socket).await;
}
}Hyper
- HTTP Client and Server APIs
- Support HTTP/1 and HTTP/2
Example Hyper
#[tokio::main]
async fn main() {
// We'll bind to 127.0.0.1:3000
let addr = SocketAddr::from(([127, 0, 0, 1], 3000));
// A `Service` is needed for every connection, so this
// creates one from our `hello_world` function.
let make_svc = make_service_fn(|_conn| async {
// service_fn converts our function into a `Service`
Ok::<_, Infallible>(service_fn(hello_world))
});
let server = Server::bind(&addr).serve(make_svc);
// Run this server for... forever!
if let Err(e) = server.await {
eprintln!("server error: {}", e);
}
}Others
- Tonic: gRPC Client/Server library
- Tower: Modular server components (retry, load-balance, etc)
- Tracing: Structured tracing and data-collection
- Bytes: Network byte manipulation
Async Implementation Details
Main components of Async/Await
- Tasks
- Wakers
- Executors
- Pin
Tasks
- Every async function that awaits creates tasks
- Effectively “subtasks” of the function
- Tasks describe dependencies
Tasks example
async fn learn_and_sing() {
let song = learn_song().await; // 1
sing_song(song).await; // 2
sing_song(song).await; // 3
}Tasks implementation
- Functions become a state machine
- State machines can restart once progress can be made
- Similar to generators
Wakers
- Polling all the tasks is a busy wait
- Wakers allow us to register a way to wake
Pin
- All types by default can move
- But what if you want to prevent it
- Pin: underlying memory can not move
Pin Example
#[tokio::main]
async fn main() {
let mut stream = async_stream();
let sleep = time::sleep(Duration::from_secs(10));
tokio::pin!(sleep);
loop {
tokio::select! {
maybe_v = stream.next() => {
if maybe_v.is_none() { break }
println!("got = {:?}", maybe_v);
}
_ = &mut sleep => {
println!("timeout: 10 secs elapsed");
break;
}
}
}
}Executors
- Start with the top-level Futures and drive to completions
- Calls
wake()when a task can make progress
Async Component Interaction
Blocking
Blocking is an overloaded term
- Blocking API: an API that might force pre-emption
- Blocked Task: A task that runs for too long
Dealing with blocking in practice
- Blocking APIs are generally faster
- Determining if a task really blocks is hard
It’s hard to determine for a full program if all instances of a task are staying under a certain max execution time.
spawn_blocking
spawn_blockingis usually the solution for dealing with slightly longer tasks
task::spawn_blocking(async {
std::thread::sleep(Duration::from_secs(1000));
});Solution
- Separation of async and sync parts for benchmarking
- Runtime monitoring, mostly through tracing.
Component interaction with channels
- Channels allow communication between tasks
- This allows weak binding between components
- All channels work through Ownership
Threading vs. async
- Threading can be a lot faster in high-throughput situations
- Threading deschedules automatically if threads run out of their timeslice
- Async makes it much cheaper to hold slow and sleepy connections
- Async is very good in reactive models
Models
- Full async
- async at the edge
- Multiple reactors
Example
let (s, r) = mpsc::channel(32);
assert_eq!(s.send("Hello").await, Ok(()));
assert_eq!(r.recv().await, Ok("Hello"));Classes of channels
- Bounded
- Unbounded
- Single Producer, Single Consumer (SPSC)
- Multiple Producers, Single Consumer (MPSC)
- Multiple Producers, Multiple Consumers (MPMC)
- One-Shot
Strategy
- Pick a default one, preferably MPMC.
- Be liberal in using others when needed.
Synchronisation and Locking: Warning
- Avoid std::sync types - they preempt
- There’s a
async_std::syncmodule with API equivalents
Synchronisation and Locking
- Pick types based on your usage pattern
- e.g. RWLocks if Writes are common and reads rare
- Mutex for other situations
- Fairness comes into play here
Channels as synchronisation methods
- Channels act as a natural synchronisation method, as they are read from 1 by 1.
Fairness and starvation
- Fairness describes the property of a combinator to make sure that every side is equally served. If one is not, it may starve.
Async: Avoiding Disaster and Unbounded Growth
Information gathering
Your project is dynamic:
- Make it traceable
- Constantly monitor
Backpressure
Backpressure is the process of “pushing back” on producers that are too fast.
This throttles the system, but allows it to not fail.
Bounded vs. unbounded growth
- Bounded channels are predictable
- Unbounded are more dynamic
- Bounded provide backpressure
- Unbounded are useful if you know they are never beyond a certain size
Holding state
- Tasks can hold state
- Otherwise, Mutexes and RWlocks allow sharing
Dropping futures
- Dropping a future means cancelling it
- Be aware of what happens if it is cancelled
Shutting down
- Make sure your signal handling is centralized
- Every component should subscribe to a cancel notification
Implementing a custom Future: Pinning
- Futures are not allowed to move in Memory
- The type that describes that is called
Pin - Pinning is hard, but there’s support libraries
The poll protocol
Futures are poll based - that means they get asked if they are complete.
- This happens an infinite number of times, until they mark themselves complete
- The process is optimised through the
Wakertype - Implementing poll yourself is rather easy
Overview of Bare-Metal Rust
A Layered Approach
When building bare-metal Systems in Rust, we use Rust crates to help us build a modular system.
The elements in our system are:
- The program you are writing
- The MCU are running on
- The PCB (or Board) your MCU is on
- The external devices connected to your MCU
The Layers
To support these elements, we (usually) have these layers.
- Application
- Board Support
- External Drivers (e.g. SPI LCD Driver)
- Hardware Abstraction Layer Traits
- MCU Hardware Abstraction Layer Implementation
- MCU Peripheral Access Crate
- Core Peripherals
- Core Runtime
—
Don’t worry
There’s a lot here. We’re going to take it step by step, starting at the bottom.
Booting a Cortex-M Microcontroller
In this deck, we’re talking specifically about Arm Cortex-M based microcontrollers.
Other Arm processors, and processors from other companies may vary.
Terms
- Processor - the core that executes instructions
- Peripheral - Hardware block for performing dedicated tasks
- Flash - the non-volatile flash memory that the code and the constants live in
- RAM - the volatile random-access memory that the global variables, heap and stack live in
- SoC - the system-on-a-chip that contains (a) processor(s), some peripherals, and usually some memory
- MCU - A microcontroller unit is a more specialized kind of SoC
Note:
- Examples for peripheral: UART or RNG hardware block.
- MCUs usually include the similar components like an SoC and are designed to run an embedded system. They are usually also less complex.
An example
- Arm Cortex-M4 - a 32-bit processor core aimed at microcontrollers
- Use the
thumbv7em-none-eabiorthumbv7em-none-eabihftargets
- Use the
- nRF52840 - a SoC from Nordic Semi that uses that processor core
An example (2)
- Arm Cortex-M0+ - a smaller, simpler, 32-bit processor core
- Use the
thumbv6m-none-eabitarget
- Use the
- RP2040 - a SoC from Raspberry Pi that has two of those processor cores
Booting a Cortex-M
The Arm Architecture Reference Manual explains we must provide:
The chip does everything else.
Note:
There are fourteen defined Exception Handlers (if the chip does not support a particular Exception, you must use the special value 0x0000_0000). The number of interrupt handlers is defined by the SoC - the Arm NVIC can handle up to 240 interrupts in Armv7-M or 480 interrupts in Armv8-M.
The steps
- Make an array, or struct, with those two (or more) words in it
- Convince the linker to put it at the right memory address
- Profit
C vector table
__attribute__ ((section(".vector_table"))) unsigned long myvectors[] =
{
(unsigned long) &_stack_top,
(unsigned long) rst_handler,
(unsigned long) nmi_handler,
// ...
}
Rust vector table - type definitions
This is possible in Rust as well, but is a bit more involved due to stronger typing rules.
extern "C" {
static mut _stack_top: usize
}
pub struct VectorTable {
stack_top: *const usize,
rst_handler: extern "C" fn(),
nmi_handler: extern "C" fn(),
// ...
}Rust vector table
#[link_section=".vector_table"]
#[no_mangle]
static VECTOR_TABLE: VectorTable = VectorTable {
// Create a raw pointer from the stack top address.
stack_top: &raw const _stack_top,
rst_handler,
nmi_handler,
// ...
}Note:
The cortex-m-rt crate does not use a dedicated VectorTable struct. Instead it places some of the
individual vector table components into dedicated segments and then places all components in the
correct order inside the linker script.
Memory Layout
Most embedded applications written in C/C++ and Rust have a very similar memory and binary layout. Many systems use separate flash and RAM memory regions:

Note:
Some of those memory segments need to be set up by code! .bss is a RAM segment which needs to be
zero-initialized, and .data is a segment in RAM where the initial values are stored in the
flash memory and need to be copied from there.
Some larger embedded applications might also use a heap. In embedded applications, those heaps are
oftentimes also statically allocated and might be a part of the .bss or .uninit segments.
Memory Layout - Unified
Some systems also have a run-time layout where code and data are located in the same memory region:

C Reset Handler
Can be written in C! But it’s hazardous.
extern unsigned long __sidata, __sdata, __edata;
extern unsigned long __sbss, __ebss;
void rst_handler(void) {
unsigned long *src = &__sidata;
unsigned long *dest = &__sdata;
while (dest < &__edata) {
*dest++ = *src++;
}
dest = &__sbss;
while (dest < &__ebss) {
*dest++ = 0;
}
main();
while(1) { }
}
Note:
- This code copies
.datafrom flash to RAM, and zero-initializes the.bssblock. __sidatais the load address in flash.- Global variables are not initialised when this function is executed. What if the C code touches an uninitialised global variable? C programmers don’t worry so much about this because the C language spec does not care about global variables not being initialized when this code runs. Rust programmers definitely worry about this.
- Why is it hazardous? Working with raw pointers is easy to get wrong.
Rust Reset Handler (1)
extern "C" {
// Start and end of the initialized data block (.data).
//`__sidata` is the load address in flash.
static mut __sidata: usize;
static mut __sdata: usize;
static mut __edata: usize;
// Start and end of zero-initialized block (.bss).
static mut __sbss: usize;
static mut __ebss: usize;
}Rust Reset Handler (2)
use core::ptr::{addr_of, addr_of_mut};
#[unsafe(no_mangle)]
pub unsafe extern "C" fn rst_handler() {
unsafe {
let src = addr_of!(__sidata);
let dest = addr_of_mut!(__sdata);
let size = addr_of_mut!(__edata).offset_from(dest);
for i in 0..size {
dest.offset(i).write_volatile(src.offset(i).read());
}
let dest = addr_of_mut!(__sbss);
let size = addr_of_mut!(__ebss).offset_from(dest);
for i in 0..size {
dest.offset(i).write_volatile(0);
}
}
}Sadly, this is UB.
Note:
This is Undefined Behaviour because globals haven’t been initialised yet and it is illegal to
execute any Rust code in the presence of global variables with invalid values
(e.g. a bool with an integer value of 2). It’s also arguably UB because we are violating the rules
of pointer provenance: We are using write_volatile to write outside the bounds the objects we
have declared to Rust (we said that __sdata was only a single u32).
It is now reasonably settled that this is bad in theory, but it’s debatable whether it’s currently bad in practice (cortex-m-rt got away with it for years). I believe that in time it will get worse in practice, so don’t do it.
The cortex-m-rt crate
Does all this work for you, in raw Arm assembly language - so it’s actually sound.
See Reset, Linker script, and Vector table
The #[entry] macro
- Attaches your
fn main()to the reset function in cmrt - Hides your
fn main()so no-one else can call it - Remaps
static mut FOO: Ttostatic FOO: &mut Tso they are safe
Note:
Why does it map static mut FOO: T to static FOO: &mut T?. We can not prove to the compiler that the static mutable variables is actually safe to use (our entry point is just called once, and can not be reached otherwise).
Expand the entry macro by using cargo expand --bin hello. Allowing static_mut_ref is required
to allow static mutable references which clippy is unhappy about. There is actually some discussion
on whether the macro should do this source code manipulation, which might look a little bit
like magic for someone who does not know what is happening.
Using the crate
Linker scripts
- In Rust they work exactly like they do in
clangorgcc - Same
.text,.rodata,.data,.bsssections cortex-m-rtprovideslink.x, which pulls in amemory.xyou supply- You must tell the linker to use
link.x, with:- A build-script
rustflagsin.cargo/config.toml, or- The
RUSTFLAGSenvironment variable
Booting a 32-bit Arm processor
In this deck, we’re talking specifically about classic 32-bit Arm processors.
- ARM7, ARM9, ARM11
- 32-bit Cortex-A
- 32-bit Cortex-R
Other Arm processors, and processors from other companies may vary.
Terms
- Processor - the core that executes instructions
- Peripheral - Hardware block for performing dedicated tasks
- Flash - the non-volatile flash memory that the code and the constants live in
- RAM - the volatile random-access memory that the global variables, heap and stack live in
- SoC - the system-on-a-chip that contains (a) processor(s), some peripherals, and usually some memory
- MCU - A microcontroller unit is a more specialized kind of SoC
Note:
- Examples for peripheral: UART or RNG hardware block.
- MCUs usually include the similar components like an SoC and are designed to run an embedded system. They are usually also less complex.
An example
- Arm Cortex-R52 - a real-time processor core from Arm
- Use the
armv8r-none-eabihf(orthumbv8r-none-eabihf) target
- Use the
- NXP S32Z2 - a SoC that has 8x Cortex-R52 cores (plus six Cortex-M33s and a Cortex-M7)
An example (2)
- Arm Cortex-A7 - an application-class processor core from Arm
- Use the
armv7a-none-eabihf(orthumbv7a-none-eabihf) target
- Use the
- ST STM32MP15x - a SoC that includes two Cortex-A7 cores (and a Cortex-M4)
Booting AArch32
The Arm Architecture Reference Manual explains we must provide:
Each entry is a single Arm jump instruction to the relevant handler function.
Note:
Unlike on Cortex-M, there is no standardised interrupt handling mechanism beyond just “IRQ” and “Fast IRQ” (FIQ), and there is no automatic register stacking. If you want to know why you had an IRQ or FIQ, you need to talk to the interrupt controller and ask it.
The steps
- Write the vector table (and the handler functions) in raw assembly
- Convince the linker to put the table at the right memory address
- Profit
Assembly vector table
.section .vector_table,"ax",%progbits
.arm
.global _vector_table
.type _vector_table, %function
_vector_table:
ldr pc, =_start
ldr pc, =_asm_undefined_handler
ldr pc, =_asm_svc_handler
ldr pc, =_asm_prefetch_abort_handler
ldr pc, =_asm_data_abort_handler
nop
ldr pc, =_asm_irq_handler
ldr pc, =_asm_fiq_handler
.size _vector_table, . - _vector_table
Rust vector table
core::arch::global_asm!(r#"
.section .vector_table,"ax",%progbits
.arm
.global _vector_table
.type _vector_table, %function
_vector_table:
ldr pc, =_start
ldr pc, =_asm_undefined_handler
ldr pc, =_asm_svc_handler
ldr pc, =_asm_prefetch_abort_handler
ldr pc, =_asm_data_abort_handler
nop
ldr pc, =_asm_irq_handler
ldr pc, =_asm_fiq_handler
.size _vector_table, . - _vector_table
"#);Note:
It’s exactly the same assembly code with the same directives, just in a global_asm! block.
Reset Handler
- Arm systems boot with an invalid stack pointer
- C, and Rust, require a stack
- So the reset handler has to be written in assembly
- Once you have a stack, you can jump to C (or Rust) code
Reset Handler (Rust)
- We could ship
.sfiles, and usecc-rsto build them - But
global_asm!lets us use nice Rust constants…
Using const with asm!
core::arch::global_asm!(
"msr cpsr_c, {und_mode}",
"mov sp, r0",
und_mode = const {
Cpsr::new_with_raw_value(0)
.with_mode(ProcessorMode::Und)
.with_i(true)
.with_f(true)
.raw_value()
},
);Note:
Before Rust, you could either use Assembler .macro macros, or feed the assembly source through the C Pre-Processor and use pre-processor macros. Neither was very nice.
The aarch32-rt crate
Does all this work for you, in a mix of inline Arm assembly and Rust
See Reset, Linker script, and Vector table
The #[entry] macro
- Attaches your
fn main()to the reset function in aarch32-rt - Hides your
fn main()so no-one else can call it
Using the crate
Linker scripts
- In Rust they work exactly like they do with
clangorgcc - Same
.text,.rodata,.data,.bsssections aarch32-rtprovideslink.x, which pulls in amemory.xyou supply- You must tell the linker to use
link.x, with:- A build-script
rustflagsin.cargo/config.toml, or- The
RUSTFLAGSenvironment variable
PACs and svd2rust
Introduction
The Peripheral Access Crate crate sits near the bottom of the ‘stack’. It provides access to the memory-mapped peripherals in your MCU.
Memory Mapped Peripherals
- e.g. a UART peripheral
- Has registers, represented by a memory address
- Registers are usually consecutive in memory (not always)
- Peripherals can have instances (same layout of registers, different start address)
- UART0, UART1, etc
Note:
The Universal Asynchronous Receiver Transmitter is an IP block implementing a logic-level RS-232 interface, and one is fitted to basically every microcontroller. Also known as a serial port.
Nordic calls their peripheral UARTE, with the E standing for Easy DMA.
Registers
- Registers are comprised of one or more bitfields.
- Each bitfield is at least 1 bit in length.
- Sometimes bitfields can only take from a limited set of values
- This is all in your datasheet!
C Code
Embedded Code in C often uses shifts and bitwise-AND to extract bitfields from registers.
#define UARTE_INTEN_CTS_SHIFT (0)
#define UARTE_INTEN_CTS_MASK (0x00000001)
#define UARTE_INTEN_RXRDY_SHIFT (2)
#define UARTE_INTEN_RXRDY_MASK (0x00000001)
// The other nine fields are skipped for brevity
uint32_t cts = 0;
uint32_t rxrdy = 1;
uint32_t inten_value = ((cts & UARTE_INTEN_CTS_MASK) << UARTE_INTEN_CTS_SHIFT)
| ((rxrdy & UARTE_INTEN_RXRDY_MASK) << UARTE_INTEN_RXRDY_SHIFT);
*((volatile uint32_t*) 0x40002300) = inten_value;
Rust Code
You could do this in Rust if you wanted…
const UARTE0_INTEN: *mut u32 = 0x4000_2300 as *mut u32;
unsafe { UARTE0_INTEN.write_volatile(0x0000_0003); }But this still seems very error-prone. Nothing stops you putting the wrong value at the wrong address.
Structures in C
In C, the various registers for a peripheral can also be grouped into a struct:
typedef volatile struct uart0_reg_t {
uint32_t tasks_startrx; // @ 0x000
uint32_t tasks_stoprx; // @ 0x004
// ...
uint32_t inten; // @ 0x300
uint32_t _padding[79];
uint32_t baudrate; // @ 0x500
} uart0_reg_t
uart0_reg_t* const p_uart = (uart0_reg_t*) 0x40002000;
Structures in Rust
#[repr(C)]
pub struct Uart0 {
pub tasks_startrx: VolatileCell<u32>, // @ 0x000
pub tasks_stoprx: VolatileCell<u32>, // @ 0x004
// ...
pub inten: VolatileCell<u32>, // @ 0x300
_reserved12: [u32; 79],
pub baudrate: VolatileCell<u32>, // @ 0x500
}
let p_uart: &Uart0 = unsafe { &*(0x40002000 as *const Uart0) };
The
vcell::VolatileCell
type ensures the compiler emits volatile pointer read/writes. But, the reference is unsound.
Note:
svd2rust (later) generates structures that look like this.
Why are the references unsound? The compiler is allowed to insert aribtrary reads
for shared references, e.g. &VolatileCell<u32>. But reads can have side-effects for MMIO.
Access via functions
#![allow(unused)]
fn main() {
pub struct Uart { base: *mut u32 } // now has no fields
impl Uart {
fn write_tasks_stoprx(&mut self, value: u32) {
unsafe {
let ptr = self.base.offset(1);
ptr.write_volatile(value)
}
}
fn read_baudrate(&self) -> u32 {
unsafe {
let ptr = self.base.offset(0x140);
ptr.read_volatile()
}
}
}
let uart = Uart { base: unsafe { 0x40002000 as *mut u32 } };
}Note:
The pointer is a *mut u32 so the offsets are all in 32-bit words, not bytes.
Access via functions (with ZSTs)
#![allow(unused)]
fn main() {
pub struct Uart<const ADDR: usize> {}
impl<const ADDR: usize> Uart<ADDR> {
fn write_tasks_stoprx(&mut self, value: u32) {
unsafe {
let ptr = (ADDR as *mut u32).offset(1);
ptr.write_volatile(value)
}
}
fn read_baudrate(&self) -> u32 {
unsafe {
let ptr = (ADDR as *mut u32).offset(0x140);
ptr.read_volatile()
}
}
}
let uart: Uart::<0x40002000> = Uart {};
}Note:
By itself this seems a small change, but imagine a struct which represents 75 individual peripherals. That’s not impossible for a modern microcontroller. Holding one word for each now takes up valuable RAM!
Code Generation
Can we just generate all this code, automatically?
CMSIS-SVD Files
A CMSIS-SVD (or just SVD) file is an XML description of all the peripherals, registers and fields on an MCU.
We can use svd2rust to turn this into a Peripheral Access Crate.
Note:
Although it is an Arm standard, there are examples of RISC-V based microcontrollers which use the same format SVD files and hence can use svd2rust.
Also be aware that manufacturers often assume you will only use the SVD file to inspect the microcontrollers state whilst debugging, and so accuracy has been known to vary somewhat. Rust groups often have to maintain a set of patches to fix known bugs in the SVD files.
The svd2rust generated API
- The crate has a top-level
struct Peripheralswith members for each Peripheral - Each Peripheral gets a
struct, likeUARTE0,SPI1, etc. - Each Peripheral
structhas methods for each Register - Each Register gets a
struct, likeBAUDRATE,INTEN, etc. - Each Register
structhasread(),write()andmodify()methods - Each Register also has a Read Type (
R) and a Write Type (W)- Those Read/Write Types give you access to the Bitfields
Note:
Earlier versions of svd2rust gave you an API where you’d access the registers
using struct.field syntax, which forced the use of unsound peripheral
references. Now they use a function-based API, but they still have the unsound
peripheral references under the hood.
The svd2rust generated API (2)
- The
read()method returns a special proxy object, with methods for each Field - The
write()method takes a closure, which is given a special ‘proxy’ object, with methods for each Field- All the Field changes are batched together and written in one go
- Any un-written Fields are set to a default value
- The
modify()method gives you both- Any un-written Fields are left alone
Using a PAC
let p = nrf52840_pac::Peripherals::take().unwrap();
// Reading the 'baudrate' bitfield from the 'baudrate' register
let baudrate = p.UARTE1.baudrate().read().baudrate();
// Modifying multiple fields in one go
p.UARTE1.inten().modify(|_r, w| {
w.cts().enabled();
w.ncts().enabled();
w.rxrdy().enabled();
w
});Wait, what’s a closure?
- It’s an anonymous function, declared in-line with your other code
- It can ‘capture’ local variables (although we don’t use that feature here)
- It enables a very powerful Rust idiom, that you can’t easily do in C…
Let’s take it in turns
- I, the callee, need to set some stuff up
- You, the caller, need to do a bit of work
- I, the callee, need to clean everything up
We can use a closure to insert the caller-provided code in the middle of our function. We see this used all (1) over (2) the (3) Rust standard library!
Quiz time
What are the three steps here?
p.UARTE1.inten().modify(|_r, w| {
w.cts().enabled();
w.ncts().enabled();
w.rxrdy().enabled();
w
});Note:
- Read the peripheral MMIO register contents as an integer
- Call the closure to modify the integer
- Write the integer back to the peripheral MMIO register
Documentation
Docs can be generated from the source code.
See https://docs.rs/nrf52840-pac
Note that uarte0 is a module and UARTE0 could mean either a struct type,
or a field on the Peripherals struct.
UPPER_CASE and TitleCase
- Is it weird that it produces
UPPER_CASEfields and types? - There’s now a config file for that
Alternatives
chiptool- forked from svd2rust, but without the singletonsderive-mmio- one struct at a time, with derive-macrossafe-mmio- one struct at a time, with projection macros!
Note:
Chiptool is used by the embassy project.
The derive-mmio crate is from Knurling.
#[derive(derive_mmio::Mmio)]
#[repr(C)]
struct Registers {
#[mmio(Read, Write)]
data: u32,
#[mmio(ReadPure)]
state: State,
#[mmio(ReadPure, Write)]
control: Control,
}
let mut uart_registers = unsafe { Registers::new_mmio_at(0x900_0000) };
uart_registers.write_data(b'x' as u32);See an example.
Note:
The data register is marked (Read, Write) because the default is (PureRead, Write) and reading from the data register has side-effects (it reads from a
hardware FIFO). Fields that are PureRead can be read through &self
references (writes and non-pure reads require &mut self).
The safe-mmio crate is from Google.
#[repr(C)]
use safe_mmio::{ReadWrite, ReadPureWrite, ReadPure, UniqueMmioPointer, field};
struct UartRegisters {
data: ReadWrite<u8>,
status: ReadPure<u8>,
control: ReadPureWrite<u8>,
}
let mut uart_registers: UniqueMmioPointer<UartRegisters> =
unsafe { UniqueMmioPointer::new(NonNull::new(0x900_0000 as _).unwrap()) };
field!(uart_registers, data).write(b'x');Non-Integer Fields
Support is available for bitfields within registers.
Examples:
bitfieldfor the Arm CPSR (docs)bitfieldandderive-mmiocombined for the ARM CMSDK Timer Peripheral
Writing Drivers
- Writing to all those registers is tedious
- You have to get the values right, and the order right
- Can we wrap it up into a nicer, easier-to-use object?
Typical driver interface
let p = pac::Peripherals.take().unwrap();
let mut uarte0 = hal::uarte::Uarte::new(
// Our singleton representing exclusive access to
// the peripheral IP block
p.UARTE0,
// Some other settings we might need
115200,
hal::uarte::Parity::None,
hal::uarte::Handshaking::None,
);
// Using the `uarte0` object:
uarte0.write_all(b"Hey, I'm using a UART!").unwrap();The Hardware Abstraction Layer
- Contains all the drivers for a chip
- Often common/shared across chip families
- e.g. nRF52 HAL for 52832, 52840, etc
- Usually community developed
- Often quite different between MCU vendors
- Different teams came up with different designs!
Kinds of driver
- PLL / Clock Configuration
- Reset / Power Control of Peripherals
- GPIO pins
- UART
- SPI
- I²C
- ADC
- Timer/Counters
- and more!
Handling GPIO pins with code
// Get the singletons
let p = pac::Peripherals.take().unwrap();
// Make a driver for GPIO port P0
let pins = hal::gpio::p0::Parts::new(p.P0);
// Get Pin 13 on port P0 and make it an output
let mut led_pin = hal::gpio::Output::new(pins.p0_13, Level::High);
// Now set the output low.
led_pin.set_low();This differs widely across MCUs (ST, Nordic, Espressif, Atmel, etc). Some MCUs (e.g. Nordic) let you put any function on any pin, and some are much more restrictive!
Correctness by design
- HALs want to make it hard to do the wrong thing
- Is a UART driver any use, if you haven’t configured at least one TX pin and one RX pin?
- Should the UART driver check you’ve done that?
Giving the pins to the driver
// Add all the pins that we want to use for the UART.
let uarte_pins = hal::uarte::Pins {
rxd: pins.p0_08,
txd: pins.p0_06,
cts: None,
rts: None,
};
// The driver automatically configures the pins correctly.
let uarte = hal::uarte::Uarte::new(
periph.UARTE1, uarte_pins, Parity::EXCLUDED, Baudrate::BAUD115200
);This is example is for the nRF52, as used in some of our examples.
The Embedded HAL and its implementations
These things are different
- STM32F030 I²C Driver
- nRF52840 I²C Driver
- But I want to write a library which is generic!
- e.g. a Sensor Driver
How does Rust allow generic behaviour?
- Generics!
where T: SomeTrait
Traits
An example:
#![allow(unused)]
fn main() {
pub trait I2c {
type Error;
fn write_read(
&mut self,
address: u8,
write: &[u8],
read: &mut [u8],
) -> Result<(), Self::Error>;
}
}My Library
struct Co2Sensor<T> {
i2c_bus: T,
...
}
impl<T> Co2Sensor<T> where T: I2c {
fn new(i2c_bus: T) -> Co2Sensor<T> { ... }
fn read_sensor(&mut self) -> Result<f32, Error> { ... }
}Note how Co2Sensor owns the value whose type implements the I2c trait.
My Application
let i2c = stm32f0xx_hal::i2c::i2c1(...);
let sensor = sensor_lib::Co2Sensor::new(i2c);
let Ok(reading) = sensor.read_sensor() else {
// did you unplug it?
};My Application (2)
let i2c = nrf52840_hal::twim::Twim::new(...);
let sensor = sensor_lib::Co2Sensor::new(i2c);
let Ok(reading) = sensor.read_sensor() else {
// did you unplug it?
};
How do we agree on the traits?
- The Rust Embedded Working Group has developed some traits
- They are called the Embedded HAL
- See https://docs.rs/embedded-hal
- All HAL implementations should implement these traits
Blocking vs Non-blocking
- Should a trait API stall your CPU until the data is ready?
- Or should it return early, saying “not yet ready”
- So you can go and do something else in the mean time?
- Or sleep?
- Or should it be an
async fn
Blocking vs Non-blocking
- https://crates.io/crates/embedded-hal
- https://crates.io/crates/embedded-hal-nb
- https://crates.io/crates/embedded-hal-async
Trade-offs
- Some MCUs have more features than others
- The trait design has an inherent trade-off
- Flexibility/Performance vs Portability
Board Support Crates
Using a ‘normal’ PC
- Did you tell your PC it had a mouse plugged in?
- Did you tell it what I/O address the video card was located at?
- No! It auto-discovers all of these things.
- USB, PCI-Express, SATA all have “plug-and-play”
Using an Embedded System
- Plug-and-play is extremely rare
- Your MCU can put different functions (UART, SPI, etc) on different pins
- The choice of which function goes on which pin was decided by the PCB designer
- You now have to tell the software how the PCB was laid out
- i.e UART0 TX is on Port 0, Pin 13
A Board Support Crate
- You can wrap this up into a Board Support Crate
- Especially useful if you are using a widely available dev-kit
- e.g. the nRF52840-DK, or the STM32 Discovery
- Still useful if the board design is an in-house one-off
- Create the drivers and does the pin assignments for you
- Helps make your application portable across different boards
Using a Board Support Crate
See example-code/nrf52/bsp_demo
#[entry]
fn main() -> ! {
let mut nrf52 = Board::take().unwrap();
loop {
writeln!(nrf52.cdc, "On!").unwrap();
nrf52.leds.led_2.enable();
writeln!(nrf52.cdc, "Off!").unwrap();
nrf52.leds.led_2.disable();
}
}Note:
We don’t have to configure the LED pins as outputs. We don’t have to configure the UART pins. The Board Support Crate did it all for us.
Making a Board Support Crate
pub struct Board {
/// The nRF52's pins which are not otherwise occupied on the nRF52840-DK
pub pins: Pins,
/// The nRF52840-DK UART which is wired to the virtual USB CDC port
pub cdc: Uarte<nrf52::UARTE0>,
/// The LEDs on the nRF52840-DK board
pub leds: Leds,
...
/// nRF52 peripheral: PWM0
pub PWM0: nrf52::PWM0,
...
}
impl Board {
fn take() -> Option<Self> { todo!() }
fn new(cp: CorePeripherals, p: Peripherals) -> Self { todo!() }
}Note:
Because constructing the Board struct consumed all the peripherals from the
PAC, it’s important to re-export the ones the BSC didn’t use so that
applications can construct their own drivers using them,.
More things to consider
- Does the MCU start-up on a slow internal oscillator?
- Are there jumpers to control routing on the board?
- SD Cards: should you pick a driver, or let them choose?
- Radios: same question!
Using defmt
defmt is the Deferred Formatter
Motivation
- You have a microcontroller
- You want to know what it is doing
Classical Approach
-
Set up a UART,
-
have a function that writes logs to the UART, and
-
instrument your code with logger calls.
#define INFO(msg, ...) do { \ if (g_level >= LEVEL_INFO) { \ fprintf(g_uart, "INFO: " msg, __VA_ARGS__ ) \ } \ } while(0) INFO("received %u bytes", rx_bytes);
Note:
- Many MCUs use SEGGER RTT instead of UART for debug printouts.
Downsides
- Code size - where do the strings live?
- Waiting for the UART
An idea
- Who actually needs the strings?
- Your serial terminal
- Which is on your laptop…
Do the logging strings even need to be in Flash?
defmt
- Deferred Formatting
- Strings are interned into a
.defmtsection- Is in the ELF file
- Is not in Flash
- Arguments are packed in binary format
- Tools to reconstruct log messages on the host side
Benefits
- Uses less flash space
- Less data to transfer over the wire
Downsides
- Now you need a special viewer tool
- Which needs the exact ELF file your chip is running
Example
let rx_bytes = 300u16;
defmt::error!("received {=u16} bytes", rx_bytes);
This will transmit just: [3, 44, 1]
Note:
The string index we give here as 3, and 44, 1 is 300 encoded as
little-endian bytes.
Type Hints
The braces can contain {[pos][=Type][:Display]}:
pos: a numeric argument position (e.g.0)Type: a type hintDisplay: a display hint
More Examples
defmt::info!("enabled: {=bool}, ready: {=bool}", enabled, ready);
// enabled: true, ready: false
defmt::trace!("{{ X: {0=0..8}, Y: {0=8..16}, Z: {0=16..19} }}", some_bitfield);
// { X: 125, Y: 3, Z: 2 }
defmt::error!("data = {=[u8]:#02x}", some_byte_slice)
// data = [0x00, 0x01, 0x02, 0x03]Note:
The x..y syntax is the bitfield syntax. [u8] is the u8 slice syntax, and
:#02x means two-digit hex in the alternate (0x) style.
Using type hints can produce a more efficient encoding.
Printing structs and enums
#![allow(unused)]
fn main() {
#[derive(Debug)]
struct Data {
x: [u8; 5],
y: f64
}
fn print(data: &Data) {
println!("data = {:?}", data);
}
}Printing structs and enums with defmt
#[derive(defmt::Format)]
struct Data {
x: [u8; 5],
y: f64
}
fn print(data: &Data) {
defmt::info!("data = {=?}", data);
}Note:
The =? is optional, as it is the default. It means render this using the
defmt::Format trait.
In defmt, there is not Debug vs Display distinction - it is up to the host
to decide how best to format the values.
Optionally enabling defmt
- If a library uses
defmt::Format, the application must set up a logger - Portable libraries don’t want this. Instead:
#[cfg_attr(feature = "defmt", derive(defmt::Format))]
struct Data {
x: [u8; 5],
y: f64
}A better transport
- UART is slow
- Background DMA from a ring-buffer is complicated to set up
- Can we do better?
SEGGER RTT
- Real Time Transport
- Dedicated memory area
- Marked with magic numbers
- Can be found and read by your Debug Probe
- Without interrupting the CPU!
- High speed, near-zero-cost byte-pipe
defmt-rtt
- Implement’s SEGGER’s RTT protocol
- Wired up as a defmt global logger
- Your binary just needs to:
use defmt_rtt as _;Note:
The defmt calls in your libraries are able to find the ‘logging sink’ created
by the defmt-rtt crate though the use of a type in defmt-rtt annotated with:
#[defmt::global_logger]This creates a bunch of unsafe #[no_mangle] functions, like:
#[inline(never)]
#[no_mangle]
unsafe fn _defmt_acquire() {
<Logger as defmt::Logger>::acquire()
}Log Level
You can control the log level at compile time with an environment variable:
DEFMT_LOG=info cargo build
Note:
Windows users will use different syntax for cmd.exe vs Powershell.
Host tools
- Knurling’s
probe-runwas the first - The
probe-rsCLI now has support (recommended) - Or use
defmt-print
Using probe-rs
$ probe-rs run --chip nRF52840_xxAA target/thumbv7em-none-eabihf/debug/radio-puzzle-solution
Erasing ✔ [00:00:00] [#########################] 16.00 KiB/16.00 KiB @ 35.52 KiB/s (eta 0s )
Programming ✔ [00:00:00] [#########################] 16.00 KiB/16.00 KiB @ 49.90 KiB/s (eta 0s )
Finished in 0.79s
0 DEBUG Initializing the board
└─ dk::init @ /Users/jp/ferrous-systems/rust-exercises/nrf52-code/boards/dk/src/lib.rs:208
1 DEBUG Clocks configured
└─ dk::init @ /Users/jp/ferrous-systems/rust-exercises/nrf52-code/boards/dk/src/lib.rs:219
Customise the format
$ probe-rs run --chip nRF52840_xxAA ... --log-format oneline
Erasing ✔ [00:00:00] [#########################] 16.00 KiB/16.00 KiB @ 35.52 KiB/s (eta 0s )
Programming ✔ [00:00:00] [#########################] 16.00 KiB/16.00 KiB @ 49.90 KiB/s (eta 0s )
Finished in 0.79s
00:00:00.000000 [DEBUG] Initializing the board (dk dk/src/lib.rs:317)
00:00:00.000000 [DEBUG] Clocks configured (dk dk/src/lib.rs:335)
00:00:00.000000 [DEBUG] RTC started (dk dk/src/lib.rs:354)
Set it as your runner
[target.thumbv7em-none-eabihf]
runner = "probe-rs run --chip nRF52840_xxAA --log-format oneline"
$ cargo run
Finished dev [optimized + debuginfo] target(s) in 0.03s
Running `probe-rs run --chip nRF52840_xxAA --log-format oneline target/thumbv7em-none-eabihf/debug/radio-puzzle-solution`
Erasing ✔ [00:00:00] [#########################] 16.00 KiB/16.00 KiB @ 35.52 KiB/s (eta 0s )
Programming ✔ [00:00:00] [#########################] 16.00 KiB/16.00 KiB @ 49.90 KiB/s (eta 0s )
Finished in 0.79s
00:00:00.000000 [DEBUG] Initializing the board (dk dk/src/lib.rs:317)
00:00:00.000000 [DEBUG] Clocks configured (dk dk/src/lib.rs:335)
00:00:00.000000 [DEBUG] RTC started (dk dk/src/lib.rs:354)
More info
There’s a book!
https://defmt.ferrous-systems.com
Re-entrancy
defmt::info! (etc) can be called anywhere, even from an interrupt.
How do you make that safe?
Critical Sections
- defmt-rtt uses the
critical-sectioncrate - More on this elsewhere
What is Ferrocene?
Ferrocene is
- Rust, not a subset
- A downstream of The Rust Project
- Long-term stable
- Open Source
- Qualified per ISO 26262 (ASIL D) / IEC 61508 (SIL 4)
- Supplied with a warranty
- Available with support
- Tested differently
Rust, not a subset
- We didn’t write a new Rust toolchain
- We qualified The Rust Toolchain
- The subset of Rust for safety-critical, is Rust
A downstream of The Rust Project
- One of the Ferrocene pillars is that the standard library and the compiler must not diverge from upstream.
- We’ve been pulling the
masterbranch ofrust-lang/rustinto our tree since 2021
Patches
- Of course, some changes were required
- So, we upstreamed all of them
- Like [#93717], [#108659], [#111936], [#108898]…
- [#111992], [#112314], [#112418], [#112454], …
Virtuous Cycle
- Sometimes we find bugs that upstream missed
- So we upstreamed the fixes
- Like [#108905] or [#114613].
Long-term Stable
As of 3 September 2024, the Ferrocene releases are:
- nightly (upstream nightly)
- pre-rolling (upstream beta)
- rolling (upstream stable)
- stable-24.05 (upstream 1.76)
- stable-24.08 (upstream 1.79)
Note:
We strive to make each stable release available for two years, including tracking of Known Problems. The nightly, pre-rolling and rolling releases do not carry our stability or support guarantees - they only apply to our stable-xxx releases. See https://public-docs.ferrocene.dev/main/qualification/plan/release.html for details.
Open Source
- Ferrocene lives at https://github.com/ferrocene/ferrocene
- The source code is MIT || Apache-2.0
- The docs are published at https://public-docs.ferrocene.dev
Qualified per ISO 26262 (ASIL D) / IEC 61508 (SIL 4)
We’re in the TÜV SÜD database

cargo isn’t qualified
- Qualifying a tool that touches the Internet is hard
- You don’t need a build system…
- You can just call
rustc(which is qualified) from a simple script for production
libstd isn’t certified, libcore will be
- It doesn’t make sense to certify the Standard Library
- It’s mostly “If Windows, do X; if POSIX, do Y”
- We are looking at certifying
libcore
Supplied with a warranty
If you find a bug in the compiler, we will fix it or give you details on how to work around it
Available with support
- A subscription gets you binary downloads and access to the Known Problems list
- Signed Qualification Documents are available (call us)
- If you need additional support with your Rust development, we can help
Tested Differently
- The Rust Project only tests Tier 1 targets
- We have developed our own CI
- Separate and parallel to that used by The Rust Project
- They have different goals!
- Having multiple independent, parallel, rock solid CI pipelines can only benefit Rust
- Our CI produces the artefacts we need for qualification
Installing and Using Ferrocene
What’s in the box?
rustc- a compiler (★)lld- the LLVM linker (★)rustdoc- the docs generator
cargo/rustfmt/clippy- our usual friendsllvm-tools- objcopy, size, etcrust-analyzer- for IDE integrationrust-src- libstd source coderust-std-xxx- precompiled standard libraries (☆)ferrocene-self-test- checks your installationferrocene-docs-xxx- documentation
★: qualified tool ☆: certification in progress
Note:
The lld linker and rustdoc come with the rustc-${rustc-host} package.
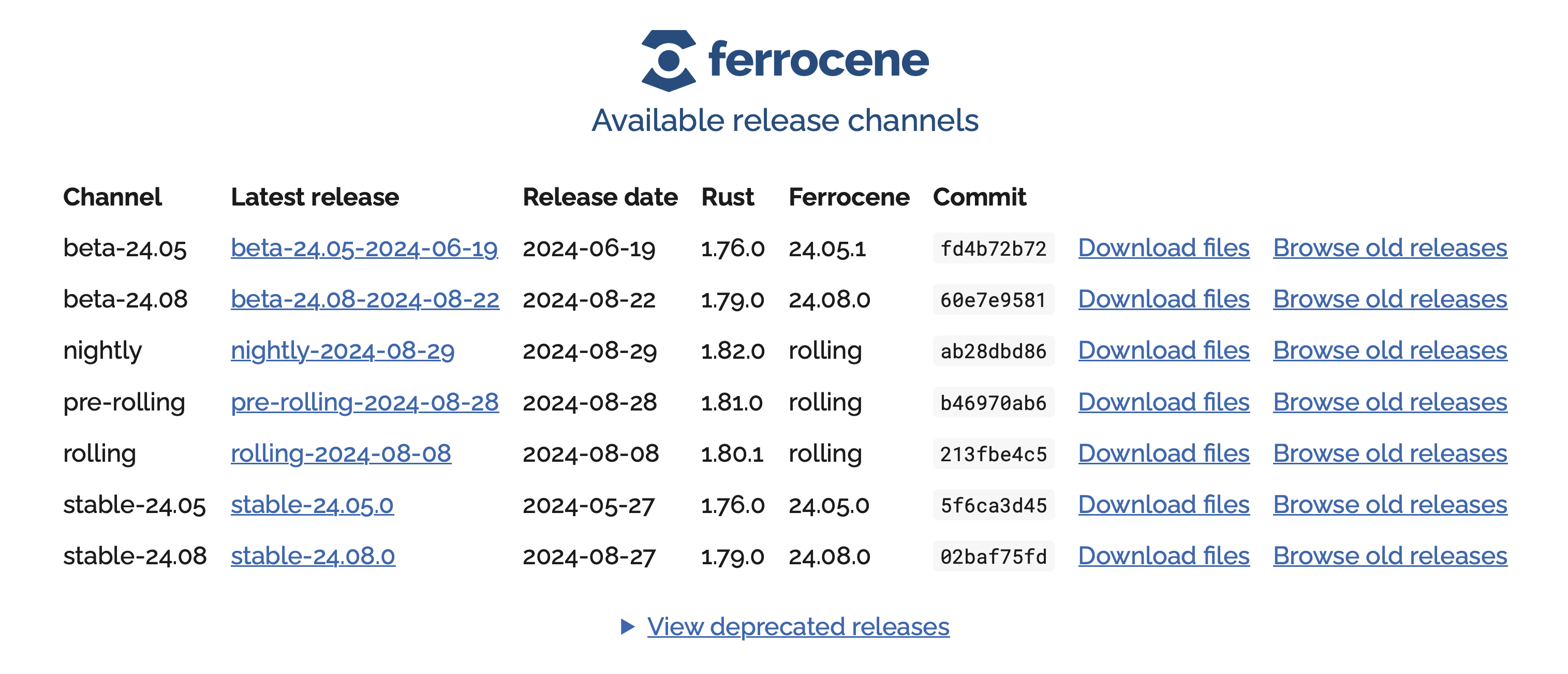
https://releases.ferrocene.dev
Note:
channels contain releases
Examples of channels include:
- nightly
- pre-rolling
- rolling
- beta-24.05
- beta-24.08
- stable-24.05
- stable-24.08
- etc
Examples of releases include:
- nightly-2024-08-29
- pre-rolling-2024-08-28
- rolling-2024-08-08
- beta-24.05-2024-06-19
- beta-24.08-2024-08-22
- stable-24.05.0
- stable-24.08.0
- etc
See https://public-docs.ferrocene.dev/main/qualification/plan/release.html for details about our release channels.
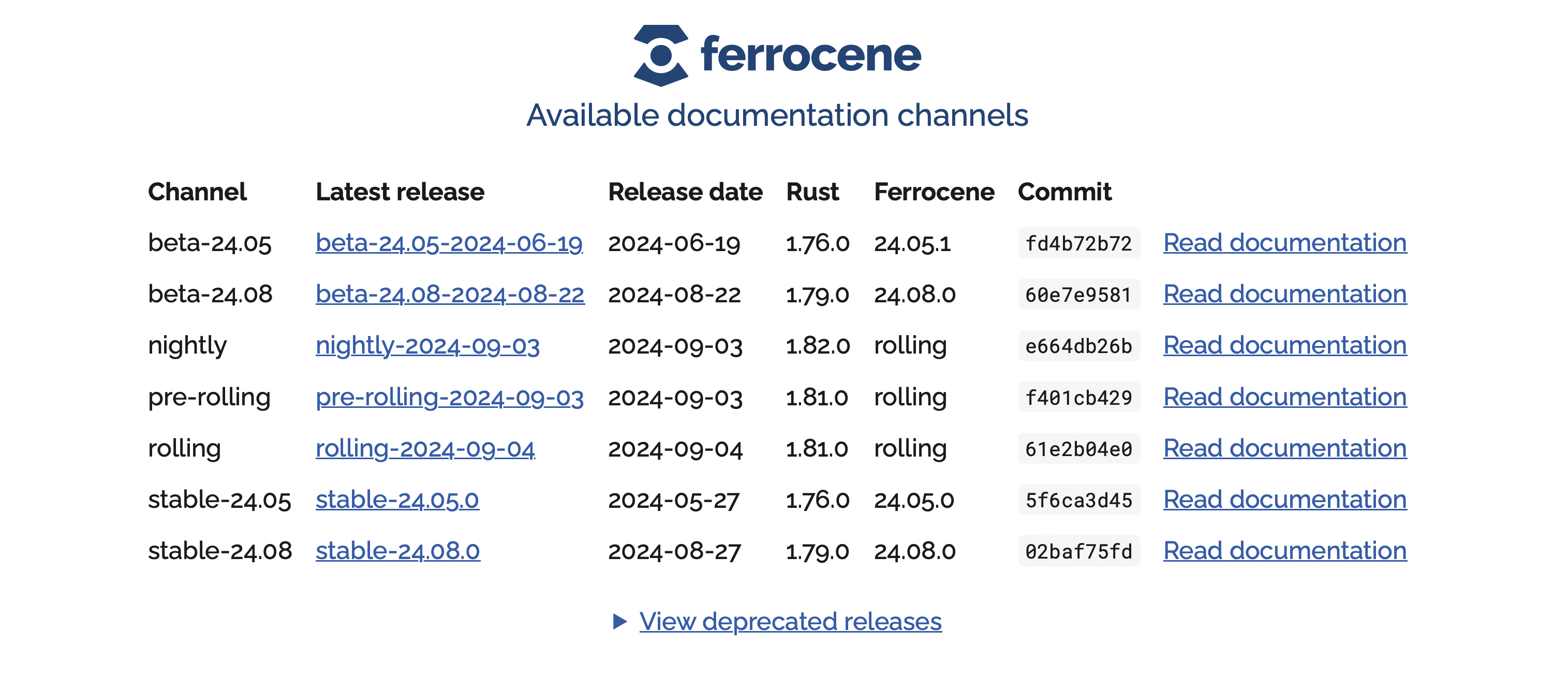
Targets
We have two dimensions:
- Qualified, or not
- Host or Cross-compiled
Qualified Targets
- Production Ready
- Passes the Rust Test Suite
- Support is available
- Signed qualification material
- stable channel only
Note:
In stable-24.08 and earlier, these were called “Supported Targets”
Each release has a User Manual and it is important to follow the instructions for that target in that release otherwise you may be outside the qualification scope. As an example, we don’t let you give arbitrary arguments to the linker - you can only pass the arguments we say are OK.
Quality Managed (QM) Targets
- Production Ready
- Passes the Rust Test Suite
- Support is available
Signed qualification material
Note:
It may be that the target is en-route to being a Qualified Target, or it may be that it is deemed unlikely that the target would be useful in a safety critical context. Talk to us if you would like a QM Target available as a Qualified Target.
Experimental Targets
- Not Production Ready
- Not qualified
- Might not pass the test suite
- But useful for getting started early
Note:
A Ferrocene ‘Experimental Target’ is broadly equivalent to an upstream Tier 2 or Tier 1 target, depending on whether we’re running the Test Suite in CI. And, to be fair, plenty of people use upstream Rust in production.
Host Targets
- Ferrocene runs on a limited number of hosts:
- Ferrocene is installed with
criticalup- It’s also open-source
- Or, you can install a specific Ferrocene release from tarballs
- Hosts always compile for themselves (proc-macros,
build.rs, etc)
Cross-Compilation Targets
- Compiling for a machine that is not the current host
- The list of targets may change from release to release
- See the public docs
- Or the customer portal
Using criticalup
- Our equivalent of
rustup - Fetches the appropriate Ferrocene toolchain packages
- Packages are signed with
criticaltrust
- Packages are signed with
- Need a
criticalup.tomlfile for each project, and a global login token- Token only required to download a toolchain
- You can burn the toolchain to a CD-R if you want
criticalup.toml
manifest-version = 1
[products.ferrocene]
release = "stable-24.08.0"
packages = [
"rustc-${rustc-host}", "rust-std-${rustc-host}", "cargo-${rustc-host}",
"rust-src", "rust-std-aarch64-unknown-none"
]
Installing Ferrocene
- Install criticalup
- Make a token
- Store your token with
criticalup auth set - Go to your project dir
- Run
criticalup install
Example
$ criticalup auth set
$ criticalup install
info: installing product 'ferrocene' (stable-24.08.0)
info: downloading component 'cargo-x86_64-unknown-linux-gnu' for 'ferrocene' (stable-24.08.0)
...
info: downloading component 'rustc-x86_64-unknown-linux-gnu' for 'ferrocene' (stable-24.08.0)
info: installing component 'rustc-x86_64-unknown-linux-gnu' for 'ferrocene' (stable-24.08.0)
$ criticalup run rustc --version
Local State
Criticalup maintains local state in one of the following locations:
- Linux:
~/.local/share/criticalup - macOS:
~/Library/Application Support/criticalup - Windows:
%APPDATA%\criticalup
Running Ferrocene
You can execute the tool directly from the install dir
$ criticalup which rustc
/home/user/.local/criticalup/toolchains/cbfe2b...21e8b/bin/rustc
$ /home/user/.local/criticalup/toolchains/cbfe2b...21e8b/bin/rustc --version
rustc 1.79.0 (02baf75fd 2024-08-23) (Ferrocene by Ferrous Systems)
NB: cargo uses whichever rustc is in your PATH.
You can use the tool proxies:
$ ls /home/user/.local/criticalup/bin
cargo rust-gdb rust-gdbgui rust-lldb rustc rustdoc
$ /home/user/.local/criticalup/bin/rustc --version
rustc 1.79.0 (02baf75fd 2024-08-23) (Ferrocene by Ferrous Systems)
NB: cargo uses the corresponding rustc
You can use criticalup as a proxy:
$ criticalup run rustc --version
rustc 1.79.0 (02baf75fd 2024-08-23) (Ferrocene by Ferrous Systems)
NB: cargo uses the corresponding rustc
rust-analyzer in VS Code
Set RUSTC to tell it which rustc to use
$ RUSTC=$(criticalup which rustc) code .
PS D:\project> $Env:RUSTC=$(criticalup which rustc)
PS D:\project> code .
Ensure you have the rust-src package installed.
Our Rust Training has both 32-bit and 64-bit Arm bare-metal examples:
https://github.com/ferrous-systems/rust-training/tree/main/example-code
What is Rust?
- The 100-foot view
- Where did Rust come from?
- Who’s in charge now?
- Is this a community I can engage with?
- What does Rust run on?
- What does Rust cost?
- Can I build safety-critical systems?
The 100-foot view
A free and open-source systems programming language
A language empowering everyone to build reliable and efficient software.
Hello, World
fn main() {
println!("Hello, world!");
}You can build…
- Network Services
- Command-line Apps
- Web Apps
- Desktop Apps
- Bootloaders
- Device Drivers
- Hypervisors
- Embedded Systems
- Libraries/plugins for applications in other languages
Front-end or Back-end?
It’s applicable at every point in the stack!
The Three Words
- Safety
- Performance
- Productivity
It’s enduringly popular
Rust continues to be the most-admired programming language with an 83% score this year
Note:
Stack Overflow used to use the term most loved, which Rust won seven years in a row. In 2023 they changed the terms to desired and admired. Rust was the most admired language in 2023 and 2024.
Cross-platform
- Windows, macOS, Linux
- iOS, Android, Web, QNX, Bare-metal, etc
Portable
- Source code is portable across multiple architectures:
- x86, RISC-V and Arm
- Power, MIPS, SPARC, …
Rust can import C-compatible libraries
Want to use zlib, OpenSSL, SomeSpecialDriverLib? Sure!
Rust can export C-compatible libraries
- Python extension modules? Ok!
- Android native libraries? No problem.
- Replace the file parser in your Very Large C++ Application? Can-do.
Where did Rust come from?
A Little Bit of History
- Rust began around 2008
- An experimental project by Graydon Hoare
- Adopted by Mozilla
- Presented to the general public as version 0.4 in 2012
Focus
- Rust lost many features from 2012 to 2014
- garbage collector
- evented runtime
- complex error handling
- etc
- Rust oriented itself towards being a usable systems programming language
Development
- Always together with a larger project (e.g. Servo)
- Early adoption of regular releases
- RFC process
- Editions
Public Release
- First 1.0 release in 2015
- https://blog.rust-lang.org/2015/05/15/Rust-1.0.html
- “This release is the official beginning of our commitment to stability”
- New release every six weeks since
Who’s in charge now?
The Rust Project
https://www.rust-lang.org/governance
- The Leadership Council
- Compiler Team
- Dev Tools Team
- Infrastructure Team
- Language Team
- Library Team
- Moderation Team
- Launching Pad Team
Working Groups
- Async WG
- Command-line Interface WG
- Embedded devices WG
- Game Development WG
- Rust by Example WG
- Secure Code WG
- Security Response WG
- WebAssembly (WASM) WG
The Rust Foundation
… is an independent non-profit organization dedicated to stewarding the Rust programming language, nurturing the Rust ecosystem, and supporting the set of maintainers governing and developing the project.
It has a powerful list of members
https://foundation.rust-lang.org/members/
Who decides on new features?
- Discuss in chat/forums
- Open a Request For Change (RFC)
- Relevant team takes a vote
- Tracking ticket is created
- Pull Request(s) to implement the change
- Stabilisation
Summary
- Rust is a collaborative open-source project that prides itself on inclusion
- There is no “owner”, nor “BDFL”
- It has strong financial backing
- It remains a work-in-progress
Is this a community I can engage with?
A strong Code of Conduct
The Rust Project, and pretty much the whole Community, follow a Code of Conduct:
We are committed to providing a friendly, safe and welcoming environment for all, regardless of level of experience, gender identity and expression, sexual orientation, disability, personal appearance, body size, race, ethnicity, age, religion, nationality, or other similar characteristic.
A strong Code of Conduct
Likewise any spamming, trolling, flaming, baiting or other attention-stealing behavior is not welcome.
- Builds on efforts in other communities
Why?
- Because a community is only as strong as its members
Going beyond technical points, Rust has a vibrant, welcoming community - (Stack Overflow Blog)
Why?
- If you allow both wolves and sheep into your space, you won’t get any sheep
- The Rust Community seems to have a higher than average representation from the LGBTQI+ community
So beginners are welcome?
- Absolutely!
- Relatively speaking, we’re all still beginners
- You even see open tickets on the rust-lang Github marked as E-easy: Good first issue.
This extends to the compiler’s interface…
- Any Rust error message which is unclear or ambiguous…
- … is considered a bug and will be fixed …
- … if you open a ticket (or post @ the right people)
Compiler Error Driven Development works!
error[E0502]: cannot borrow `name` as mutable because it is also borrowed as immutable
--> src/main.rs:4:5
|
3 | let nickname = &name[..3];
| ---- immutable borrow occurs here
4 | name.clear();
| ^^^^^^^^^^^^ mutable borrow occurs here
5 | println!("Hello there, {}!", nickname);
| -------- immutable borrow later used here
Some errors have detailed explanations: E0502, E0596.
For more information about an error, try `rustc --explain E0502`.
What does Rust run on?
Host vs Target
- The machine you develop on
- The machine the program runs on
Rust is a cross-compiler
- It uses LLVM to generate machine code
- Every Rust install is a cross-compiler
- No rummaging for extra installers for your specific target
Hosts
- Windows (x86-64, x86, AArch64)
- Linux (x86-64, x86, AArch64, AArch32, RISC-V, PowerPC, S390)
- macOS (x86-64, AArch64)
- plus FreeBSD, NetBSD and Illumos
Targets
- All of the above, plus…
- Android
- iOS/watchOS/tvOS
- Bare-metal Embedded
- QNX, VxWorks, AIX
- WebAssembly
- UEFI
- Nintendo Switch, Sony PSP and PS Vita…
- Add your own!
What does Rust cost?
Rust is Open Source
- Under the MIT or Apache-2.0 licences
- You can compile
rustcandcargoyourself - https://github.com/rust-lang/rust
Binaries are provided free of charge
- Available using the
rustuptool - AWS sponsor the project
- Nothing to sign, no USB dongle required
Support is available
- There are lots of places you can go for help
- Forums, Discord, Reddit
- Professional consulting firms
- Rust Toolchain vendors
No-one is an expert overnight
- Budget for some training
- Budget for some time for the team to gain experience
- Budget for some support when the team have questions
You might need a bigger computer…
Today, compiling the Rust compiler on a 4-core CPU, that is typically found in a standard laptop, takes up to 15 minutes with another 5-10 minutes for tests. However, a 96-core cloud virtual machine can complete the same build in less than 5 minutes with tests completing in 35 seconds.
Compile time checks vs run-time checks
- Rust does a lot of work up front
- The faster your checks run, the more productive you are!
- A Raspberry Pi 4 technically works, but it takes a while…
Can I build safety-critical systems?
Some terminology
- a system is certified as being sufficiently safe/correct
- that system is often built using qualified tools
- quality is the result of an ongoing process
Note:
Some industries use the terms certification and qualification interchangeably.
What is a safety-critical system?
Generally built following a standard, like ISO 26262:
ISO 26262 is intended to be applied to safety-related systems that include one or more electrical and/or electronic (E/E) systems and that are installed in series production passenger cars with a maximum gross vehicle mass up to 3500 kg.
What is a safety-critical system?
Generally built following a standard, like ISO 26262:
This document describes a framework for functional safety to assist the development of safety-related E/E systems. This framework is intended to be used to integrate functional safety activities into a company-specific development framework.
And for other applications:
- DO-178C Software Considerations in Airborne Systems and Equipment Certification
- IEC 61508 Functional Safety of Electrical/Electronic/Programmable Electronic Safety-related Systems
- IEC 62278 Railway applications - Specification and demonstration of reliability, availability, maintainability and safety
- IEC 62034 Medical device software – Software life cycle processes
- There are many others…
Can I use Rust?
- Well you can use C
- And C is kinda risky…
- But processes have been developed to manage that risk
- And C toolchains have been qualified so you can rely on them doing what they say
they are going to do
- If you hold them the right way
Language Specifications
- C has ISO/IEC 9899:2018 (C17)
- C++ has ISO/IEC 14882:2020(E) (C++20)
- Rust doesn’t have a standard
- The open-source compiler is the standard
- The first ISO C standard (C90) came 17 years after C was invented, largely because there were a lot of different competing compilers
Ferrocene
Ferrocene is the open-source qualified Rust compiler toolchain for safety- and mission-critical. Qualified for automotive and industrial development.
ISO26262 (ASIL D) and IEC 61508 (SIL 4) available for x86 and ARM platforms.
Ferrocene
- To produce Ferrocene, we first wrote the Ferrocene Language Specification
- See https://spec.ferrocene.dev
- It’s being upstreamed as the official spec
- Ferrocene is based on the open-source Rust compiler
- Additional testing and run-time checks in the toolchain
- Lots of documentation!
- Ferrocene itself is open-source software
- Pricing and support options at https://ferrocene.dev
- Other companies have similar offerings
- The 100-foot view
- Where did Rust come from?
- Who’s in charge now?
- Is this a community I can engage with?
- What does Rust run on?
- What does Rust cost?
- Can I build safety-critical systems?
Safety, Performance and Productivity
1) Safety
Rust is memory-safe
- Every value has one owner
- You can create either:
- One exclusive, mutable, reference
- Multiple shared, immutable, references
- Never both!
- These rules are checked at compile time
- Or at run-time if you choose
- Rust applies bounds checks to array and slice accesses
- Where possible (e.g. the indices are constant) those checks are optimized out
Index Example
#![allow(unused)]
fn main() {
fn process(items: &mut [i32]) {
items[10] = 6;
}
}If items isn’t long enough, this raises a run-time panic instead of corrupting
memory.
Iter Example
/// Adds 0x00 padding for every 0xCC found
fn process(data: &mut Vec<u8>) {
for item in data.iter_mut() {
if *item == 0xCC {
data.push(0);
}
}
}Rust won’t let you modify the Vec<u8> whilst you iterate through it - this
breaks the rules around exclusive borrows.
Note:
This is trivial to do in C++ and causes silent corruption.
Iter Example (fixed)
#![allow(unused)]
fn main() {
/// Adds 0x00 padding for every 0xCC found
fn process(data: &mut Vec<u8>) {
let padding_byte_count = data.iter().filter(|&&x| x == 0xCC).count();
for _ in 0..padding_byte_count {
data.push(0);
}
}
}Rust is thread-safe
- Types must be marked as safe for:
- Transferring ownership between threads, and/or
- Transferring a reference between threads
- You cannot create race-hazards!
APIs can reason about thread-safety
- Rust channels require types to be marked as thread-safe
- Passing values when starting a spawned thread - same checks
- The ref-counting allocation type
Rc<T>is not thread-safe - The atomic-ref-counting allocation type
Arc<T>is (but is slightly slower) - Make the wrong choice? Compiler stops you!
Thread Example
fn main() {
let mut total = 0;
for _ in 0..10 {
std::thread::spawn(|| {
total += 1;
});
}
println!("{total}");
}Note:
- Failure 1 - threads can live forever, but they are trying to borrow a variable on the stack of the main function
- Failure 2 - multiple threads trying to take mutable (exclusive) access to a variable
Thread Example (Fixed)
use std::sync::atomic::{AtomicU32, Ordering};
fn main() {
let total = AtomicU32::new(0);
std::thread::scope(|s| {
for _ in 0..10 {
s.spawn(|| total.fetch_add(1, Ordering::Relaxed));
}
});
println!("{}", total.load(Ordering::Relaxed));
}There’s an escape hatch
- Where the compiler cannot verify the rules are upheld, you can tell it you’ve done the checks manually
- We create
unsafe { }blocks andunsafe fnfunctions - Lets you access raw pointers (e.g. for memory-mapped I/O)
- When you audit/review the code, you pay close attention to these parts!
2) Performance
A Comparison
Let’s use Python to calculate the sum of the cubes of the first 100 million integers.
import datetime
start = datetime.datetime.now()
cube_sum = sum(
map(
lambda x: x * x * x,
range(0, 100_000_000)
)
)
print(f"Took {datetime.datetime.now() - start}")
print(f"cube_sum = {cube_sum}")
>>> run()
Took 0:00:09.076986
24999999500000002500000000000000
In Rust?
fn main() {
let start = std::time::Instant::now();
let sum: u128 = (0..100_000_000u32)
.into_iter()
.map(|n| {
let n = u128::from(n);
n * n * n
})
.sum();
println!("Took {:?}", start.elapsed());
println!("sum = {sum}");
}$ cargo run --release
Compiling process v0.1.0 (/Users/jonathan/process)
Finished release [optimized] target(s) in 0.34s
Took 45ns
sum = 24999999500000002500000000000000
OK, but it’s cheating
fn main() {
let start = std::time::Instant::now();
let sum: u128 = (0..100_000_000u32)
.into_iter()
.map(|n| {
let n = u128::from(n);
std::hint::black_box(n * n * n)
})
.sum();
println!("Took {:?}", start.elapsed());
println!("sum = {sum}");
}$ cargo run --release
Compiling process v0.1.0 (/Users/jonathan/process)
Finished release [optimized] target(s) in 0.34s
Took 68.014583ms
sum = 24999999500000002500000000000000
Let’s use all our CPU cores…
// Import the rayon library
use rayon::prelude::*;
fn main() {
let start = std::time::Instant::now();
// Swap `into_iter` for `into_par_iter`
let sum: u128 = (0..100_000_000u32)
.into_par_iter()
.map(|n| {
let n = u128::from(n);
std::hint::black_box(n * n * n)
})
.sum();
println!("Took {:?}", start.elapsed());
println!("sum = {sum}");
}Let’s use all our CPU cores…
$ cargo add rayon
Updating crates.io index
Adding rayon v1.6.1 to dependencies.
$ cargo run --release
...
Compiling rayon v1.6.1
Compiling process v0.1.0 (/Users/jonathan/process)
Finished release [optimized] target(s) in 2.38s
Running `target/release/process`
Took 9.928125ms
sum = 24999999500000002500000000000000
Sure, but C can do this too, right?
$ clang -o ./target/main src/main.c -O3 -mcpu=native -std=c17 && ./target/main
sum 0x13b8b5ae675d38cb7260b704000
Took 70.3 milliseconds
And was getting that performance … enjoyable?
#include <stdint.h>
#include <stdio.h>
#include <inttypes.h>
#include <time.h>
int main(int argc, char** argv) {
uint64_t start = clock_gettime_nsec_np(CLOCK_MONOTONIC);
__uint128_t x = 0;
for(uint32_t idx = 0; idx < 100000000; idx++) {
__uint128_t i = (__uint128_t) idx;
volatile __uint128_t result = i * i * i;
x += result;
}
uint64_t end = clock_gettime_nsec_np(CLOCK_MONOTONIC);
printf("sum 0x%08llx%08llx\n", (unsigned long long) (x >> 64), (unsigned long long) x);
printf("Took %.3g milliseconds\n", ((double) (end - start)) / (1000.0 * 1000.0) );
return 0;
}
3) Productivity
libstd
- Filesystem access and Path handling
- Heap allocation, with optional reference-counting
- Threads, with Mutexes, Condition Variables, and Channels
- Strings, and a powerful value formatting system
- Growable arrays, hash-tables, B-Trees
- First-class Unicode text support
- Networking support (IPv4/IPv6, TCP/UDP, etc)
- I/O traits for working with files, strings, sockets, etc
- Time handling: Duration and Instant
- Environment Variables and CLI arguments
Much less time chasing down weird bugs
- If it compiles, it’ll probably work right
- No data races across threads
- No double frees, buffer overflows
Async Programming
- Third-party libraries (e.g. tokio) give you all that but with an asynchronous API
- Great if your code spends a lot of time waiting (for the disk, for the network)
Tools like rust-analyzer have powerful auto-completion
- Filling in functions to meet a trait definition
- Covering all the arms in a match expression
- Importing modules or qualifying a given type
Built in testing
- The test-runner compiles and runs:
- All your unit tests
- All your integration tests
- All the code examples in your docs!
- It also compiles all your examples
It’s completely cross-platform
- Windows, Linux and macOS devs all working with the same tools
- You can build stand-alone binaries that are trivial to deploy
Tradeoffs
OK, but what’s the catch?
You can’t write C in Rust
- You have to think about memory up-front
- Who owns any given value?
- Who needs to borrow it and when?
- Does it live long enough to satisfy those borrows?
- Are you borrowing something that might move?
Rust exposes underlying complexity
- There are at least six kinds of “String” in Rust
- Owned or Borrowed, Rust-native, C-compatible and OS API-compatible
- There is no garbage collector - you manage your own memory
- Maybe you’d be OK with the performance of Go, or C# or Java?
Rust doesn’t interact well with C++ code
- Rust doesn’t understand classes or templates
- Neither Rust nor C++ have a stable ABI
- Projects do exist to auto-generate bindings, like cxx
Touching the hardware requires unsafe
Hardware is a blob of shared mutable state and you have to manually verify your access to it is correct
What you have works just fine
If it’s safe enough, maintainable enough and fast enough, then you should keep it!
Definitely don’t do too many new things at once.
It’s early days for building critical-systems in Rust
Ferrocene is good, but C and Ada have a multi-decade head start
Is the juice worth the squeeze?
Only you can decide!
But we can show you what other people have found…
Some quotes…
- Mozilla
- Microsoft
- CISA
- Amazon
- Linux Kernel
- Cloudflare
- Dropbox
- Meta
- Infineon
- Volvo
Mozilla
With the release of Firefox 48, we shipped the very first browser component to be written in the Rust programming language — an MP4 parser for video files. Streaming media files in your browser can be particularly risky if you don’t know or trust the source of the file, as these can maliciously take advantage of bugs in a browser’s code. Rust’s memory-safe capabilities prevent these vulnerabilities from being built into the code in the first place.
Microsoft
We believe Rust changes the game when it comes to writing safe systems software. Rust provides the performance and control needed to write low-level systems, while empowering software developers to write robust, secure programs.
Speaking of languages, it’s time to halt starting any new projects in C/C++ and use Rust for those scenarios where a non-GC language is required. For the sake of security and reliability, the industry should declare those languages as deprecated.
– Mark Russinovich, CTO Azure (2022)
Note:
Microsoft are following up on this. As of October 2024, there is Rust in the Windows 11 kernel, and user-land APIs like DWriteCore are (at least partially) written in Rust.
More than 2/3 of respondents are confident in contributing to a Rust codebase within two months or less when learning Rust.
Anecdotally, these ramp-up numbers are in line with the time we’ve seen for developers to adopt other languages, both inside and outside of Google.
– Google Open Source Blog (2023)
Rust teams at Google are as productive as ones using Go, and more than twice as productive as teams using C++.
and
In every case, we’ve seen a decrease by more than 2x in the amount of effort required to both build the services written in Rust, as well as maintain and update those services. […] C++ is very expensive for us to maintain.
– Lars Bergstrom, Google (2024)
…the percentage of memory safety vulnerabilities in Android dropped from 76% to 24% over 6 years as development shifted to memory safe languages.
We see the (Safe Coding) shift showing up in important metrics such as rollback rates (emergency code revert due to an unanticipated bug). The Android team has observed that the rollback rate of Rust changes is less than half that of C++.
CISA
There are, however, a few areas that every software company should investigate. First, there are some promising memory safety mitigations in hardware. … Second, companies should investigate memory safe programming languages.
– “The Urgent Need for Memory Safety in Software Products”, CISA (2023)
Note:
CISA is the US Government’s Cybersecurity and Infrastructure Security Agency
Amazon
Here at AWS, we love Rust, too, because it helps AWS write highly performant, safe infrastructure-level networking and other systems software. … we also use Rust to deliver services such as S3, EC2, CloudFront, Route 53, and more … Our Amazon EC2 team uses Rust as the language of choice for new AWS Nitro System components…
Linux Kernel
Like we mentioned last time, the Rust support is still to be considered experimental. However, support is good enough that kernel developers can start working on the Rust abstractions for subsystems and write drivers and other modules.
– Linux Kernel Mailing List (2022)
Note:
- Asahi Linux wrote the Apple Silicon GPU driver in Rust.
- The new Nova open-source driver for nVidia GPUs will be written in Rust.
Dropbox
We wrote Nucleus in Rust! Rust has been a force multiplier for our team, and betting on Rust was one of the best decisions we made. More than performance, its ergonomics and focus on correctness has helped us tame sync’s complexity. We can encode complex invariants about our system in the type system and have the compiler check them for us.
Cloudflare
In production, Pingora consumes about 70% less CPU and 67% less memory compared to our old service with the same traffic load.
Meta
[Our Rust Engineers] came from Python and Javascript backgrounds. They appreciated Rust’s combination of high performance with compile-time error detection. As more success stories, such as performance improvements at two to four orders of magnitude, circulated within the company, interest grew in using Rust for back-end service code and exploring its use in mobile apps as well.
Infineon
With Infineon’s support, we can expect Rust’s usage in Embedded Systems to become more widespread, standardizing the usage of Rust in the industry while engaging with the Rust FOSS community.
– Infineon Developer Community Blog (2023)
SEGGER
Rust is fast, memory-efficient and safe. With first-class tool support, it has the potential to overtake C and C++.
Volvo
I always had the feeling, is Rust too good to be true? I’m always looking for the big pitfall. So far I have not found anything bad. Only some small things…
[We have] a bigger and bigger pile of proof that Rust does actually work well.
– Julius Gustavsson, Volvo (2024)
Note:
As of October 2024, the Volvo EX30 and the Polestar 3 are shipping with some firmware written in Rust, particular in the Low-Power ECU.
Volvo
I think we’re at that point where instead of asking ‘Can we use Rust for this?’, we should be asking ‘Why can’t we use Rust for this?’
– Julius Gustavsson, Volvo (2024)
Where Next?
On-line Self-Taught Courses
- Take your first steps with Rust (from Microsoft)
- Rust By Example
- Comprehensive Rust (from Google)
Desktop-based Self-Taught Courses
- Rustlings
Project Documentation
- Standard Library Docs
- Cargo
- Rustdoc
- Rustc
Ferrocene Documentation
https://public-docs.ferrocene.dev
Working Group Materials
- The Embedded Book
- The CLI Book
- The WebAssembly Book
Online Books
- The Rust Book
- https://doc.rust-lang.org/book/
- Also available in print
- Rust Atomics and Locks (Concurrency in Practice)
- https://marabos.nl/atomics/
- Also available in print
Print Books and eBooks
- Rust in Action
- Rust for Rustaceans
Consultancy and Support
There are a growing number of Rust-based consultancies.
Professional Training
Ferrous Systems offer professional training for small teams:
- Just for you - groups of 5 to 12 people
- Spread over six half-days (6 x 4 hrs = 24 hrs)
- Our material is open-source
- Tailored to your needs and experience
- Talk to the team via https://ferrous-systems.com/contact/
How CheatSheets Work
The cheatsheets provided in this section are a bridge to help programmers coming from other languages learn Rust.
Here’s a brief example of how they work.
Example usage
Let’s say you want to create a cheatsheet for MyLang.
From the src directory, you type cargo xtask make-cheatsheet mylang where something like
# MyLang Cheatsheet
# Rust Fundamentals
## Overview
## Basic Types
## Installation
...
will be produced in rust-training/training-slides/src/mylang-cheatsheet.md.
Make sure to add that file under the CheatSheets section towards the bottom of SUMMARY.md.
Example Usage 2
Notice that headers map to our syllabus under rust-trianing/training-slides.
You must provide:
- An initial header of
# MyLang Cheatsheet - All the level 1 headers of our slide sections (
# Rust Fundamentals,# Applied Rust,# Advanced Rustand# No-Std Rustfor now), in order - At least the slides that our syllabus covers as second level headers, (e.g.,
## Overview,## Installation, etc) but additional slide sections are allowed
Good extra material
That is, this is allowed
# MyLang Cheatsheet
# Rust Fundamentals
## Overview
## Basic Types
## More Basic Types
## Basic Types Part 3
## Top 10 Myths MyLang Programmers Believe About Rust
## Installation
Bad missing material
But this is not allowed
# MyLang CheatSheet
# Rust Fundamentals
## Overview
## Basic Types
## MyLang Installation Specifics
Since the ## Installation header is missing from the # Rust Fundamentals block.
Bad missing header
Nor is this
# MyLang CheatSheet
## Overview
## Basic Types
## Installation
Since the # Rust Fundamentals header is missing from the first block.
Tooling
We have a tool that checks this compliance and you invoke it with
cargo xtask test-cheatsheet mylang
It will panic as soon as one of these invariants is not met.
We mainly suggest you avoid lines starting with # or ## in your cheatsheet as they will be picked up as headers and mess with parsing logic.
Note:
Which programming languages we support right now is a hardcoded number.
Adding a non-supported language requires some small additional logic to be handled when adding said cheatsheet under xtask/main.rs.
Cpp Cheatsheet
Rust Fundamentals
Overview
- In many ways, Rust is “Modern C++ best practices distilled into a new language”
- Smart pointers & Move semantics by default - explicit copy construction
- Everything is
constby default, opt-out withmut - Value Semantics & Data-oriented programming over complex object graphs
- Writing Safe Rust gets you the following benefits instantly:
- References are checked to be valid while in use
- running UBSAN, ASAN, THREADSAN and RAII analysis at compile time, without the performance penalty at runtime
- all code you depend on is also analyzed under the same constraints by the compiler
Installation
- Cargo is the package manager, not the compiler
- Like e.g. CMake, Cargo manages the compiler (rustc) and linker for you
- Uses the system linker
- Cargo does not have a separate “configure” stage like CMake
- It’s possible to use rustc directly, but very rarely needed
- rustc is the compiler
- LLVM is the default codegen backend
- experimental gcc backend has not yet stabilized
- CodeLLDB is a reliable debugger setup
- Rust comes with an auto-formatter (rustfmt) that should be used by default
- More consistent & reliable than e.g. clang-format
- Most code in the Rust ecosystem uses rustfmt style
Basic Types
Integers
- No
inttype, usei32instead - Use
usizewherever you would usestd::size_tin C++ - Integers in Rust cannot be used as booleans
- Use explicit
if my_number != 0instead ofif (my_number)
- Use explicit
Strings and arrays
charin Rust represents an actual Unicode Scalar Value (21-bit)- It cannot be used to represent plain “bytes” - use
u8/i8instead - For C/C++ FFI, use
std::os::raw::c_char
- It cannot be used to represent plain “bytes” - use
- Rust slice type
&[T]is comparable to combination ofT *pointer andsize_tarray size orstd::span. - Rust Strings and string slices
&stris comparable to combination of raw Cchar *pointer andsize_tstring size or C++std::string_view.- No nul-terminator! - Not compatible with C strings!
- Use
std::ffi::CStr/CStringfor C compatibility
- Use
- String is not Small String optimized, like in C++
- Try a drop in replacement like smallstr instead
- Array types (
[T;n]) are closer tostd::arraythan to C-style arrays- Length is always known, includes bounds checking, etc.
Miscellaneous
- Rust’s
println!semantics for non-numerics follow those ofsprintf, but with{}:%-10sto format a left aligned string padded to minimum 10 spaces becomes{:<10}%04to pad a number with zeros up to a width of 4 becomes{:04}, etc.
- Rust does not have user defined literals so you need a macro to make
let duration = 5_milliseconds;work in Rust - Raw pointers do exist but are rarely used
- References or smart pointers are preferred for added semantics and safety
Control Flow
Note that Rust does not split functions into declaration and corresponding definition. Usually a function is simply defined. Rust can hoist everything and does not use a text-based include system. There is no need to “forward-declare” anything.
The only way to “declare” a function is if the function is a foreign function.
Foreign functions are declared in an extern "..." block (usually extern "C").
This looks very similar to a declaration of an extern function in C/C++:
#![allow(unused)]
fn main() {
extern "C" {
fn cpp_function(value: i32) -> i32;
}
}if statements
- No ternary operator in Rust
cond ? a : bbecomesif cond { a } else { b }
match vs switch
matchcan match arbitrary types, not just integers- No fall-through and no
breakinmatchstatements- Use
"hello" | "world" => { ... }to match multiple things to the same result
- Use
_is equivalent todefault:matchis an expression likeif- evaluates to the value of the match arm
do-while in Rust
There is no do {} while(); loop in Rust.
It can be approximated with loop.
do {
do_thing();
} while(condition());
becomes
fn do_thing() {}
fn condition() -> bool { false }
loop {
do_thing();
if (!condition()) {
break;
}
}For loops
This C++ loop
const auto list = {1,2,3,4};
for (const auto &value: list) {
//...
}
is equivalent to this Rust loop
for value in &list {
//...
}Compound Types
Structs
No class type in Rust
- Use
structinstead - Only data members are declared inside the struct
- Member functions are declared outside the struct itself
- No inheritance, Rust uses composition and traits instead (foreshadowing 👻)
Construction
Construction in Rust is similar to aggregate initialization with designated initializers.
There are no constructors in Rust, use “static” member functions (Rust calls them “associated functions”) instead to uphold invariants before construction.
Enums
A Rust enum is most similar to a std::variant, it can hold data in each of the variants.
- By default, the compiler chooses an optimal layout
- Representation can be chosen explicitly with an attribute, e.g.
#[repr(u8)] - Enum values can only be of the declared variants - not any integer
- Cannot use enums as flags directly - use libraries like
bitflags
- Representation can be chosen explicitly with an attribute, e.g.
Ownership and Borrowing
Like C++, Rust fundamentally has three ways to pass ownership around:
- Moving the value
- Copying the data into a new value
- Handing out a reference to the value
The difference is in the defaults:
Taking something by-value in Rust by default means moving the value, not copying.
In comparison, copying is usually explicit with .clone() and references are explicit with & and &mut.
The second important difference is that a move does not leave an object behind; when moving out of an object, the moved-from object is no longer accessible.
References Cheat Sheet
| C++ | Rust | |
|---|---|---|
| Shared Reference Declaration | const std::string &arg | arg: &Stringor: arg: &str |
| Shared Reference Passing | foo(arg); | foo(&arg); |
| Exclusive Reference Declaration | std::string &arg | arg: &mut String |
| Exclusive Reference Passing | foo(arg); | foo(&mut arg); |
Rules around References/Borrowing
Rust’s references are similar to C++ references, but many rules/best-practices that C++ holds you responsible for are enforced at compile time:
- The referenced object must outlive the reference
- Only one exclusive (mutable) reference can exist at any given point in the program
- There can only be an exclusive reference, if there are no shared (
const) references
In C++, these were already good to adhere to, in Rust they are mandatory - a safe Rust program will not compile otherwise.
Copy trait
The Copy trait changes Rust’s default semantics back.
If a type implements Copy, it does not use move semantics, but copy semantics for assignment, passing by value, etc.
Copy types behave very closely to the C++ defaults, but without the ability to be moved (i.e. similar to pre-C++11).
Copy is usually only used for plain-old-data types that are cheap to copy.
RAII and Drop
Rust uses very similar RAII rules to C++. Instances that go out of scope are dropped (i.e. destructed).
The Drop trait acts like the destructor in C++, it can run code just before the instance is deleted.
Rust uses this to implement automatic clean up, similar to C++ (e.g. String, Vec, etc. also free their resources when they go out of scope).
Error Handling
Think of all functions as noexcept, unless they return a Result.
They may still panic!, thereby aborting the program, similar to a noexcept function that throws an exception.
However, panic! should be used rarely and documented well in public API.
Collections
Rust/C++ equivalents of common collections
| C++ | Rust | Notes |
|---|---|---|
std::array<T, n> | [T;n] | |
std::span<const T> | &[T] | |
std::span<T> | &mut [T] | |
std::vector<T> | Vec<T> | |
std::string_view | &str | Rust: UTF-8 |
const char * | &'static str | String literals only Rust: UTF-8 |
std::string | String | Rust: UTF-8 |
std::deque | VecDeque | Best match, slightly different internals |
std::unordered_map<K,V> | std::collections::HashMap<K,V> | |
std::map<K,V> | std::collections::BTreeMap<K,V> | Best match, slightly different internals |
std::unordered_set<T> | std::collections::HashSet<T> | |
std::set<T> | std::collections::BTreeSet<T> | Best match, slightly different internals |
Iterators
Iterators in Rust are self-contained. No need for an end iterator.
Most algorithms are implemented directly on the Iterator trait, not as separate functions.
So this C++ code:
auto numbers = std::vector{ 1, 2, 3 };
auto odd = std::find_if(
numbers.begin(),
numbers.end(),
[](const auto& number) { return number % 2 == 0; });
if (odd != numbers.end()) {
std::cout << *odd << std::endl;
}
becomes:
#![allow(unused)]
fn main() {
let numbers = vec![1, 2, 3];
let odd = numbers
.iter()
.find(|number| *number % 2 == 0);
if let Some(odd) = odd {
println!("{odd}");
}
}Imports and Modules
Rust modules work like C++ modules, not like #include files.
They export certain symbols (i.e. types/functions) under a given name.
They are not included as in-place text.
Modules are also important for scoping in Rust.
Unlike namespaces, modules and all items in them have their own visibility (e.g. pub or not).
Inside a module, all items can access each other, but items are only accessible from outside the module if they are pub.
You can think of everything inside the same module as being a friend (as in the C++ keyword friend) of everything else inside the same module.
e.g. this works in Rust:
#![allow(unused)]
fn main() {
mod config {
// private struct inside the module
struct Config {
// with private members
color_enabled: bool,
unicode_supported: bool,
}
// non-member function can still access the members inside the same module
fn is_color_enabled(config: &Config) -> bool {
config.color_enabled
}
}
// But this would not work, as it's outside of `mod config`:
// fn is_unicode_supported(config: &Config) -> bool {
// config.is_unicode_supported
// }
}Good Design Practices
Operator Overloading with Traits
Traits like PartialEq, PartialOrd, etc. are Rust’s way of operator overloading.
If a type implements the right trait, the corresponding operator (e.g. ==, <, etc.) is available for the type.
#[derive(...)], implements traits automatically (comparable to = default in C++).
You can also implement them manually.
See the std::ops module for details.
Applied Rust
Methods and Traits
A note on terminology: Rust uses “methods” where C++ developers might say “member functions”. Both concepts are similar, many Rust developers will know what is meant by “member function”.
In Rust, “static member functions” are called “associated functions”.
Method Receivers
Instead of member functions that are declared inside the class, Rust defines static/non-static methods inside impl T blocks:
Mappings from “member functions” to “methods”/“associated functions”:
| C++ | Rust | |
|---|---|---|
void my_fun() const;or: void my_fun() const &; | fn my_fun(&self) {} | |
void my_fun();or: void my_fun() &; | fn my_fun(&mut self) {} | |
Not a direct equivalent!void my_fun() &&; | fn my_fun(self) {} | Calling a selfmethod consumes the value, it is no longer available. |
static void my_fun(); | fn my_fun() {} |
Note: Instead of constructors, use associated functions that return -> Self.
Note: Methods can also be implemented on enum and union types, not just struct.
Name Resolution inside methods
Rust uses self instead of this.
The type of self depends on the declaration, and is usually a reference, not a pointer.
Inside method you must self. to access other methods/members explicitly.
Unlike C++, members/methods are not implicitly added to the scope.
So the C++ member function area:
struct Square {
float width() const { return m_width; }
float area() const {
return width() * width();
}
float m_width;
}
becomes:
#![allow(unused)]
fn main() {
struct Square {
width: f64
}
impl Square {
fn width(&self) -> f64 { self.width }
fn area(&self) -> f64 {
// Note: self is a &Square, not a *const Square
self.width() * self.width()
}
}
}Rust differentiates between self.width (the member) and self.width() (the method).
The name resolution only searches for methods/functions if the item is called with () and members/variables in the other cases.
Takeaway: No need to prefix members with m_ or similar!
Prefixing members is considered bad practice in Rust.
Advanced note: If a member is itself a callable function, force member resolution first, by enclosing the member access in parentheses:
(self.callable_member)();Interfaces without Inheritance
Rust is not a purely object-oriented language - only some object-oriented concepts are supported. Specifically, Rust does not support inheritance!
Then how to build abstractions in Rust? Use composition and interfaces instead.
Compound types like Structs/enums take care of the composition part of the equation. Traits represent the interface part.
Traits as interfaces
Traits are Rust’s way of declaring interfaces - they are (very roughly) comparable to (abstract) base classes without members.
Key differences:
- Traits don’t describe an “is a” relationship, but a “supports” relationship
- e.g.:
String“supports”Format
- e.g.:
- Implementing a trait do not change members/memory layout of the type
- By default: No
virtualdispatch- Rust prefers generics over dynamic dispatch
- Dynamic dispatch is opt-in by the trait user with
dyn
- Traits can be implemented on any type, not just
structtypes- Even reference/pointer types like
&SomeType,*const SomeType, etc.
- Even reference/pointer types like
Using Traits statically
Static trait dispatch is roughly equivalent to C++ templates with C++20 concepts.
Think of impl Trait as a concept that matches any type that implements Trait.
“Monomorphisation” is Rust speak for “template instantiation”.
Using Traits dynamically
Rust dyn vs. C++ virtual.
- Both use vtables for dynamic dispatch
- Key differences
dynis specified at the usage site, not the trait implementationdynapplies to the whole trait, not per-function- vtable is stored in the pointer itself (
&dyn Trait), not the struct type
- Takeaways
- Rust prefers static dispatch
- Typically faster at runtime - can inflate binary size
- Rust allows mixing static & dynamic dispatch depending on the usage
dynand destructiondynvtables in Rust automatically reference the correctDropimplementation- No need to worry about “virtual destructors”
Rust I/O Traits
Rust separates between buffered and unbuffered I/O.
Read/Write take care of the underlying unbuffered I/O.
BufReader/BufWriter can wrap any type that implements Read/Write and themselves also implement Read/Write.
In a sense the Read/Write define a basic interface, similar to C++ std::istream/std::ostream that other types implement.
Generics
Generics are basically C++ templates, but without the confusing pitfalls and terrible error messages (or at least a lot fewer of them).
For those reasons they are used in Rust widely and preferred over dynamic dispatch with dyn.
Type Inference
The Rust compiler is a lot smarter about type inference than the C++ compiler. In many cases, explicit type annotations are not needed, which can sometimes seem like magic.
To demystify this, it’s important to know that Rust type inference can work “backwards” and only needs the missing bit of information.
E.g. Rust can detect the type on a return value by going backwards from where the type is used to where it is created.
Anything that can be inferred automatically can be left out of the type declaration with _.
Example:
#![allow(unused)]
fn main() {
let numbers = vec![1, 2, 3, 4];
// No need to supply the item type of the `Vec`, leave out with `_`
let odds: Vec<_> = numbers
.into_iter()
.filter(|num| *num % 2 != 0)
// `.collect()` on this iterator can return anything that implements `FromIterator<i32>`.
// Rust determines to use `Vec<i32>` because the result is assigned to `odds`,
// which must be a `Vec` of something.
// Because only `Vec<i32>` implements `FromIterator<i32>`, it must be `Vec<i32>`.
.collect();
assert_eq!(odds, vec![1,3]);
}Adding Bounds
Rust trait bounds are roughly comparable to C++20 concepts. They require a type to implement the given traits to be used with the generic.
Important difference: The generic can only access functions/items that are declared in the bounds! The compiler checks the generic in isolation, not for each specialization individually!
C++ template type-checking:
- Check any concepts
- Insert the type into the template
- Type check (may still fail)
Rust generic type check:
- Type check the generic with the given bounds
- Check that the concrete type actually implements the bounds
- Insert the type into the template (can no longer fail)
This re-ordering means error messages are much cleaner, as the generic itself is checked for correctness, not every concrete instantiation.
Lifetimes
In C++ documentation you will often find important notes about invalidation of references/iterators, etc.
An example from cppreference.com:
std::vector<T,Allocator>::clear
void clear();Erases all elements from the container. After this call, size() returns zero.
Invalidates any references, pointers, and iterators referring to contained elements. Any past-the-end iterators are also invalidated
Catch the note about invalidation of references/pointers and iterators?
This documentation isn’t just a minor detail, it is vitally important to the correctness of the program!
Any program that uses said references/pointers or iterators after calling clear() is immediately undefined behavior!
In C/C++ ensuring this does not happen at compile time, is almost impossible 😢.
Lifetimes are here to help! They give Rust a way to express these relationships between references and whatever they reference as a language construct. So instead of documenting these important relations as text and hoping people read the documentation, lifetimes allow Rust to enforce them at compile time!
You will probably recognize many of the issues that the Rust compiler prevents as common pitfalls in C/C++.
Cargo Workspaces
In Rust, the smallest compilation unit is a whole crate, not just one source file.
At the time of writing (05/2025), the Rust compiler is largely single-threaded. Adding more crates to your build therefore tends to speed up compilation by allowing Cargo to compile multiple compilation units in parallel.
In general, splitting your project into multiple crates is very common and good practice in Rust. Package management is considerably easier compared to C++, do not be afraid to split your project into multiple smaller packages.
Heap Allocation (Box and Rc)
Heap allocation in Rust is almost always done via smart pointers.
Rust smart pointers are very similar to the C++ equivalents, but cannot be null!
If you need a nullable smart pointer use them together with Option<T>, e.g. Option<Box<T>>.
| C++ | Rust |
|---|---|
std::unique_ptr<T> | Box<T> |
std::shared_ptr<T> | std::sync::Arc<T>( std::rc::Rc<T> if single-threaded) |
std::weak_ptr<T> | std::sync::Weak<T>( std::rc::Weak<T> if single-threaded) |
Arc and sync::Weak use atomic reference counting (like std::shared_ptr/std::weak_ptr).
Rc and rc::Weak are faster, but limited to a single thread.
Shared Mutability (Cell, RefCell, OnceCell)
With mutability, Rust follows broadly the same practices that you should follow in C++, but Rust actually enforces the rules.
Two mutable references can never exist at the same time! It is impossible in safe Rust, and is UB in unsafe Rust.
Shared (or “interior”) mutability usually ensures at runtime that only a single mutable reference can exist at the same time, even if it’s not possible to prove at compile time.
Thread Safety (Send/Sync, Arc, Mutex)
Mutexes
In C++, you have to manually ensure that you lock the right mutex for the right data.
A Rust Mutex<T> can be thought of as a std::mutex together with some arbitrary data of type T.
The data T is owned and protected by the mutex.
Mutex::lock returns a MutexGuard, which is similar to a std::lock_guard.
Note that it does not include a deadlock avoidance algorithm like std::scoped_lock!
MutexGuard dereferences (mutably) to the inner T data, thereby granting mutable access.
Arc vs. shared_ptr
Arc is Rust’s std::shared_ptr and also uses atomics for thread-safe reference counting.
In C++ you must take care to never mutate a shared_ptr from multiple threads, as the shared_ptr itself is not thread-safe, only the internal reference counting.
Arc is implemented the same way, but as it is impossible to gain two mutable references to the same Arc in Rust, you do not need to worry about this.
Atomics
Atomics in Rust are pretty much the same as in C++. However, they are not generic types, but multiple concrete types.
So instead of std::atomic<int>, use std::sync::atomic::AtomicI32, etc.
Rust atomics also include some helper methods for easier compare-exchange loops.
For example: AtomicI32::fetch_update.
Closures and the Fn/FnOnce/FnMut traits
Fn/FnMut/FnOnce are traits, not concrete types.
They are Rusts way of expressing an operator() implementation.
| C++ | Rust | |
|---|---|---|
T operator()(...) const | Fn(...) -> T | Needs & to call |
T operator()(...) | FnMut(...) -> T | Needs &mut to call |
Not a direct equivalent!T operator()(...) && | FnOnce(...) -> T | Needs ownership to call |
To store any callable type, similar to std::function<(...)>, use Box<dyn Fn(...)> or one of the other traits.
Note: Box<dyn Fn...> is rarely needed - prefer using generics with Fn/FnMut/FnOnce trait bounds.
Capturing data in closures
Closures are the Rust equivalent of C++ lambdas. Unlike C++, Rust does not have an explicit capture list. By default, every outside variable is captured by reference.
Therefore |arg| { ... } is the Rust equivalent of [&](auto arg) { ... }.
To capture everything by-value (e.g. by move), add the move keyword (e.g. move || { ... }).
If you need to specify explicitly which types to capture by-value/by-copy/by-reference, use move together with an added scope.
e.g. this C++ capture list:
auto by_move = std::string("Hello Move");
auto by_copy = std::string("Hello Copy");
auto by_reference = std::string("Hello Reference");
auto lambda = [by_copy, by_move=move(by_move), &by_reference]() {
// ...
};
becomes:
#![allow(unused)]
fn main() {
let by_value = "Hello Move".to_owned();
let by_copy = "Hello Copy".to_owned();
let by_reference = "Hello Reference".to_owned();
// create a scope for the closure
let closure = {
let by_reference = &by_reference; // shadow with a reference
// let by_reference = &mut by_reference; // or mutable reference
let by_copy = by_copy.clone(); // or explicit clone
// The closure now captures the references by move, not the values themselves
move || {
// ...
}
};
}Spawning Threads and Scoped Threads
Advanced Rust
Advanced Strings
String is Rust’s equivalent to std::string. &str is closest to a std::string_view.
Key differences:
String&&strare guaranteed to be valid UTF-8- Don’t assume ASCII characters inside
- Iterating over the bytes is usually not what you want!
- Use
chars()to iterate over the characters
String&&strare not nul-terminated!- Do not use
String/&strdata asconst char*when calling C functions! - Use CString/CStr instead, they are nul-terminated
- Do not use
charin Rust is not one byte!- It actually represents a “Unicode character”
- Specifically one “Unicode scalar value”
Building Robust Programs with Kani
Dealing with Unwrap
Debugging Rust
Rust emits a very similar binaries and debug information to C/C++ binaries.
=> Most C/C++ tooling will work for Rust debugging/profiling to some extent
Tools usually have to add Rust support for:
- Syntax highlighting Rust code
- Symbol demangling
- Layout information for instance introspection
- Pretty-printing for common types (e.g. String)
Some common C/C++ tools that support Rust out-of-the-box:
- Hotspot - Perf GUI
- Heaptrack - Memory Usage Analyzer
- Valgrind - Memory Safety Analyzer
- rr - Reverse Debugger
- Sanitizers - Note: Needs nightly Rust at the moment
Deconstructing Send, Arc, and Mutex
Dependency Management with Cargo
Cargo uses Toml files to describe packages. These files are not “executed” like CMake files, they provide static data.
If you need to “compute” something at build time, Cargo allows you to run Rust scripts that can configure certain parts of the build process (e.g. to discover C libraries to link, etc.). No need to learn a second programming language for your build system.
Deref Coercions
Deref is comparable to a mix of operator-> and inheritance.
The way it works is basically like an operator-> overload, but instead of overloading the -> operator, you can directly overload method and field access (.).
Deref and DerefMut are therefore usually implemented on smart pointer types (e.g. Box, Rc, Arc).
This is a convenient way to “inherit” behavior by using composition.
Instead of inheriting from a type T, you store an instance of T inside the struct and add Deref and DerefMut implementations that dereference to the T value.
From the outside it almost looks like the outer types supports all the same operations as T, similar to inheritance in C++.
A prominent example of this is String, which “inherits” all methods from str by dereferencing to it.
Design Patterns
Notes on Cloning
These Design guidelines recommend using .clone() in many cases.
You may worry that this is slow, especially compared to C++.
However, remember that in C++ copy-construction is often the default!
For example, think of all constructors that take const std::string& - these usually end up copying the whole string!
So even if you use .clone() liberally in Rust, your program will likely still clone less often than a similar C++ program!
In Rust move-semantics are the default, if you take a String by-value, it does not incur a copy operation.
Takeaway: Don’t be afraid of .clone(), C++ clones all the time anyway, your Rust code will probably still end up cloning less often that C++.
From<> and Into<>
Like with .clone(), Rust is explicit whenever a conversion occurs.
A From<> implementation is similar to an explicit conversion constructor in C++.
Documentation
Rustdoc is the default in Rust, please do use it.
Rustdoc uses Markdown for documentation.
Unlike Doxygen, documentation is largely free-form and does not use “tags” like @param/@return/etc.
This style of documentation is less repetitive - the function name and signature should already be descriptive. Use the documentation to provide important context, not just repeat the list of arguments.
Drop, Panic and Abort
Rusts concept of RAII is very similar to C++ and intuition about both is largely the same.
A resource is initialized when it is acquired and cleaned up when it is dropped (Rust terminology for “destructed”).
The Drop trait is akin to the C++ destructor.
Like in C++, the members inside a struct/enum run their drop function after the drop function of the struct/enum itself.
Because of the way Rust handles dynamic dispatch, there is no such thing as a virtual function.
Destructors do not have to be virtual and will work correctly with dynamic dispatch out of the box.
Panic vs. Exceptions
Even though a panic internally works similarly to a C++ exception, do not use panics for recoverable errors!
Think of panic as something that is so critical that aborting the program immediately is a valid response to the error (even if it may unwind in reality).
Dynamic Dispatch
Trait Objects are the closest thing Rust has to “virtual inheritance”.
When used via a trait object, the trait is comparable to an abstract base class. Any type that implements the trait “inherits” from the “abstract base class”.
Dynamic Dispatch via a Trait object differs to inheritance in where the vtable is referenced. In C++, the vtable is referenced inside the struct/class instance. In a trait object, the vtable is referenced inside the (smart) pointer to the struct/enum.
For this reason the pointer itself is the trait object, not the struct that implements the trait!
This also means a dyn pointer/reference is actually two pointers:
- Pointer to the data
- Pointer to the vtable
#![allow(unused)]
fn main() {
use std::{fmt::Display, mem::size_of};
assert_eq!(size_of::<&dyn Display>(), 2 * size_of::<&String>());
assert_eq!(size_of::<*const dyn Display>(), 2 * size_of::<*const String>());
assert_eq!(size_of::<Box<dyn Display>>(), 2 * size_of::<Box<String>>());
}Because dynamic dispatch can only happen via a trait object, the compiler always knows when to use dynamic or static dispatch.
In Rust, it is therefore not necessary to specify something like “virtual” on each function, all functions can be used with dynamic dispatch, as long as the trait is dyn-compatible.
If the type is not dyn, Rust uses static dispatch automatically!
Macros
Disclaimer: Rust macros are way saner than C preprocessor macros!
Some important differences:
- Are always explicitly invoked with
my_macro!or#[my_macro]- Cannot accidentally be invoked 🥳
- Don’t just do text replacement, but operate on “tokens”
- Closer, safer integration with the compiler
- Operate somewhat like “compiler plugins/extensions”
For these reasons, Rust macros are a lot saner and easier to use. Then can and will still rewrite your code, so they should still be used sparingly.
Property Testing
Rust Projects Build Time
At the time of writing (May 2025), the Rust compiler is still largely single-threaded.
In Rust, the compilation unit is a whole crate, not a single file! To achieve parallelization, Cargo can schedule multiple crates to be compiled at the same time, as long as they are independent of each other.
Takeaway: Do not be afraid to split your project into more crates (and therefore compilation units) - this can improve compile time.
Send and Sync
Send and Sync are like lifetimes in the sense that they allow Rust to encode and enforce properties of types that have always existed, but could only be documented in plain text, not in the language itself (at least in C++).
Serde
Testing
The stdlib
Note that in Rust Zero-sized types are actually 0 bytes in size, they do not change the size or alignment of your type. In C/C++, even an empty struct has a non-zero size.
Using Cargo
Almost always you will use Cargo to work on Rust projects.
It is a front for “all things Rust” and will delegate many tasks to other tools, like the Rust compiler (rustc), clippy, etc. The Rust ecosystem is far more integrated around Cargo than the C++ ecosystem is around any build system or even compiler.
Cargo’s build system is intentionally more limited than e.g. CMake. It focuses on doing one thing and doing it well: Compile Rust code and manage Rust dependencies. This has the advantage that almost all crates adhere to what Cargo expects and are therefore easy to understand and include in your project.